pytorch-optimizer

项目描述
torch-optimizer






torch-optimizer – 与PyTorch兼容的优化模块的优化器集合。
简单示例
import torch_optimizer as optim
# model = ...
optimizer = optim.DiffGrad(model.parameters(), lr=0.001)
optimizer.step()安装
安装过程很简单,只需
$ pip install torch_optimizer
文档
引用
请引用优化算法的原始作者。如果您喜欢这个包
@software{Novik_torchoptimizers,
title = {{torch-optimizer -- collection of optimization algorithms for PyTorch.}},
author = {Novik, Mykola},
year = 2020,
month = 1,
version = {1.0.1}
}
或者使用github功能:“引用此仓库”按钮。
支持的优化器
https://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf |
|
https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization |
可视化
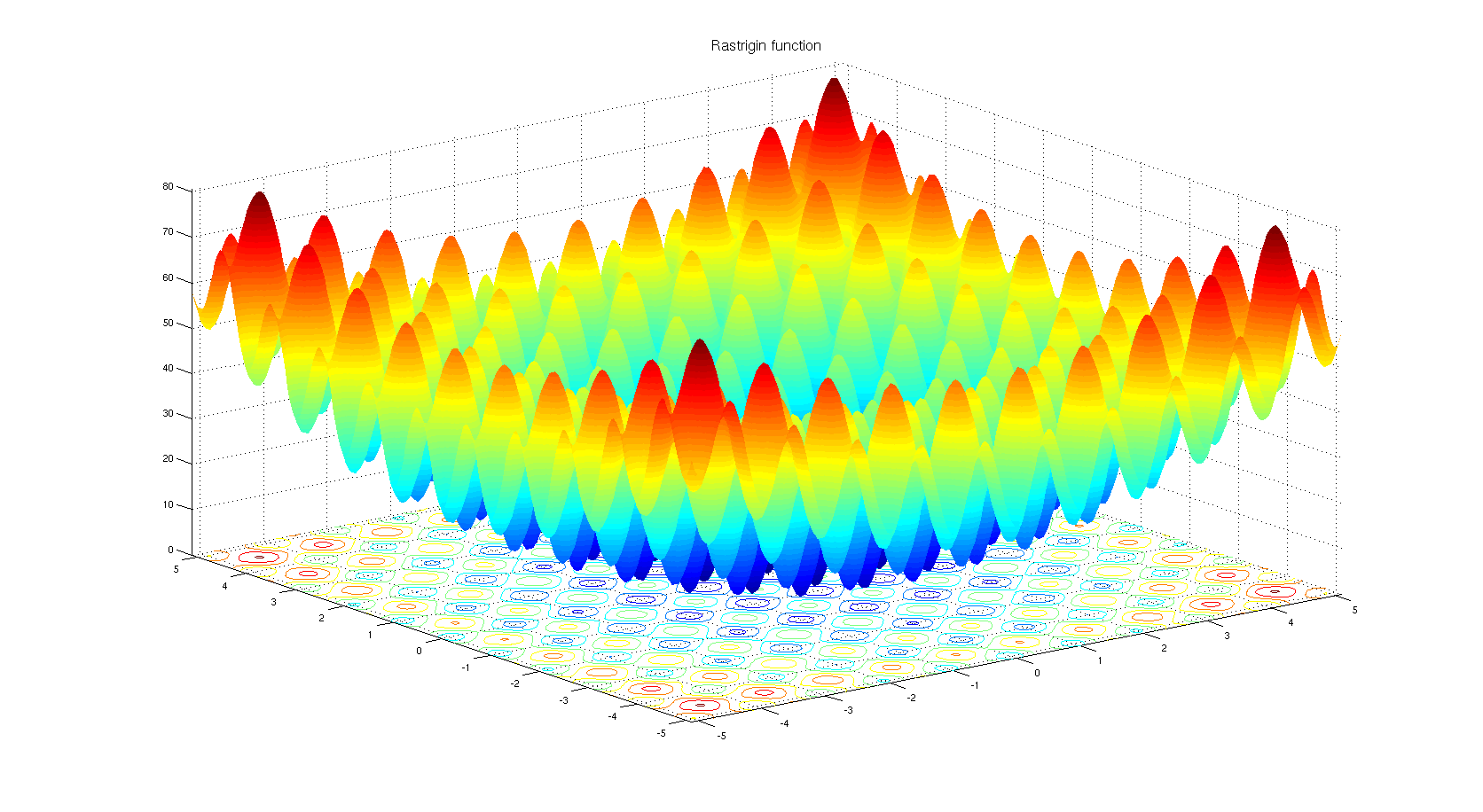
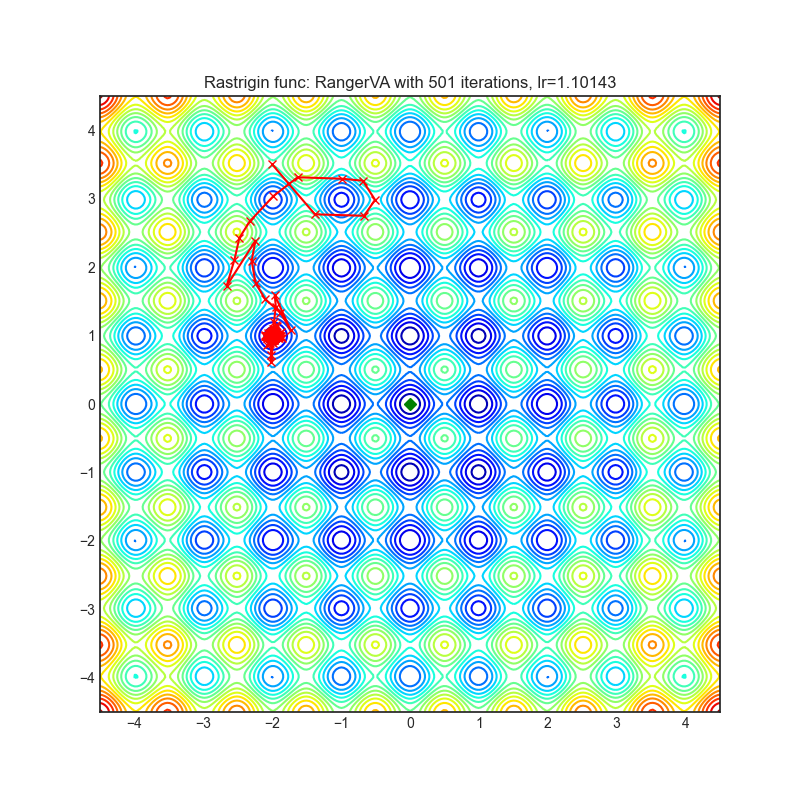
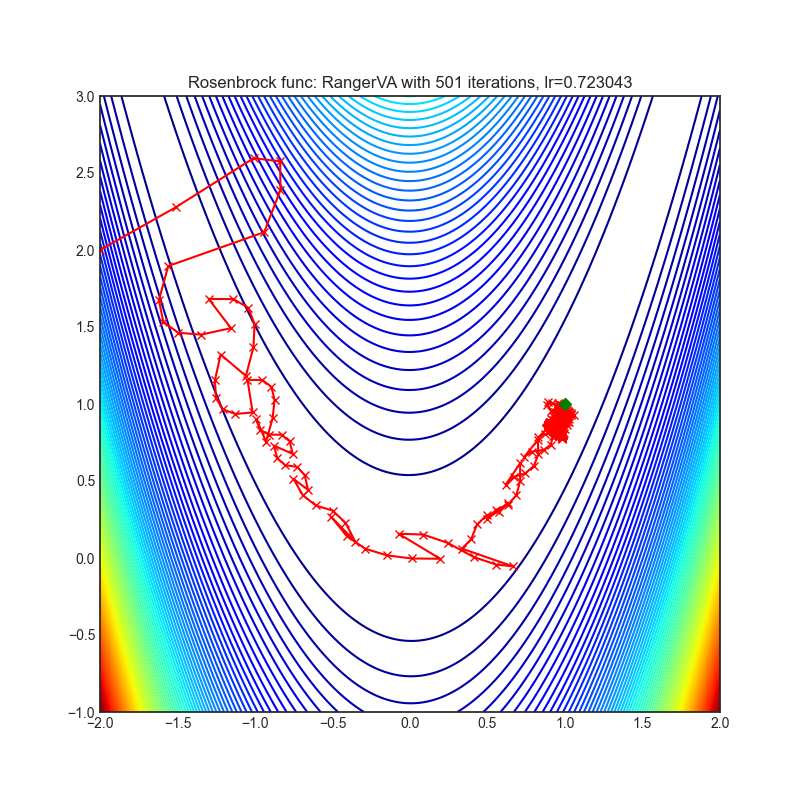
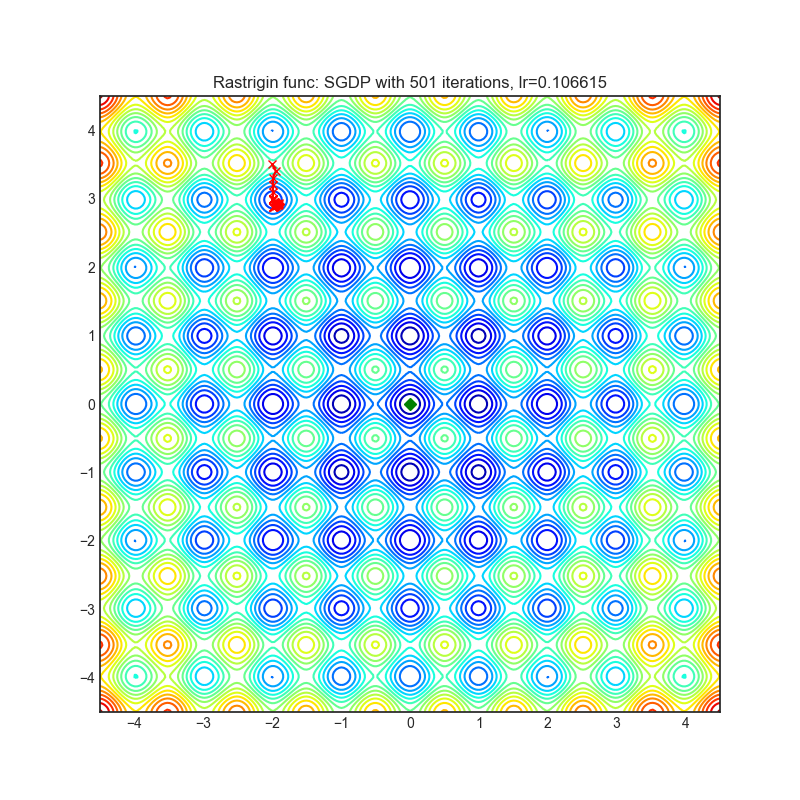
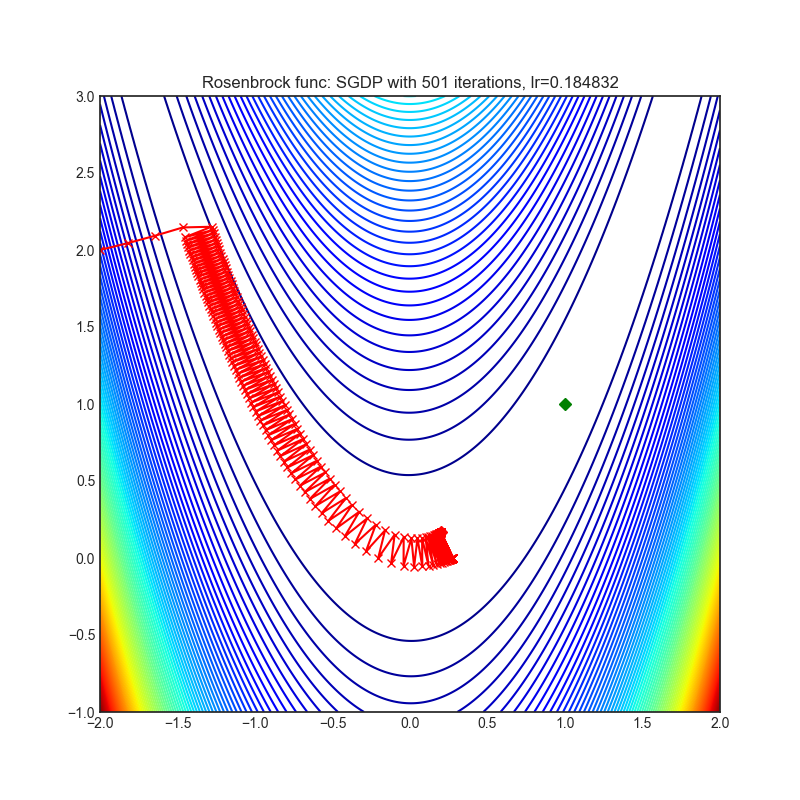
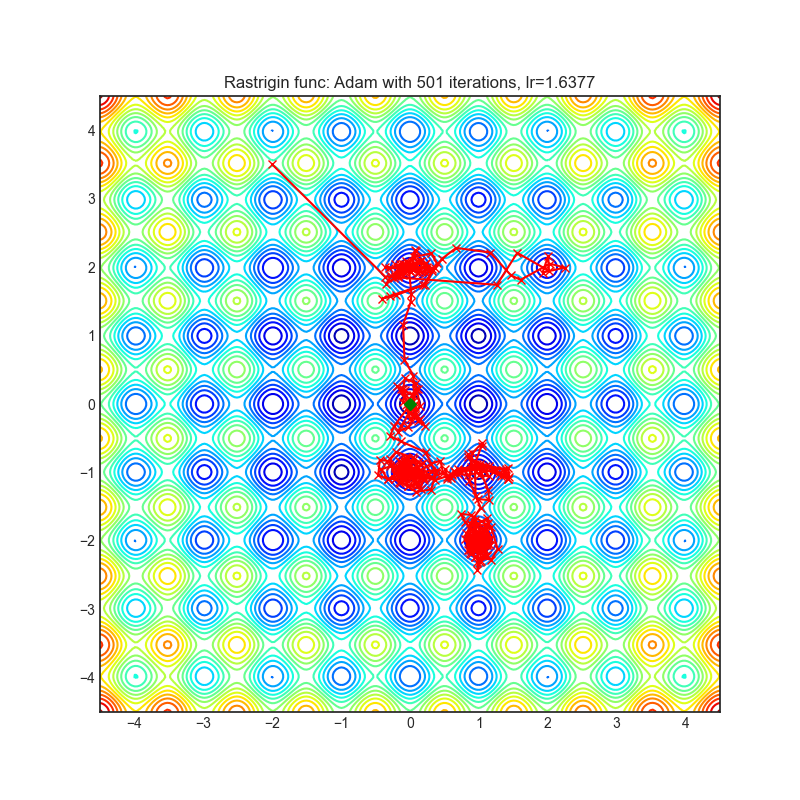
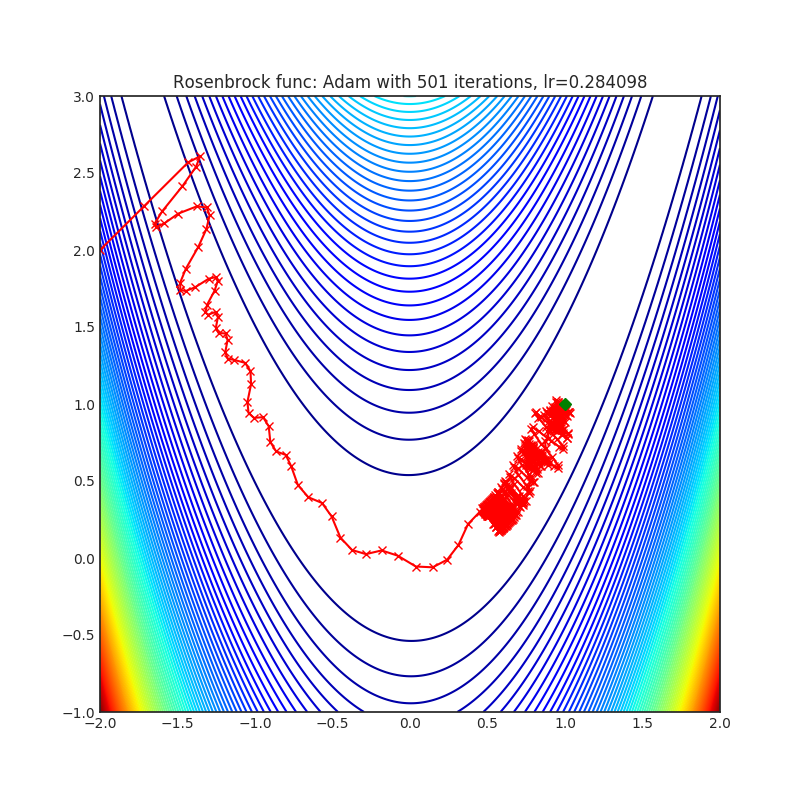
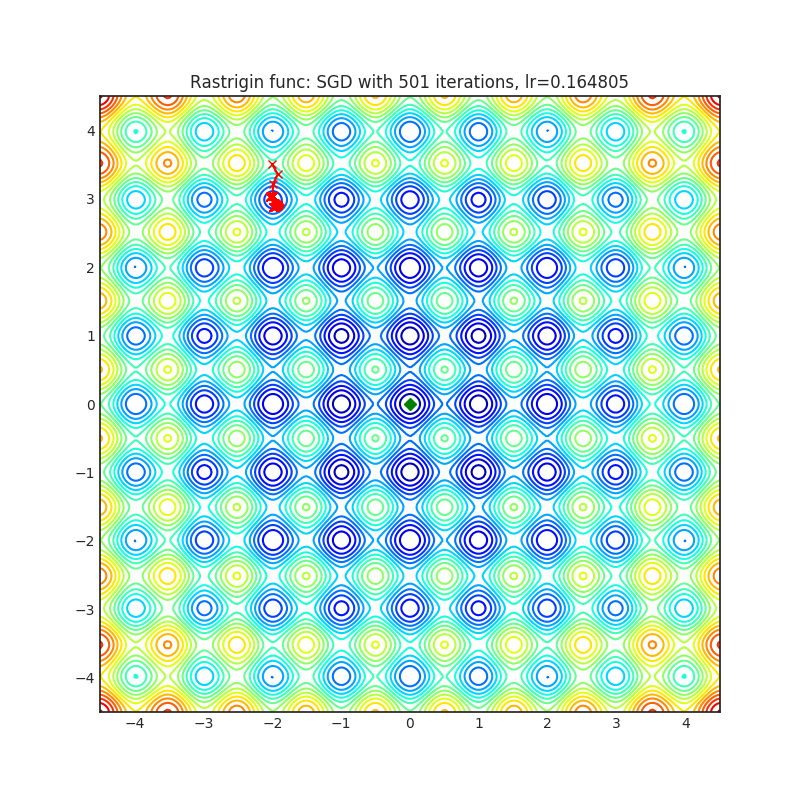
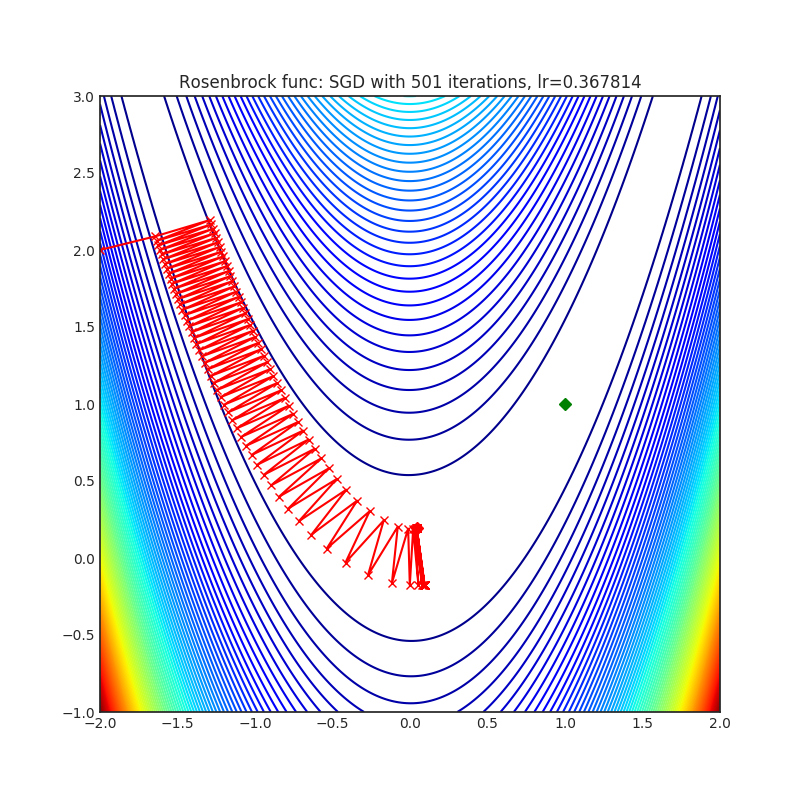
可视化帮助我们了解不同算法如何处理诸如鞍点、局部最小值、山谷等简单情况,并可能对算法的内部工作提供有趣的见解。选择了Rosenbrock和Rastrigin 基准函数,因为
Rosenbrock(也称为香蕉函数)是一个非凸函数,它有一个全局最小值(1.0, 1.0)。全局最小值位于一个长而窄的抛物线形状的平坦山谷中。找到山谷是微不足道的。然而,要收敛到全局最小值是困难的。优化算法可能会非常关注一个坐标,并且很难跟随相对平坦的山谷。

Rastrigin函数是一个非凸函数,在(0.0, 0.0)处有一个全局最小值。由于它的搜索空间很大以及它的局部最小值数量很多,找到这个函数的最小值是一个相当困难的问题。
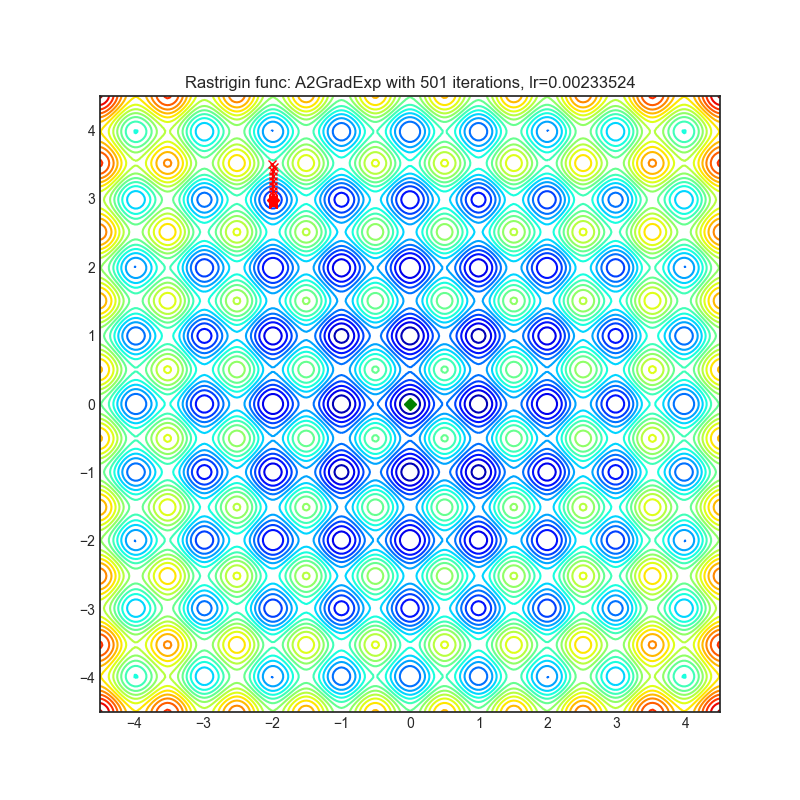
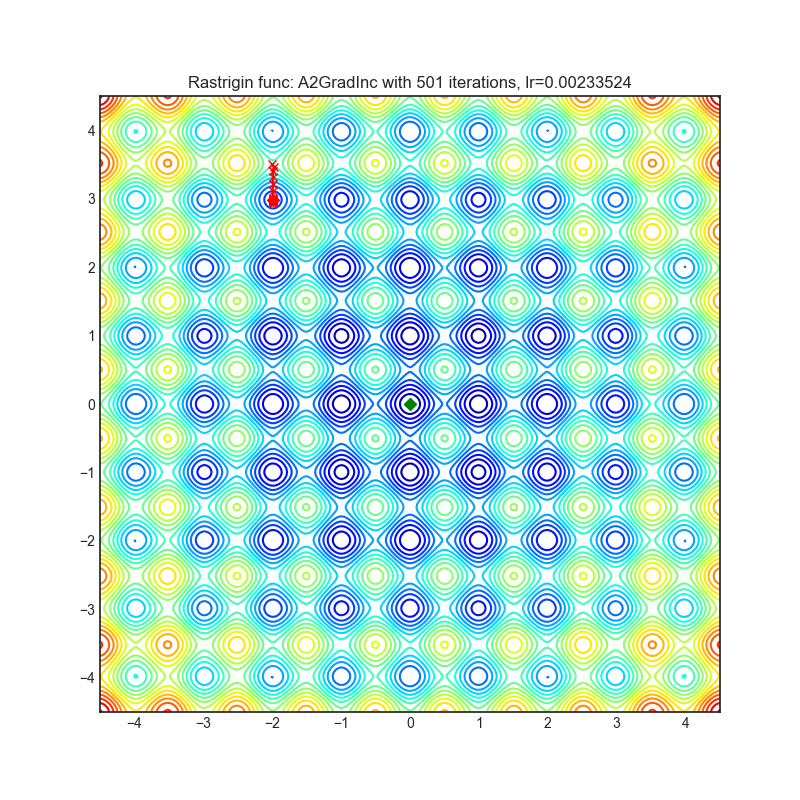
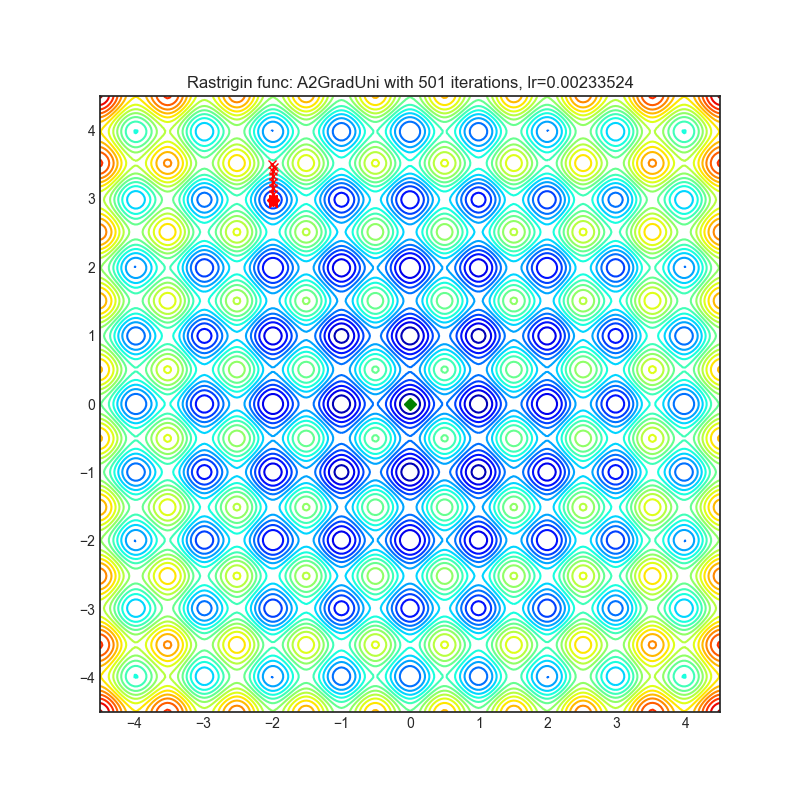
每个优化器执行 501 个优化步骤。学习率是由超参数搜索算法找到的最佳值,其余的调整参数是默认值。很容易扩展脚本并调整其他优化器参数。
python examples/viz_optimizers.py警告
不要根据可视化选择优化器,优化方法具有独特的属性,可能针对不同的目的进行定制,或者可能需要显式的学习率计划等。最好的方法是尝试使用特定的优化器来处理您的问题,并看看是否能提高分数。
如果您不知道要使用哪个优化器,可以从内置的SGD/Adam开始,一旦训练逻辑准备好并建立了基线分数,就可以交换优化器并看看是否有任何改进。
A2GradExp
|

|
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradExp(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
rho=0.5,
)
optimizer.step()论文: 最优自适应和加速随机梯度下降(2018)[https://arxiv.org/abs/1810.00553]
A2GradInc
|

|
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradInc(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
)
optimizer.step()论文: 最优自适应和加速随机梯度下降(2018)[https://arxiv.org/abs/1810.00553]
A2GradUni
|
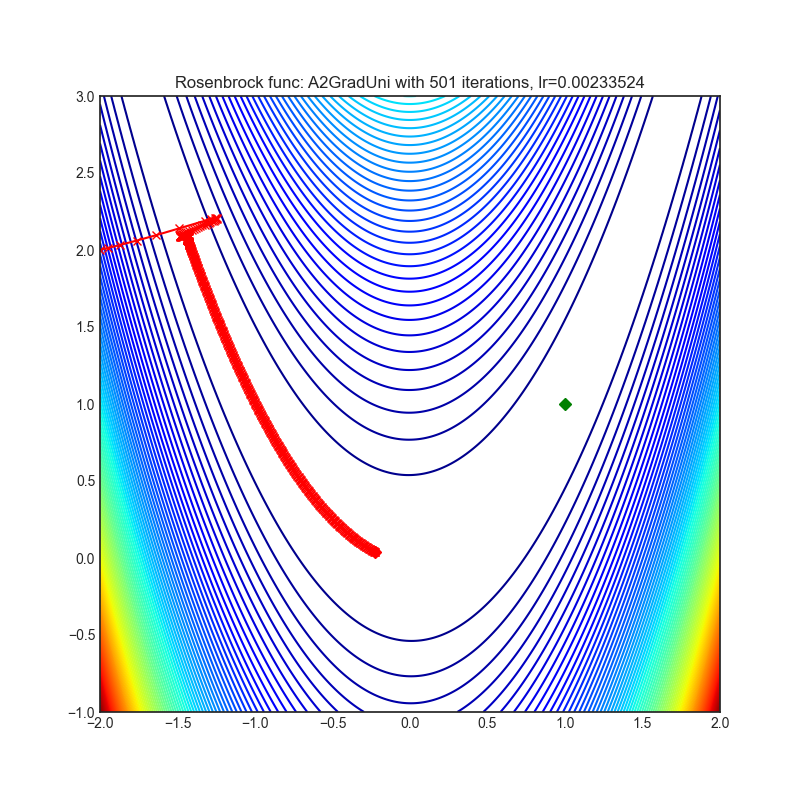
|
import torch_optimizer as optim
# model = ...
optimizer = optim.A2GradUni(
model.parameters(),
kappa=1000.0,
beta=10.0,
lips=10.0,
)
optimizer.step()论文: 最优自适应和加速随机梯度下降(2018)[https://arxiv.org/abs/1810.00553]
AccSGD
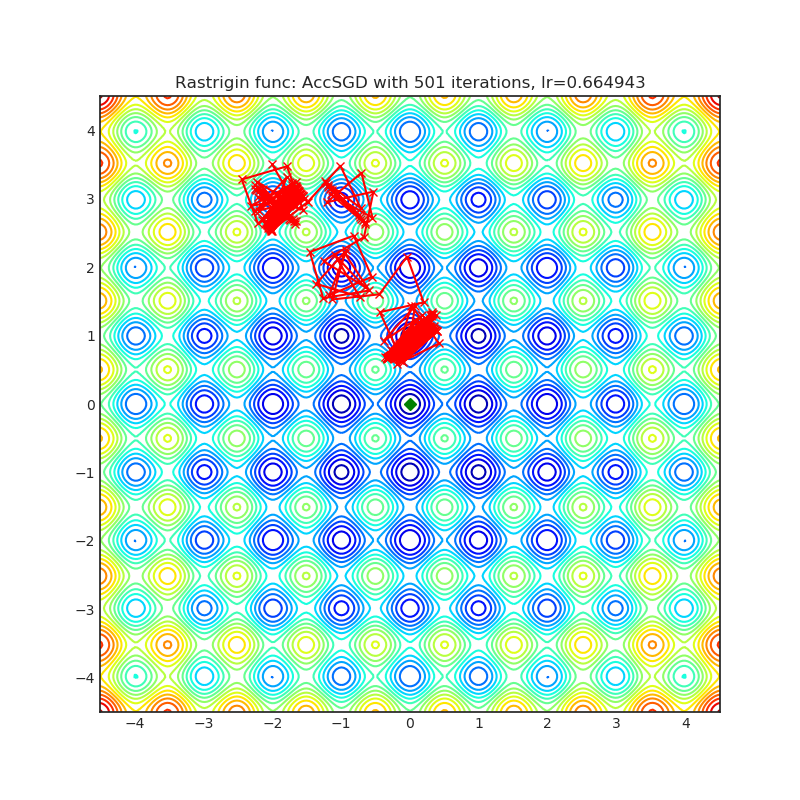
|
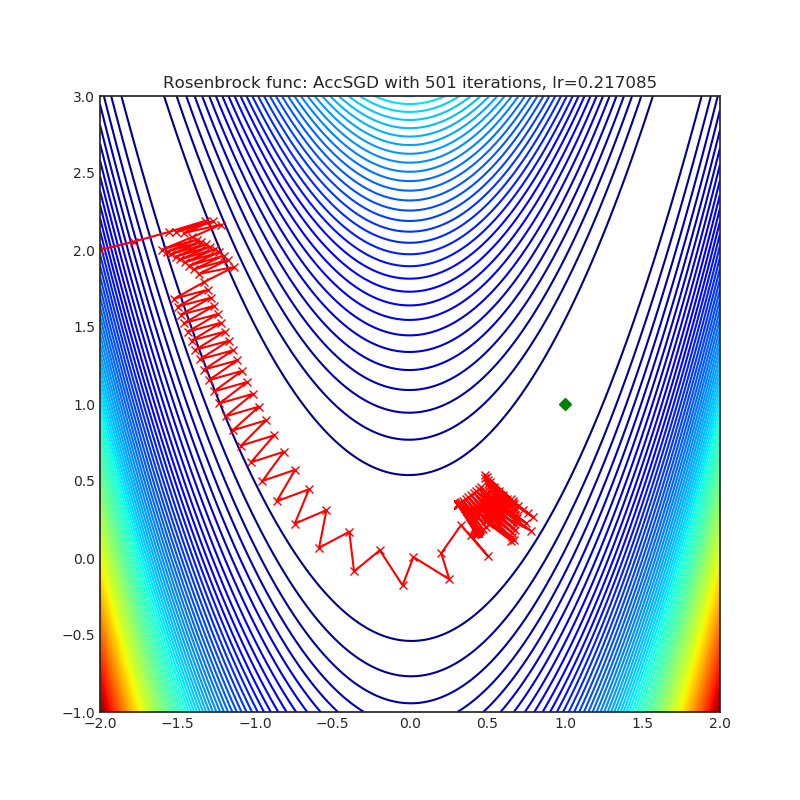
|
import torch_optimizer as optim
# model = ...
optimizer = optim.AccSGD(
model.parameters(),
lr=1e-3,
kappa=1000.0,
xi=10.0,
small_const=0.7,
weight_decay=0
)
optimizer.step()论文: 关于现有动量方案在随机优化中的不足(2019)[https://arxiv.org/abs/1803.05591]
AdaBelief
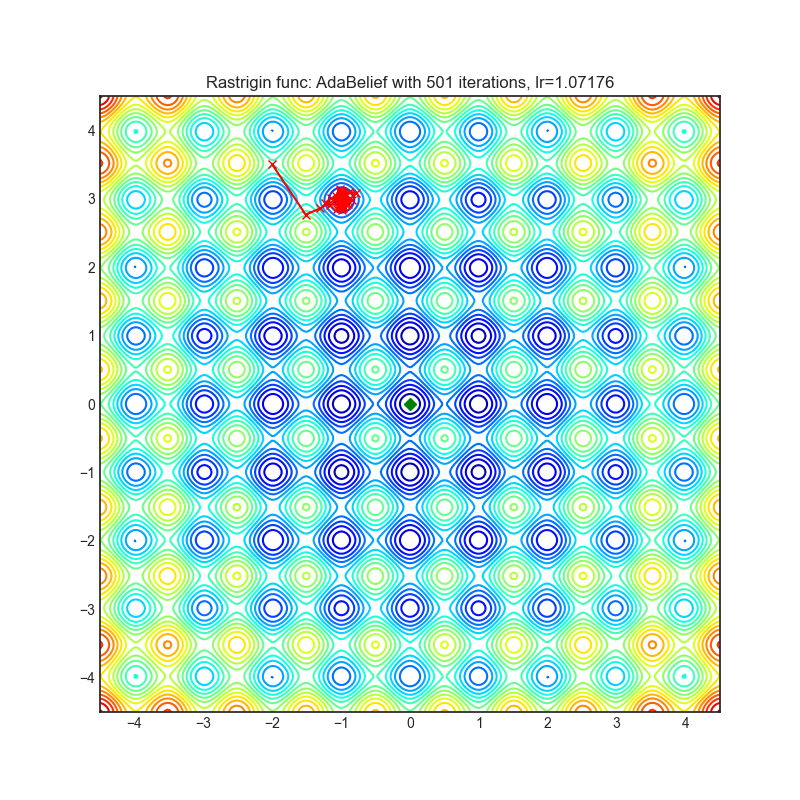
|
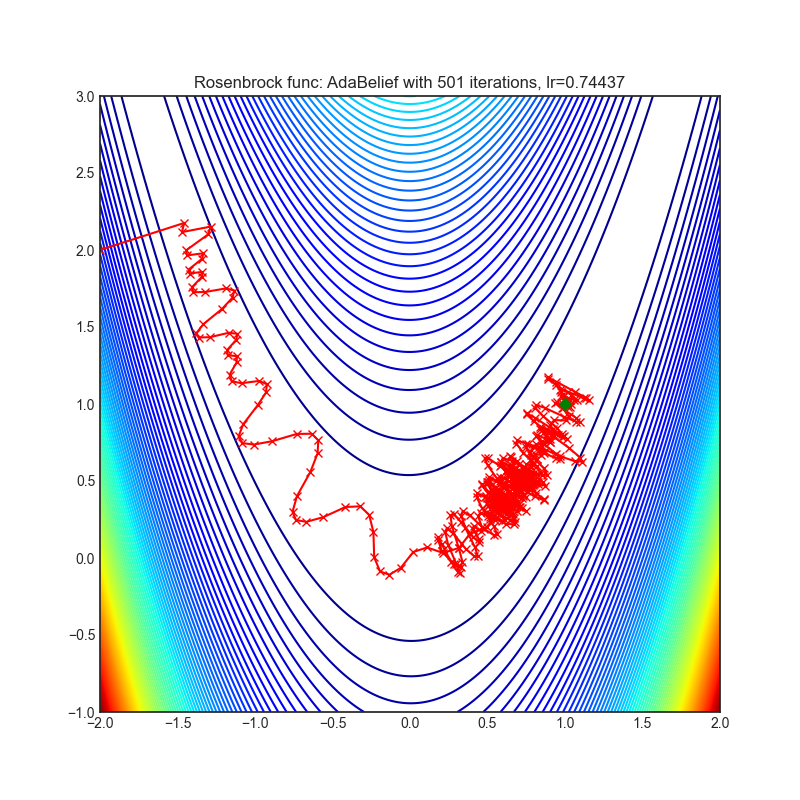
|
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaBelief(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-3,
weight_decay=0,
amsgrad=False,
weight_decouple=False,
fixed_decay=False,
rectify=False,
)
optimizer.step()论文: AdaBelief优化器,通过观察梯度的信念来调整步长(2020)[https://arxiv.org/abs/2010.07468]
AdaBound

|
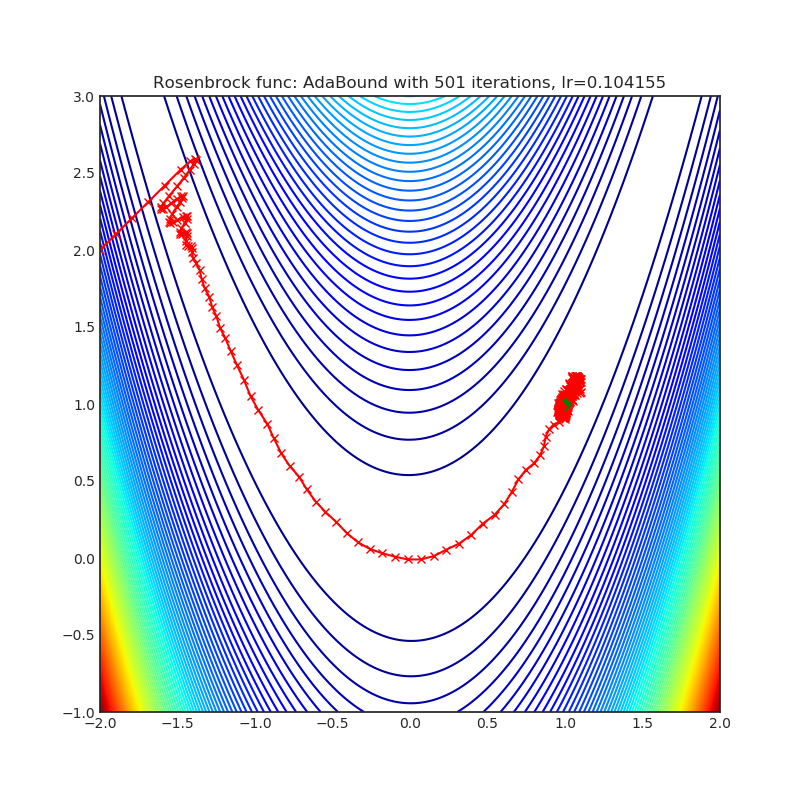
|
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaBound(
m.parameters(),
lr= 1e-3,
betas= (0.9, 0.999),
final_lr = 0.1,
gamma=1e-3,
eps= 1e-8,
weight_decay=0,
amsbound=False,
)
optimizer.step()论文: 具有动态学习率界限的自适应梯度方法 (2019) [https://arxiv.org/abs/1902.09843]
AdaMod
AdaMod方法通过自适应和动量上界限制自适应学习率。动态学习率界限基于自适应学习率的指数移动平均值,这有助于平滑意外的较大学习率并稳定深度神经网络的训练。
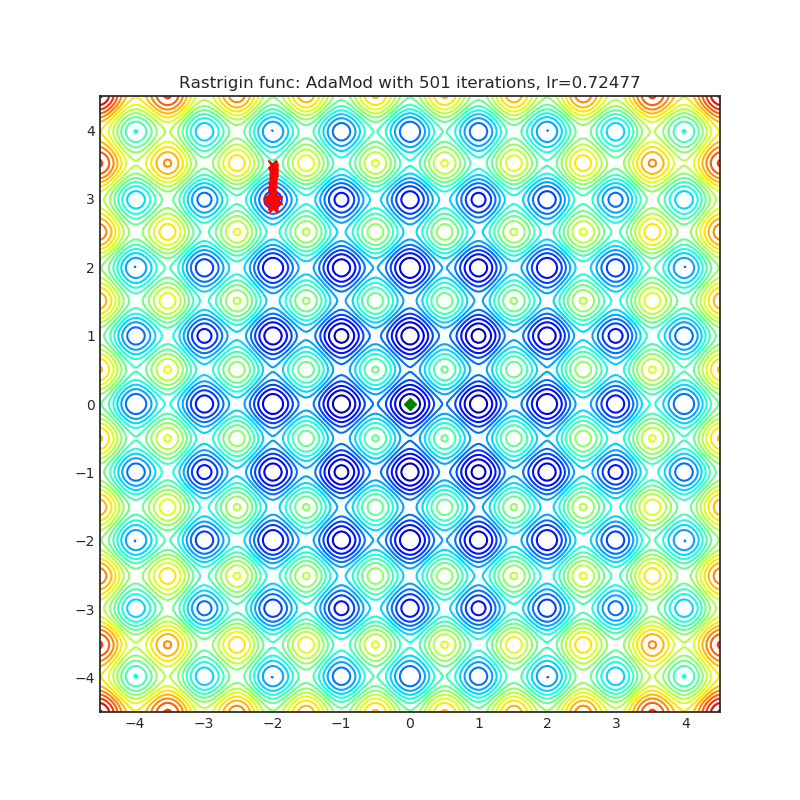
|
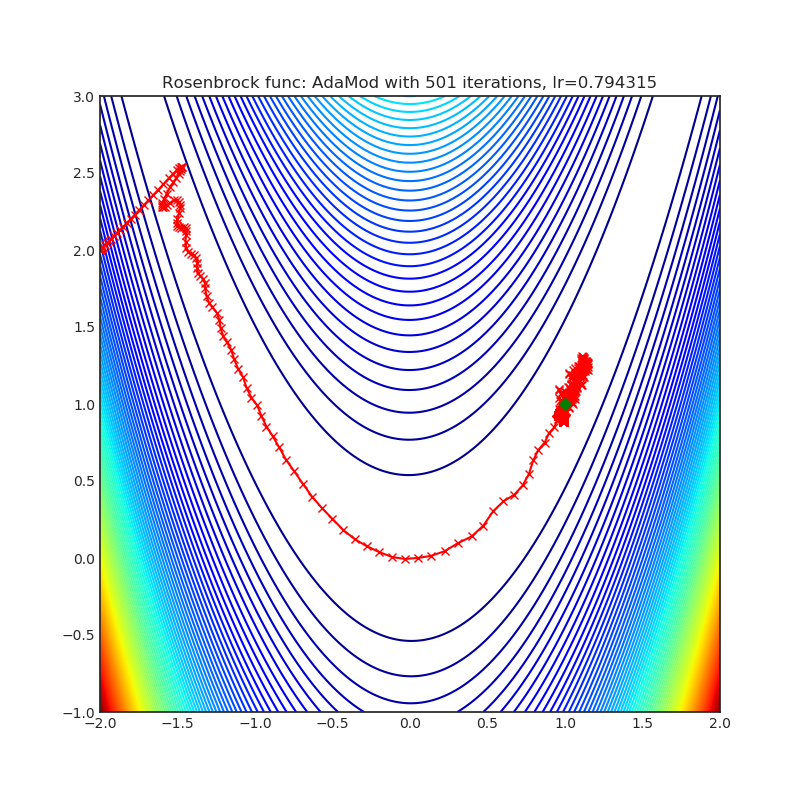
|
import torch_optimizer as optim
# model = ...
optimizer = optim.AdaMod(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
beta3=0.999,
eps=1e-8,
weight_decay=0,
)
optimizer.step()论文: 随机学习中的自适应和动量界限方法 (2019) [https://arxiv.org/abs/1910.12249]
Adafactor
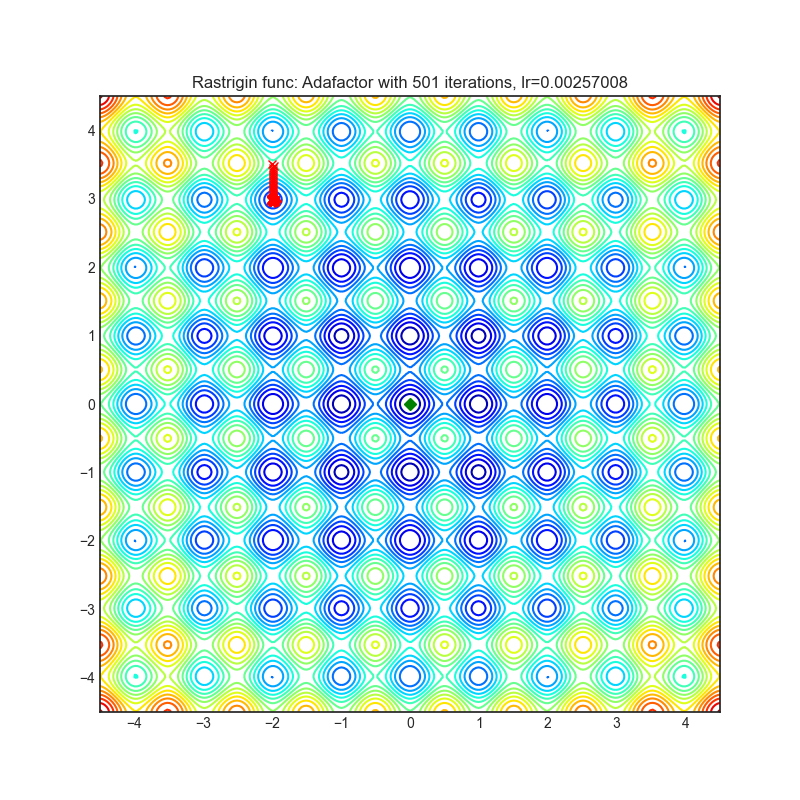
|
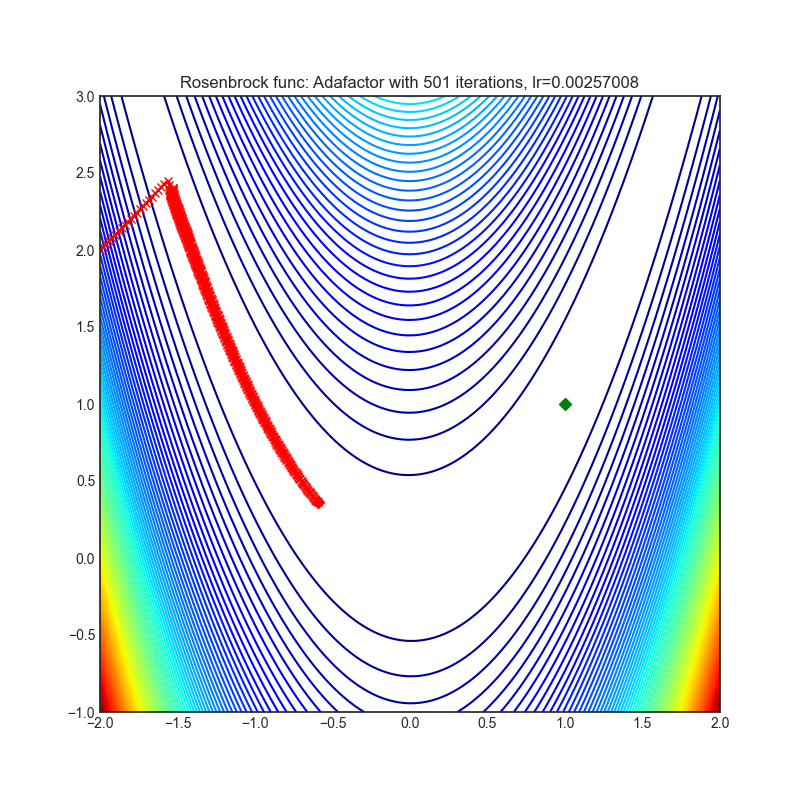
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Adafactor(
m.parameters(),
lr= 1e-3,
eps2= (1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
scale_parameter=True,
relative_step=True,
warmup_init=False,
)
optimizer.step()论文: Adafactor: 具有亚线性内存成本的自适应学习率 (2018) [https://arxiv.org/abs/1804.04235]
参考代码: https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py
Adahessian
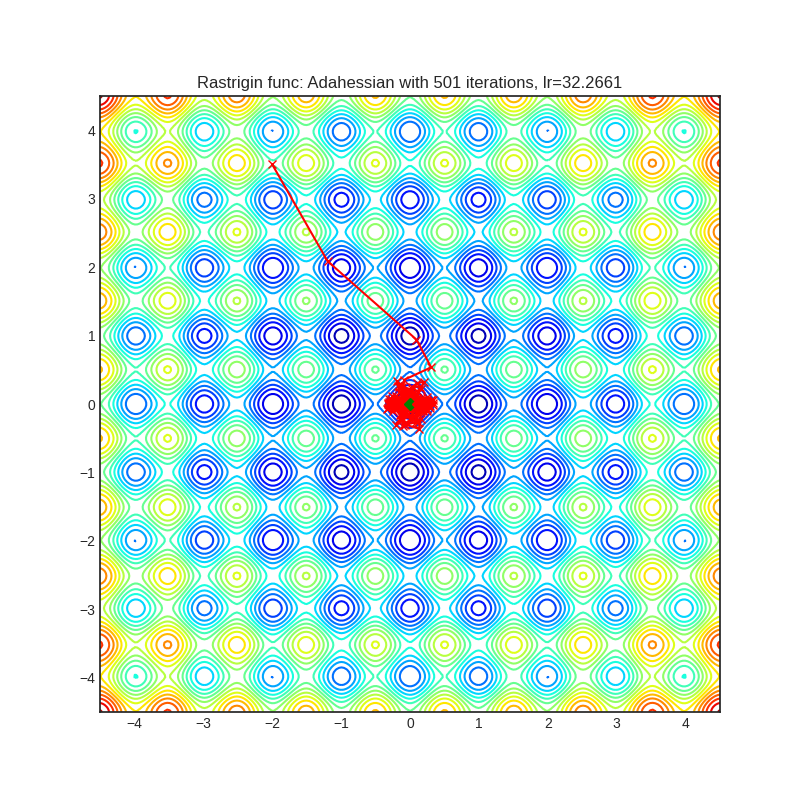
|
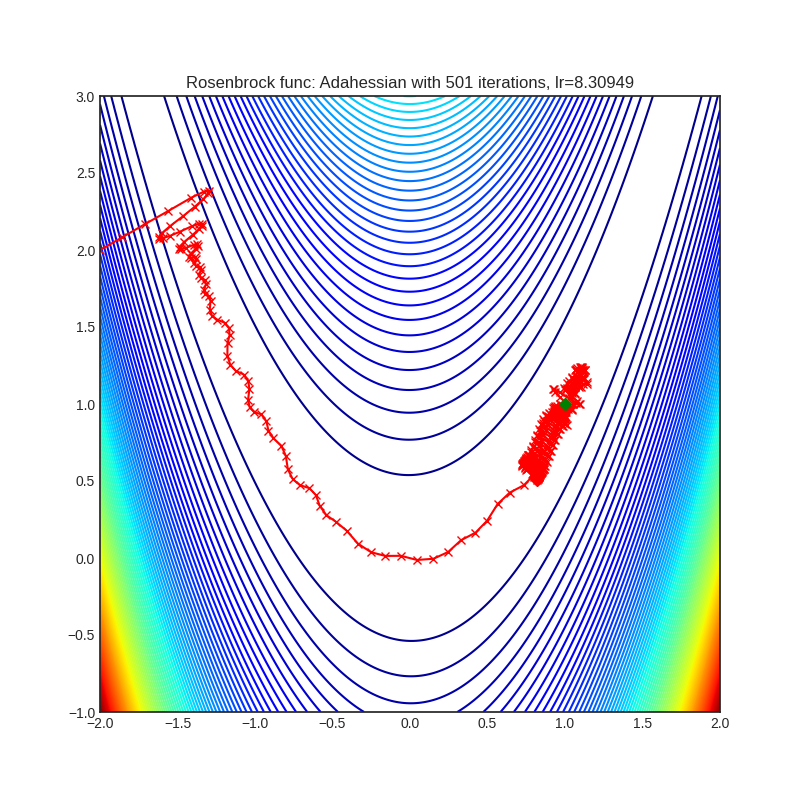
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Adahessian(
m.parameters(),
lr= 1.0,
betas= (0.9, 0.999),
eps= 1e-4,
weight_decay=0.0,
hessian_power=1.0,
)
loss_fn(m(input), target).backward(create_graph = True) # create_graph=True is necessary for Hessian calculation
optimizer.step()论文: ADAHESSIAN: 机器学习中的自适应二阶优化器 (2020) [https://arxiv.org/abs/2006.00719]
AdamP
AdamP提出了一种简单而有效的解决方案:在应用于尺度不变权重(例如,位于BN层之前的卷积权重)的Adam优化器的每次迭代中,AdamP从更新向量中移除径向分量(即与权重向量平行的分量)。直观地说,这种操作防止了沿着仅增加权重范数而不有助于损失最小化的径向方向的不必要更新。
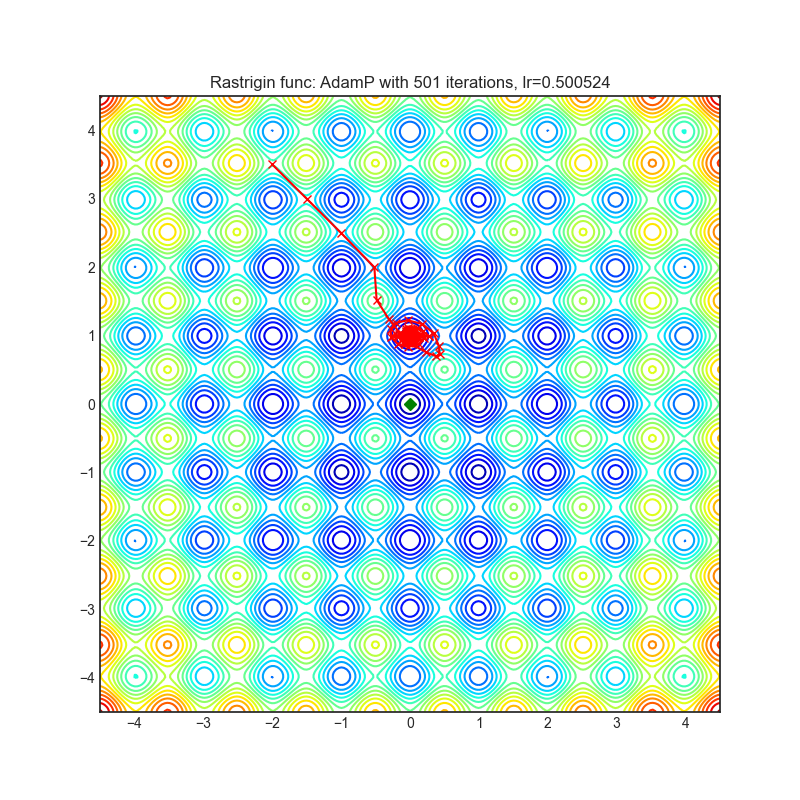
|
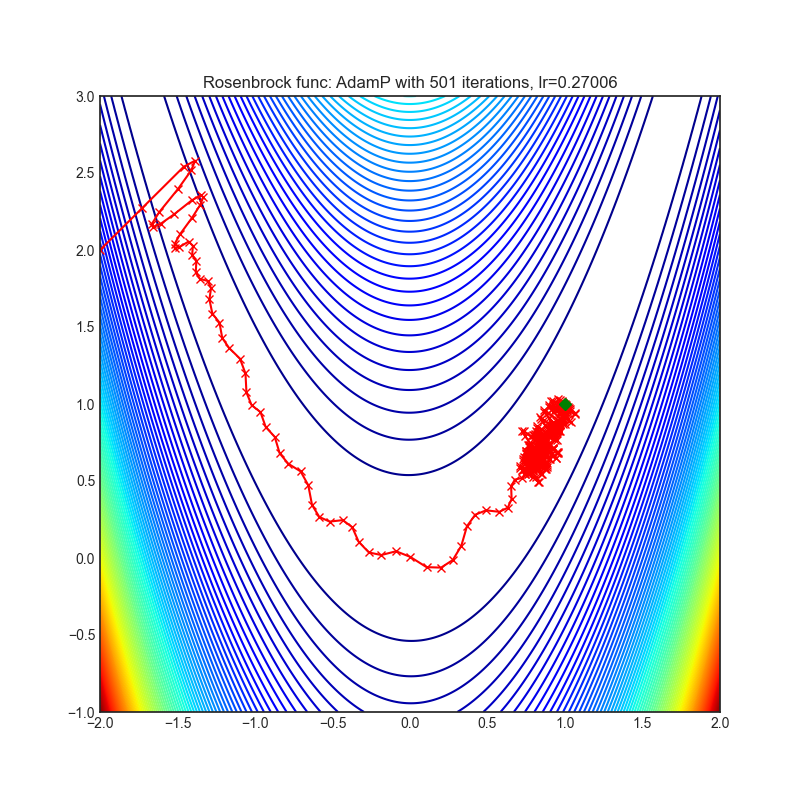
|
import torch_optimizer as optim
# model = ...
optimizer = optim.AdamP(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
delta = 0.1,
wd_ratio = 0.1
)
optimizer.step()论文: 放慢动量优化器中权重范数增长 (2020) [https://arxiv.org/abs/2006.08217]
AggMo
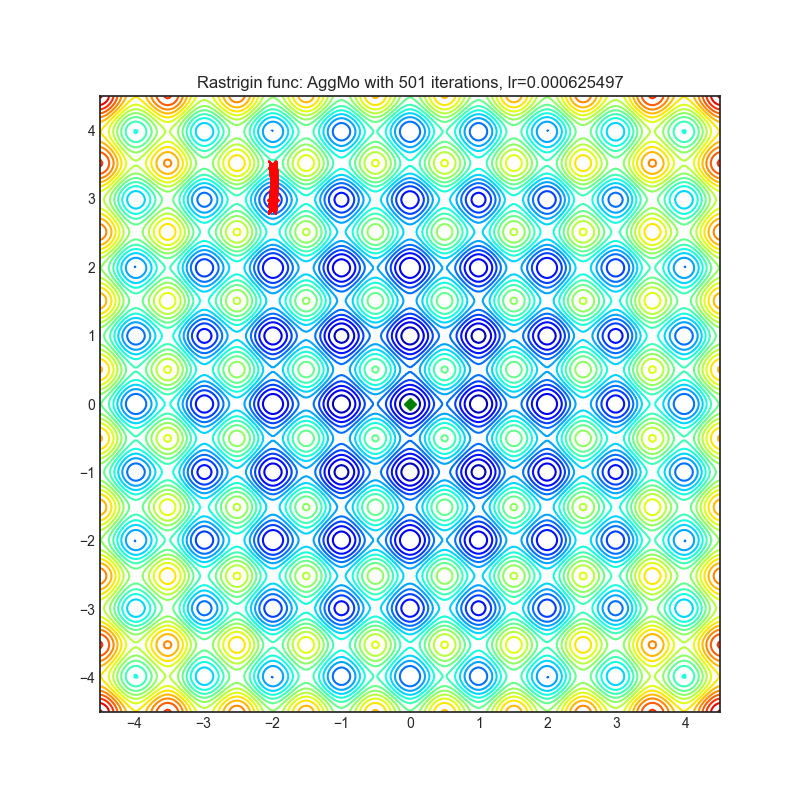
|
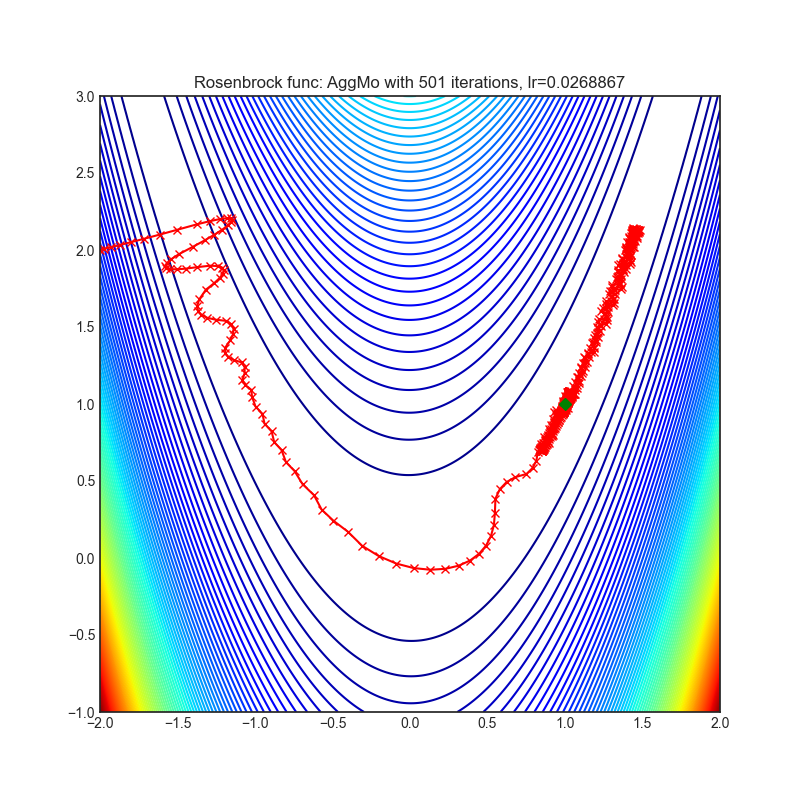
|
import torch_optimizer as optim
# model = ...
optimizer = optim.AggMo(
m.parameters(),
lr= 1e-3,
betas=(0.0, 0.9, 0.99),
weight_decay=0,
)
optimizer.step()论文: 聚合动量:通过被动阻尼提高稳定性 (2019) [https://arxiv.org/abs/1804.00325]
Apollo
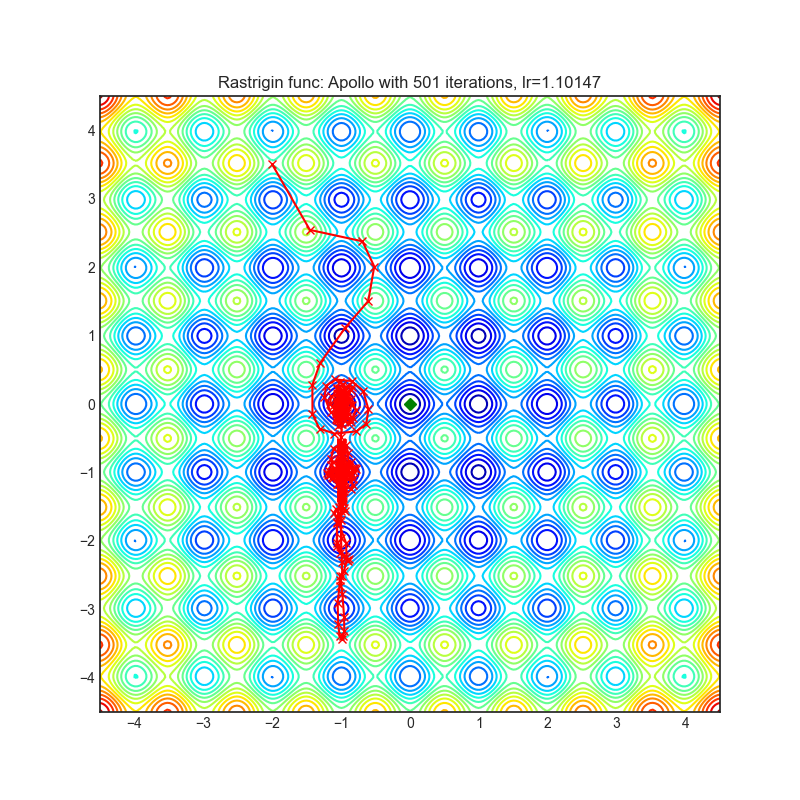
|
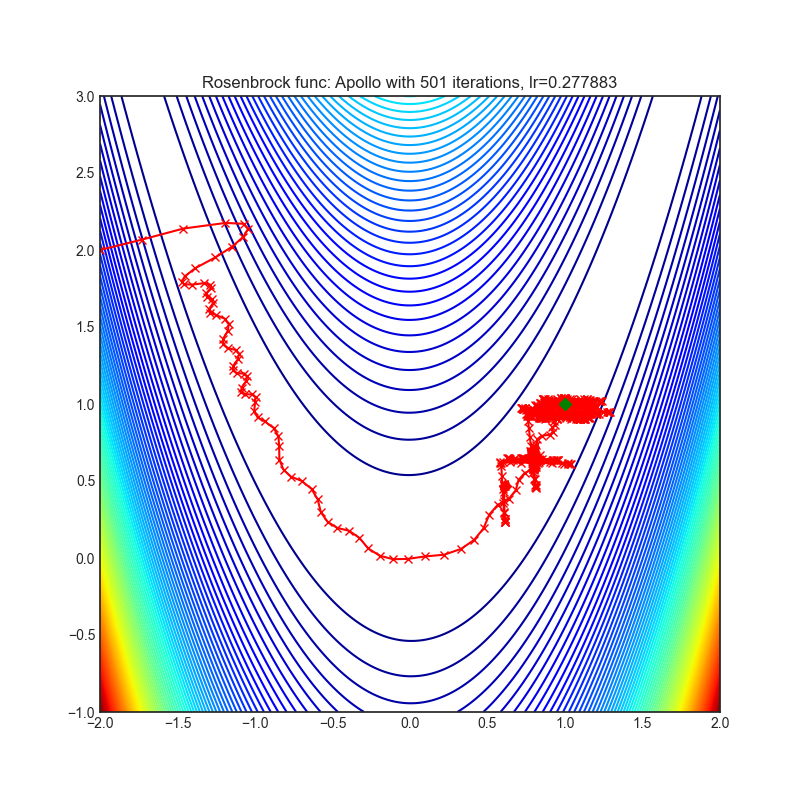
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Apollo(
m.parameters(),
lr= 1e-2,
beta=0.9,
eps=1e-4,
warmup=0,
init_lr=0.01,
weight_decay=0,
)
optimizer.step()论文: Apollo:非凸随机优化的自适应参数化对角拟牛顿方法 (2020) [https://arxiv.org/abs/2009.13586]
DiffGrad
基于当前和立即过去的梯度之间的差值,调整每个参数的步长,以便对于变化较快的梯度参数具有较大的步长,而对于变化较慢的梯度参数具有较小的步长。
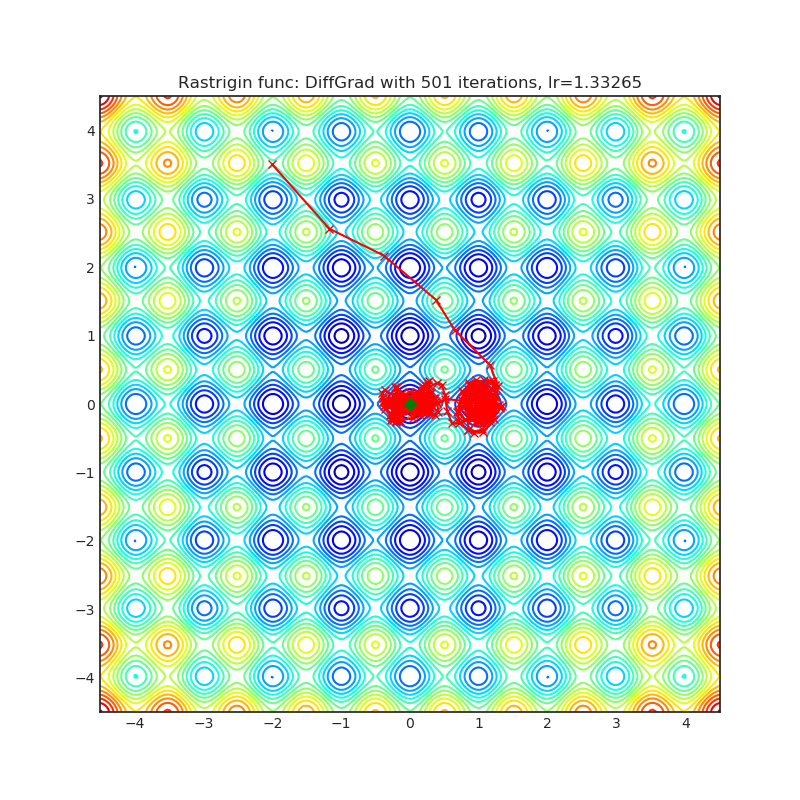
|
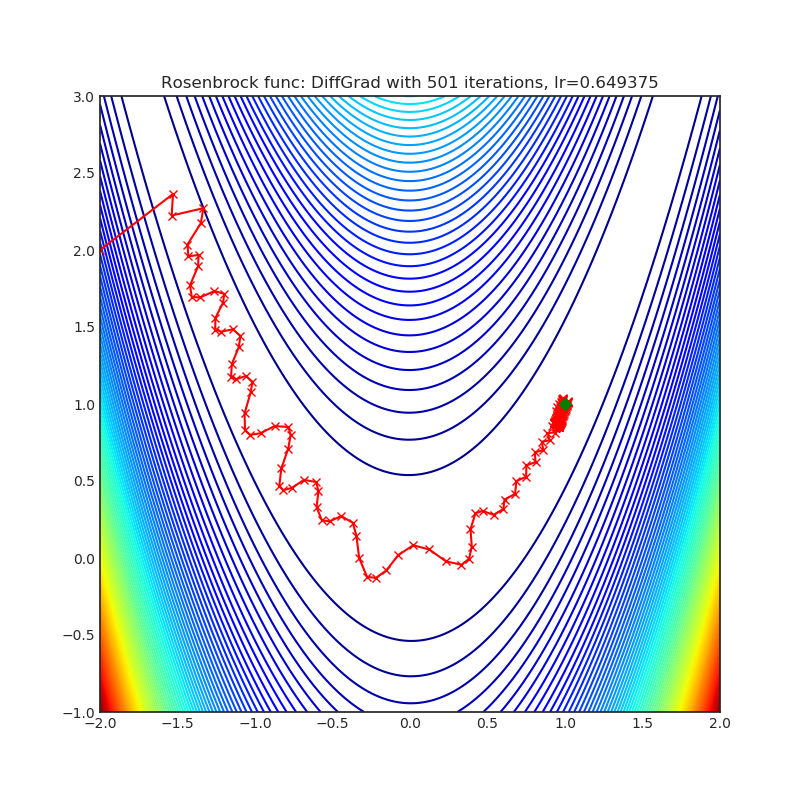
|
import torch_optimizer as optim
# model = ...
optimizer = optim.DiffGrad(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()论文: diffGrad:卷积神经网络的优化方法 (2019) [https://arxiv.org/abs/1909.11015]
Lamb
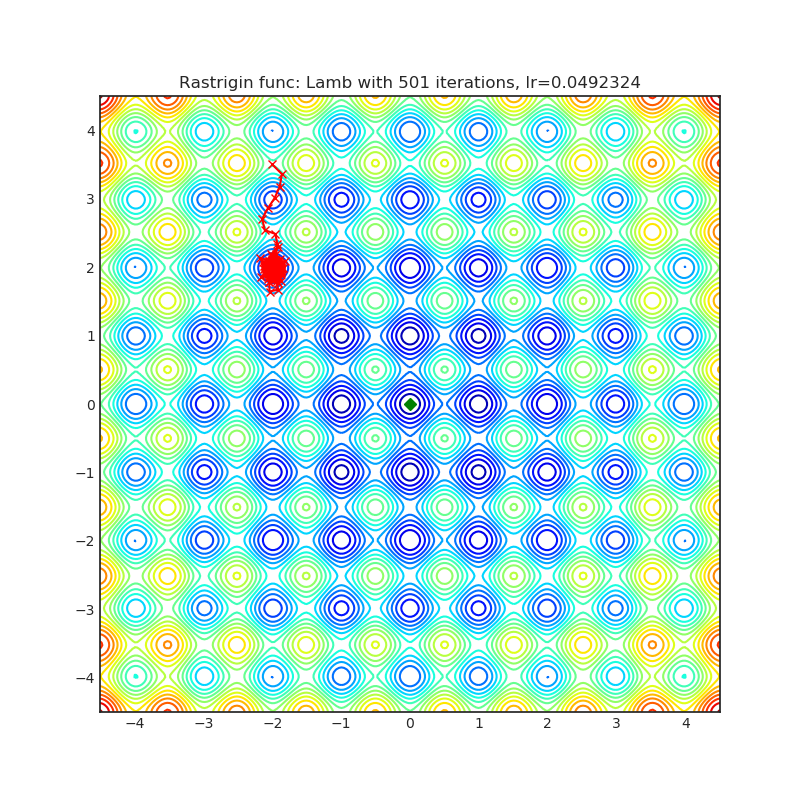
|
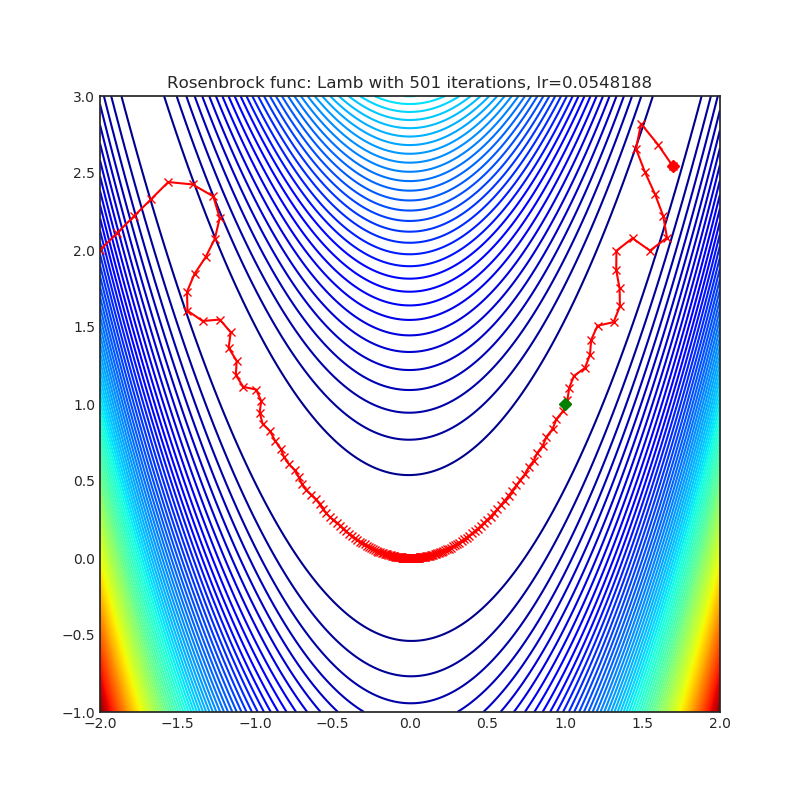
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Lamb(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()论文: 深度学习的批量优化:76分钟训练BERT (2019) [https://arxiv.org/abs/1904.00962]
Lookahead
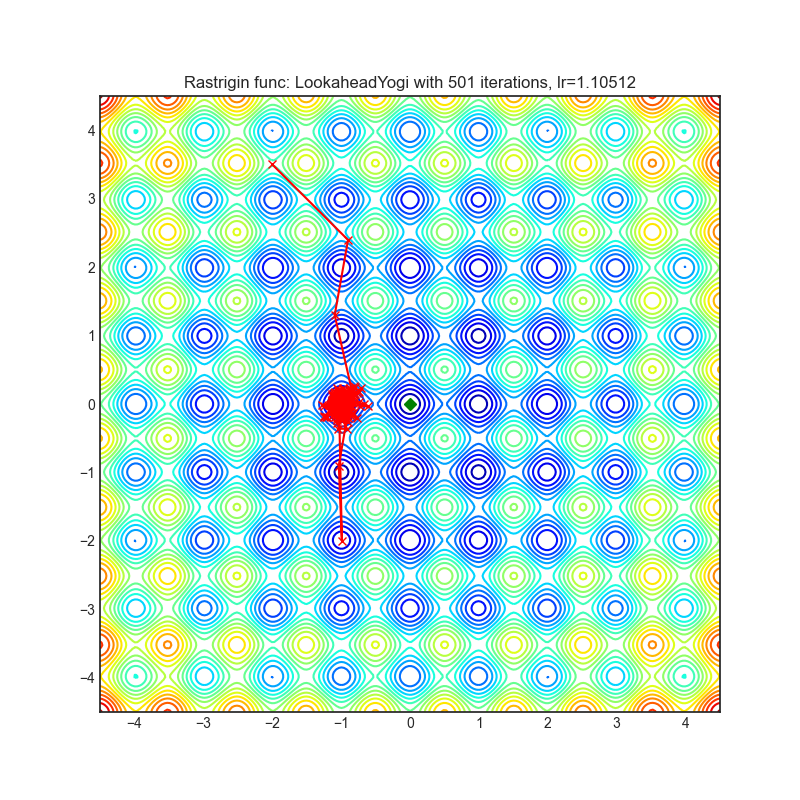
|
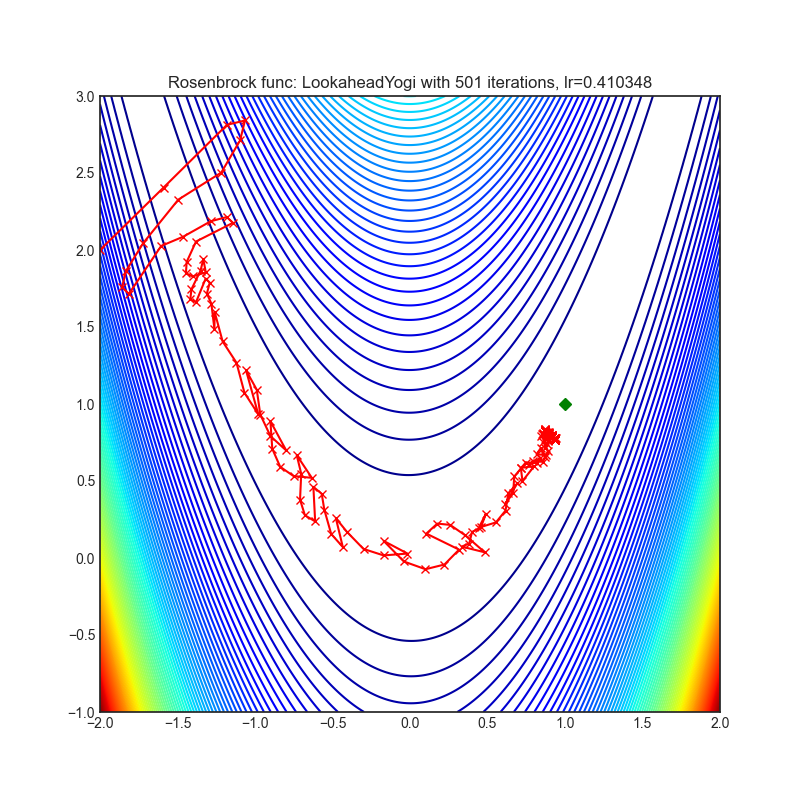
|
import torch_optimizer as optim
# model = ...
# base optimizer, any other optimizer can be used like Adam or DiffGrad
yogi = optim.Yogi(
m.parameters(),
lr= 1e-2,
betas=(0.9, 0.999),
eps=1e-3,
initial_accumulator=1e-6,
weight_decay=0,
)
optimizer = optim.Lookahead(yogi, k=5, alpha=0.5)
optimizer.step()论文: 前瞻优化器:向前k步,向后一步 (2019) [https://arxiv.org/abs/1907.08610]
MADGRAD
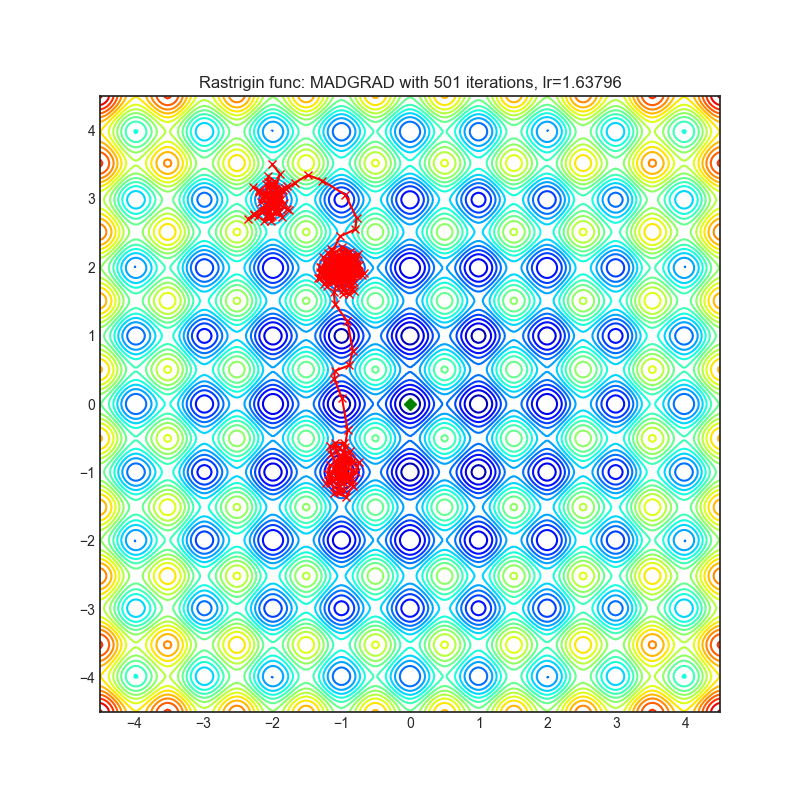
|
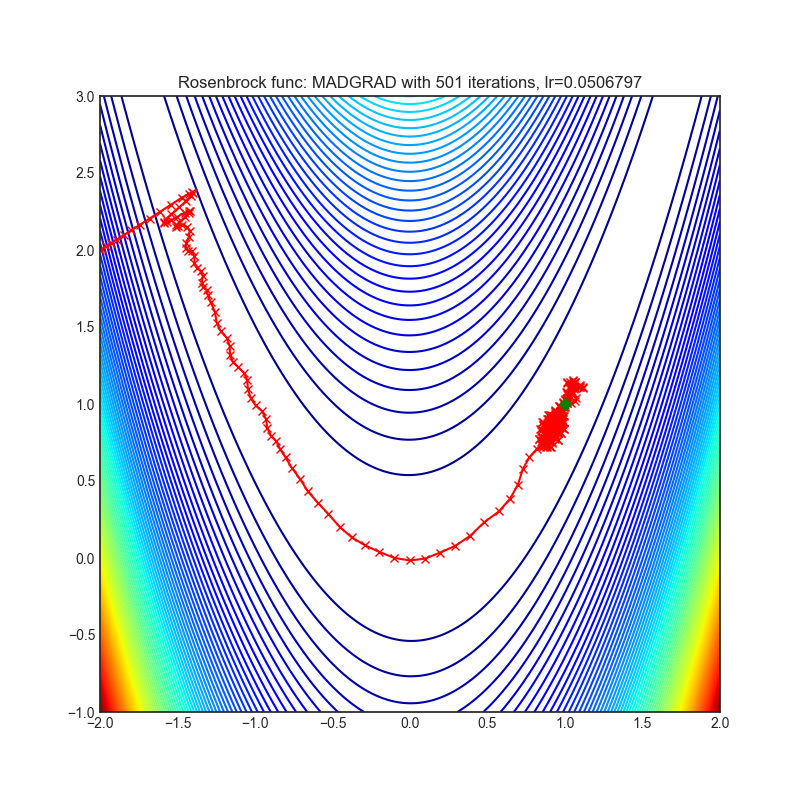
|
import torch_optimizer as optim
# model = ...
optimizer = optim.MADGRAD(
m.parameters(),
lr=1e-2,
momentum=0.9,
weight_decay=0,
eps=1e-6,
)
optimizer.step()论文: 无妥协的自适应性:用于随机优化的动量化、自适应、双重平均梯度方法 (2021) [https://arxiv.org/abs/2101.11075]
NovoGrad
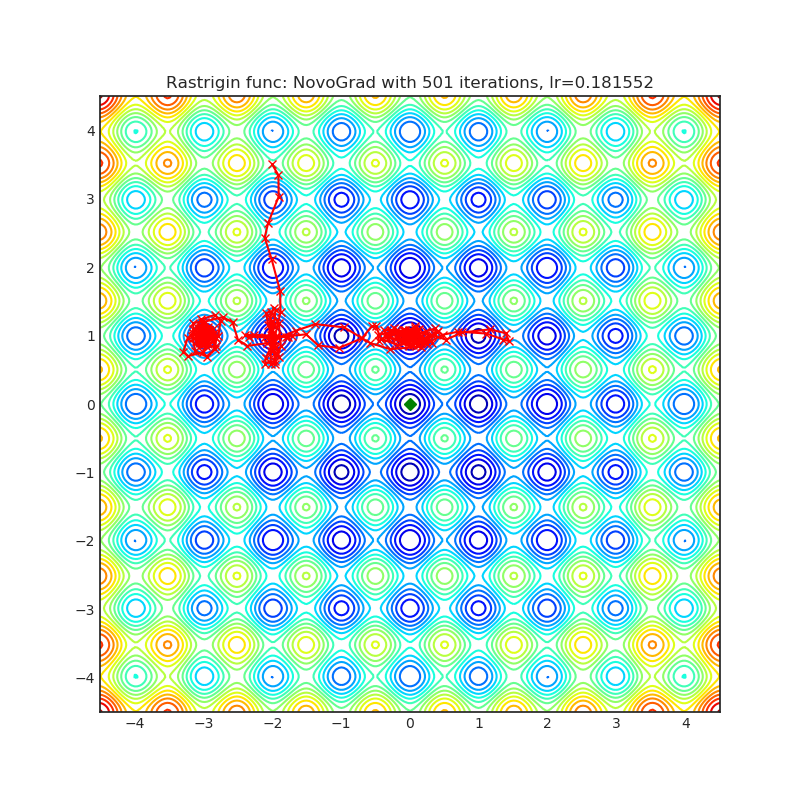
|
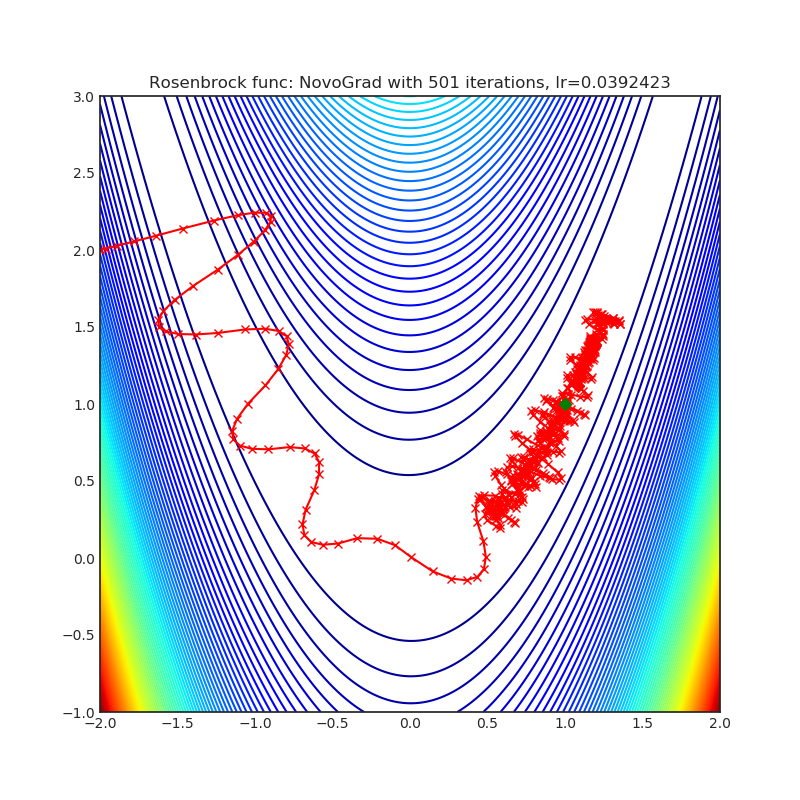
|
import torch_optimizer as optim
# model = ...
optimizer = optim.NovoGrad(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
grad_averaging=False,
amsgrad=False,
)
optimizer.step()论文: 《基于层自适应矩的深度网络训练的随机梯度下降法》(2019)[https://arxiv.org/abs/1905.11286]
PID
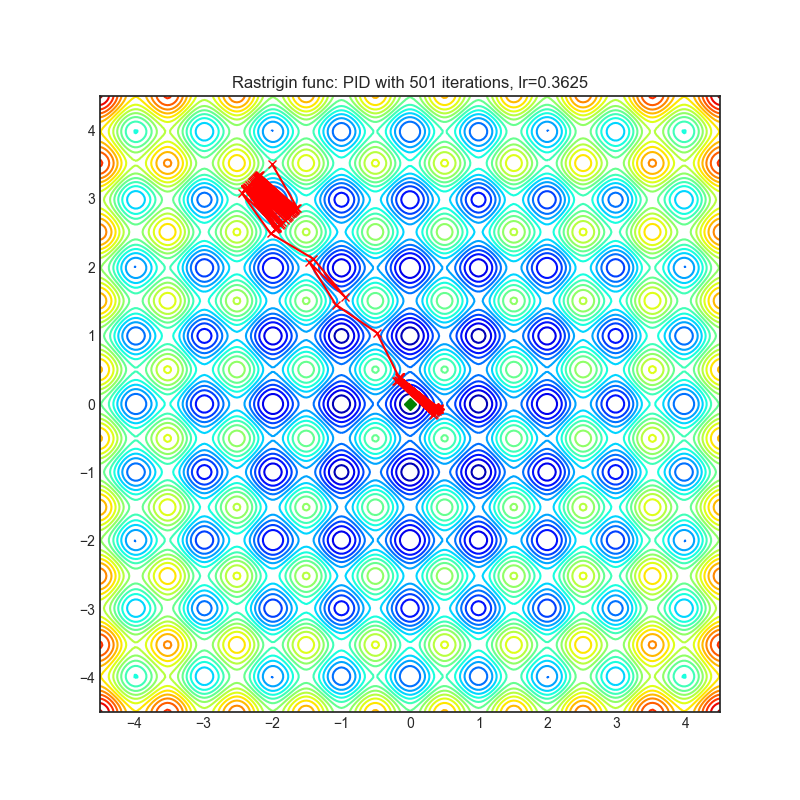
|
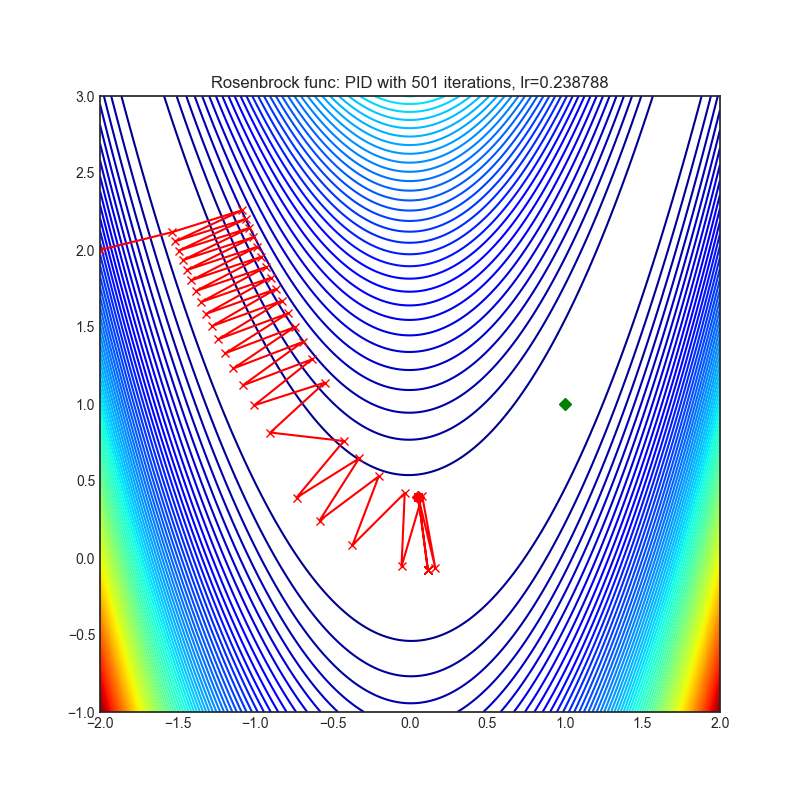
|
import torch_optimizer as optim
# model = ...
optimizer = optim.PID(
m.parameters(),
lr=1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
integral=5.0,
derivative=10.0,
)
optimizer.step()论文: 《深度网络随机优化的PID控制器方法》(2018)[http://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR18_PID.pdf]
QHAdam
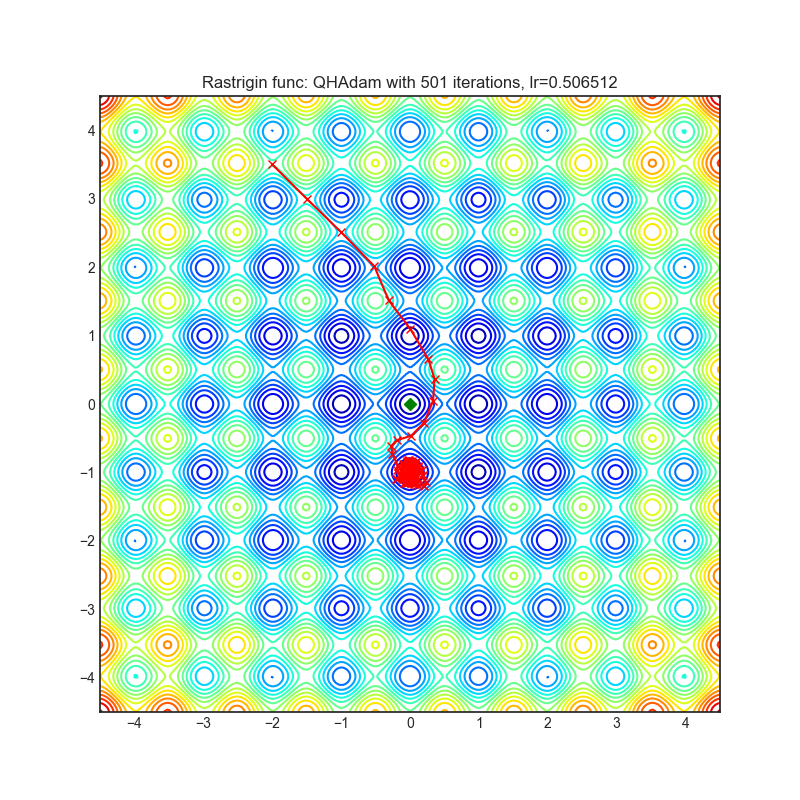
|
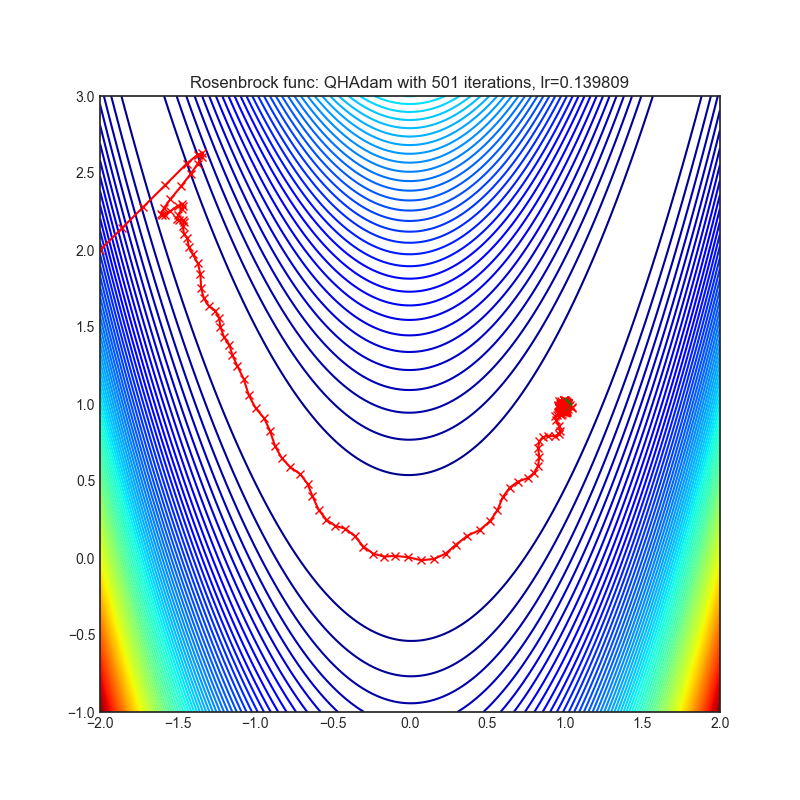
|
import torch_optimizer as optim
# model = ...
optimizer = optim.QHAdam(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
nus=(1.0, 1.0),
weight_decay=0,
decouple_weight_decay=False,
eps=1e-8,
)
optimizer.step()论文: 《深度学习中的准双曲动量和Adam》(2019)[https://arxiv.org/abs/1810.06801]
QHM
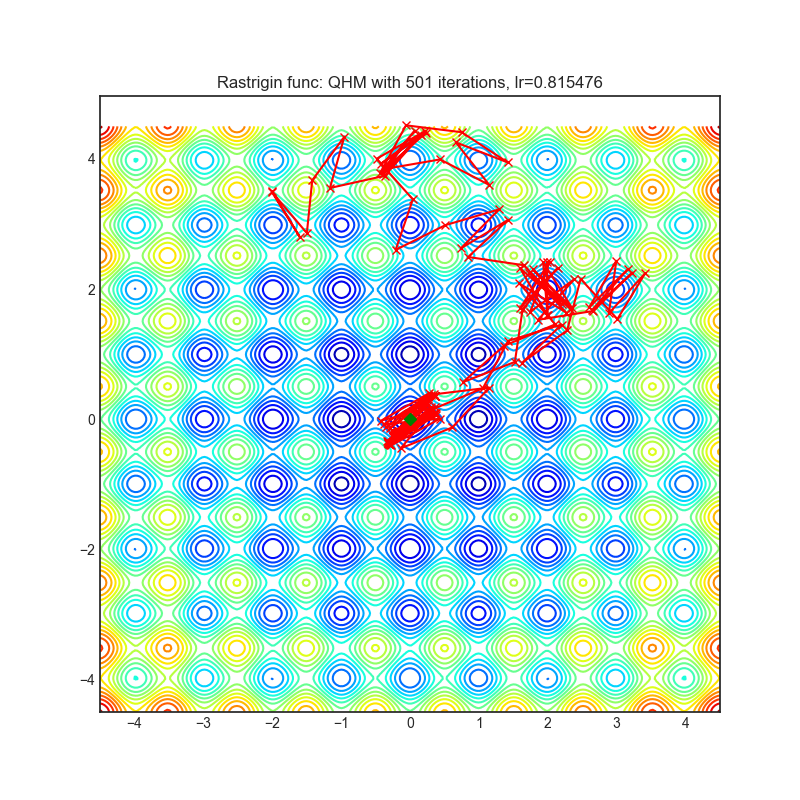
|
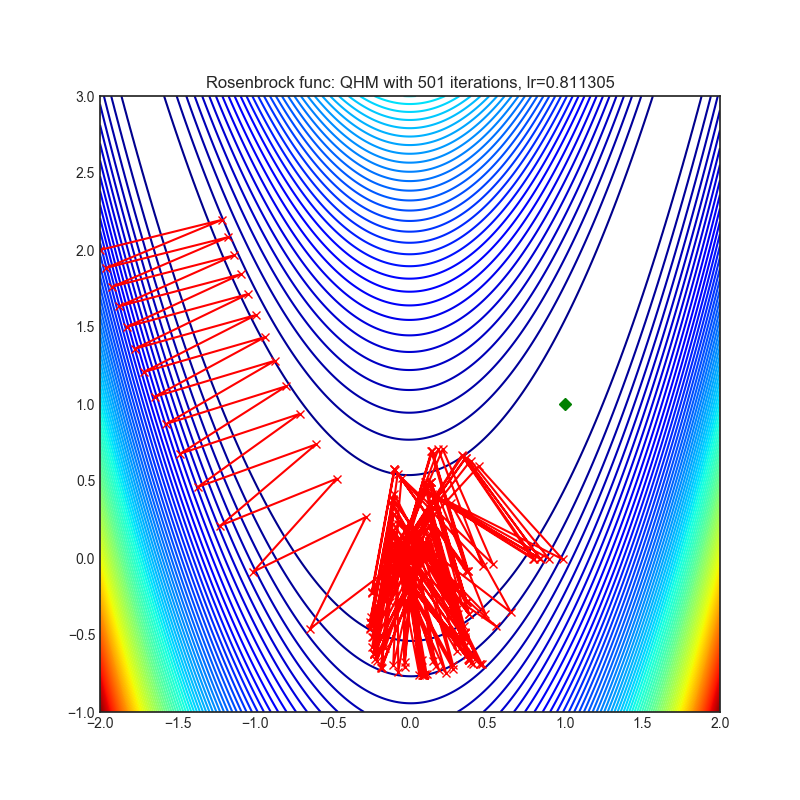
|
import torch_optimizer as optim
# model = ...
optimizer = optim.QHM(
m.parameters(),
lr=1e-3,
momentum=0,
nu=0.7,
weight_decay=1e-2,
weight_decay_type='grad',
)
optimizer.step()论文: 《深度学习中的准双曲动量和Adam》(2019)[https://arxiv.org/abs/1810.06801]
RAdam
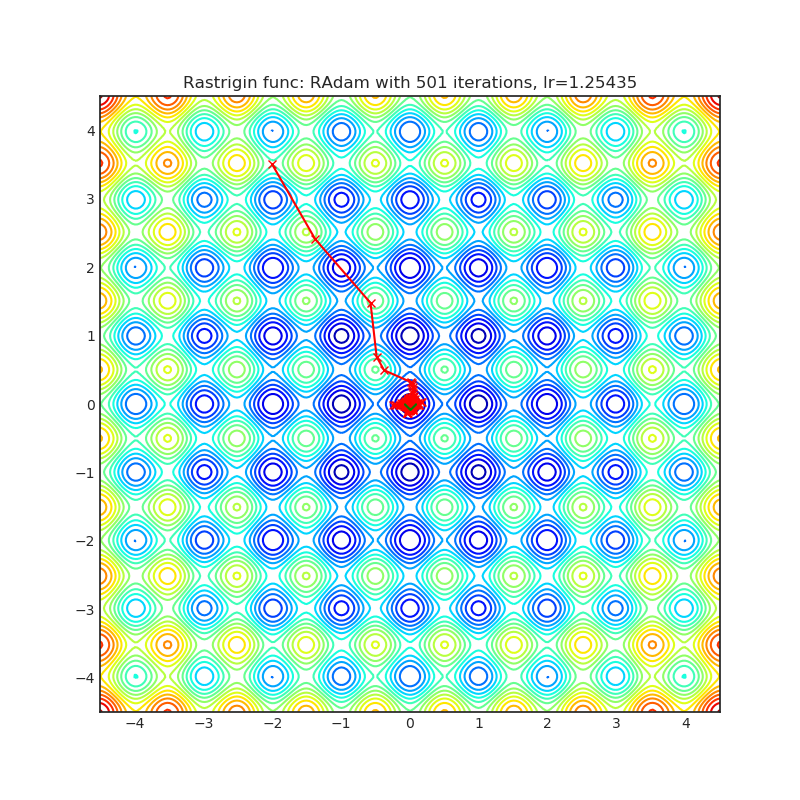
|
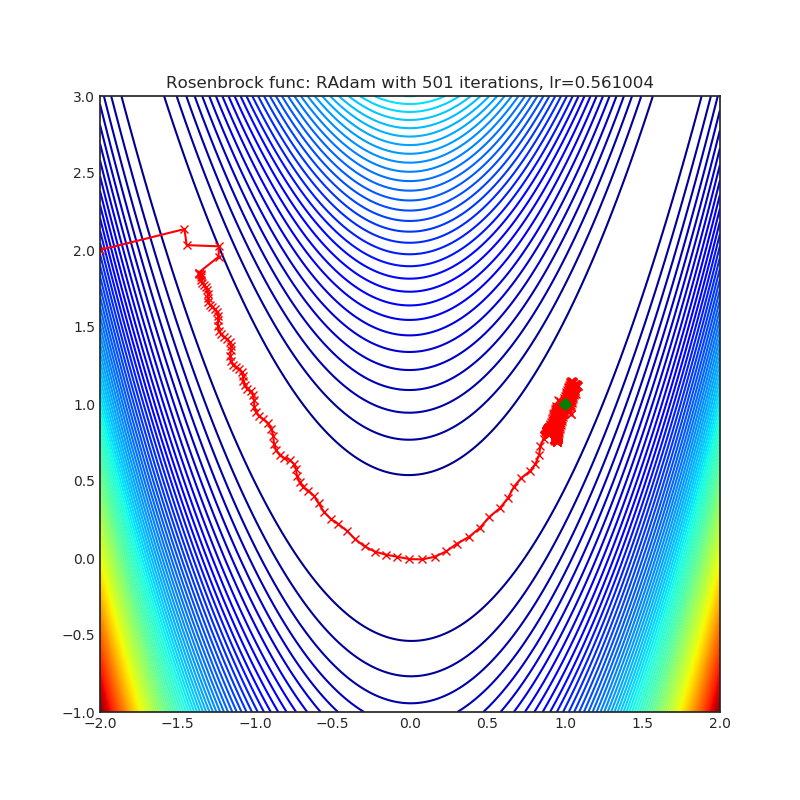
|
import torch_optimizer as optim
# model = ...
optimizer = optim.RAdam(
m.parameters(),
lr= 1e-3,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=0,
)
optimizer.step()论文: 《自适应学习率的方差及其相关问题》(2019)[https://arxiv.org/abs/1908.03265]
Ranger
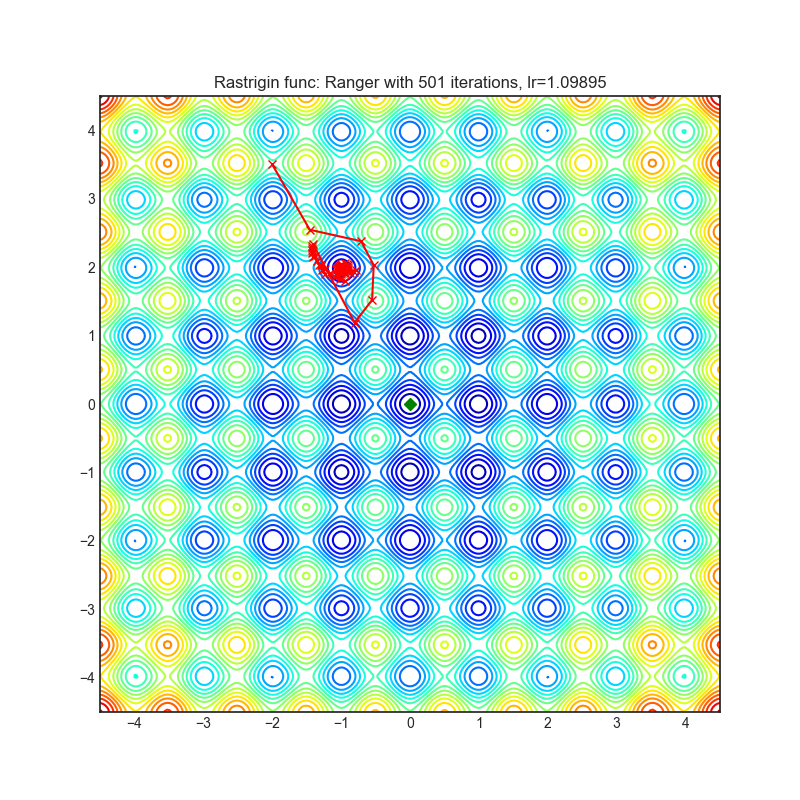
|
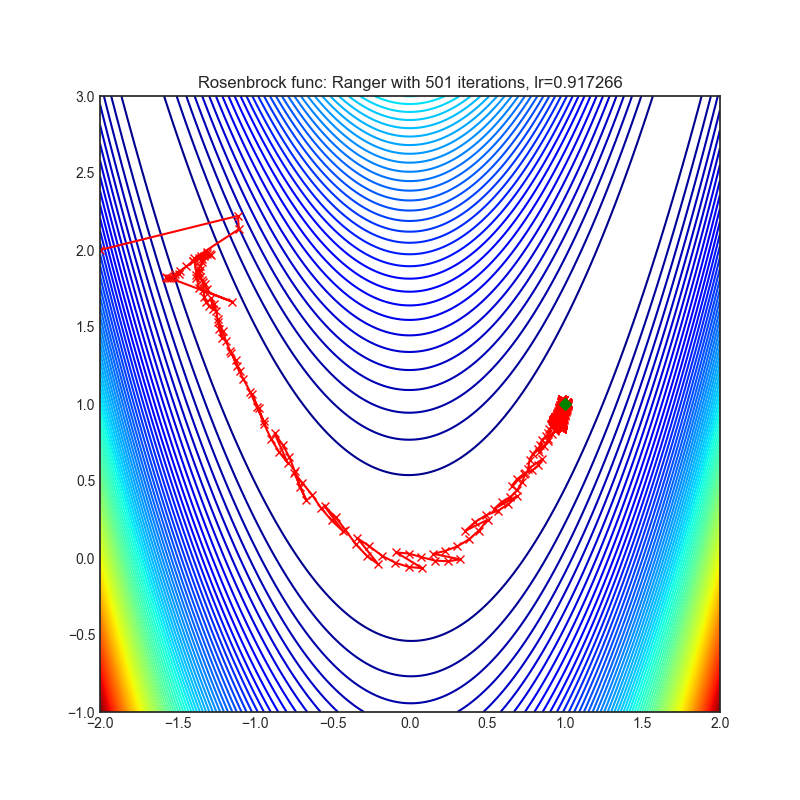
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Ranger(
m.parameters(),
lr=1e-3,
alpha=0.5,
k=6,
N_sma_threshhold=5,
betas=(.95, 0.999),
eps=1e-5,
weight_decay=0
)
optimizer.step()论文: 《新型深度学习优化器Ranger:RAdam + LookAhead的协同组合,取两者之所长》(2019)[https://medium.com/@lessw/new-deep-learning-optimizer-ranger-synergistic-combination-of-radam-lookahead-for-the-best-of-2dc83f79a48d]
参考代码: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RangerQH
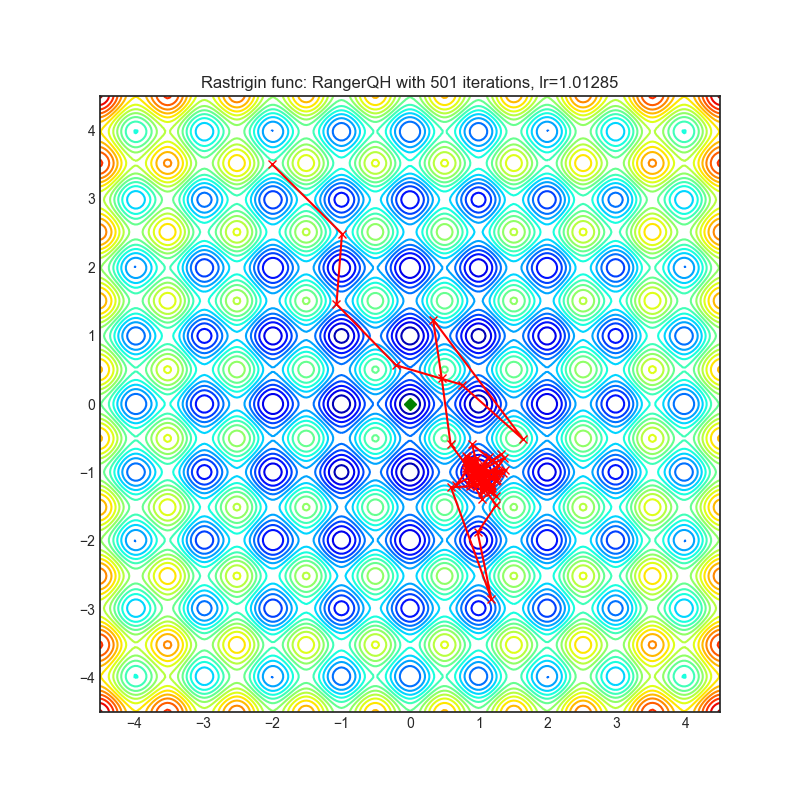
|
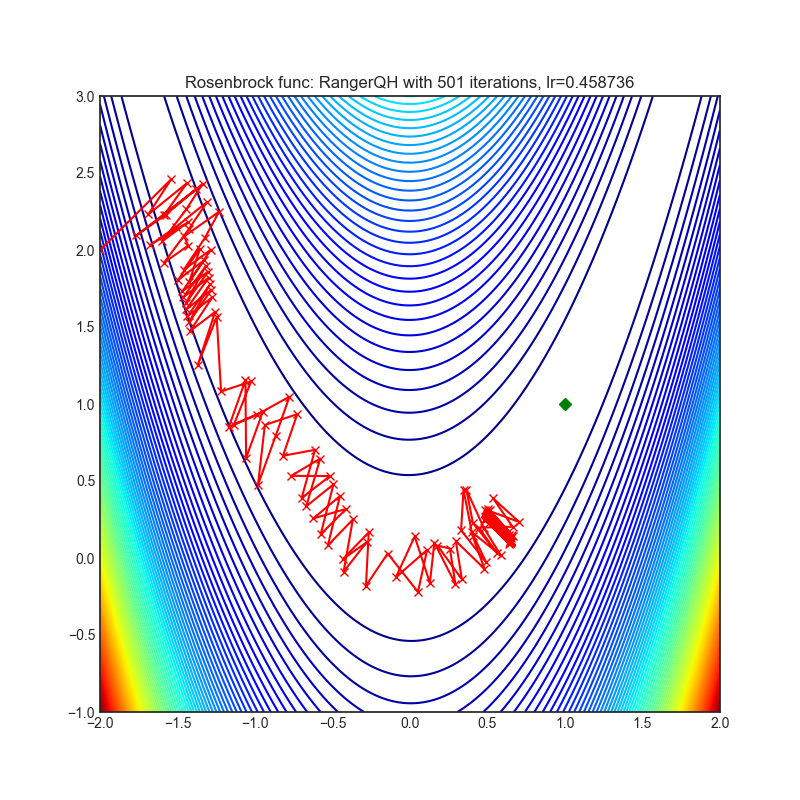
|
import torch_optimizer as optim
# model = ...
optimizer = optim.RangerQH(
m.parameters(),
lr=1e-3,
betas=(0.9, 0.999),
nus=(.7, 1.0),
weight_decay=0.0,
k=6,
alpha=.5,
decouple_weight_decay=False,
eps=1e-8,
)
optimizer.step()论文: 《深度学习中的准双曲动量和Adam》(2018)[https://arxiv.org/abs/1810.06801]
参考代码: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
RangerVA
|
|
import torch_optimizer as optim
# model = ...
optimizer = optim.RangerVA(
m.parameters(),
lr=1e-3,
alpha=0.5,
k=6,
n_sma_threshhold=5,
betas=(.95, 0.999),
eps=1e-5,
weight_decay=0,
amsgrad=True,
transformer='softplus',
smooth=50,
grad_transformer='square'
)
optimizer.step()论文: 《校准自适应学习率以改善Adam的收敛性》(2019)[https://arxiv.org/abs/1908.00700v2]
参考代码: https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
SGDP
|
|
import torch_optimizer as optim
# model = ...
optimizer = optim.SGDP(
m.parameters(),
lr= 1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
nesterov=False,
delta = 0.1,
wd_ratio = 0.1
)
optimizer.step()论文: 放慢动量优化器中权重范数增长 (2020) [https://arxiv.org/abs/2006.08217]
SGDW
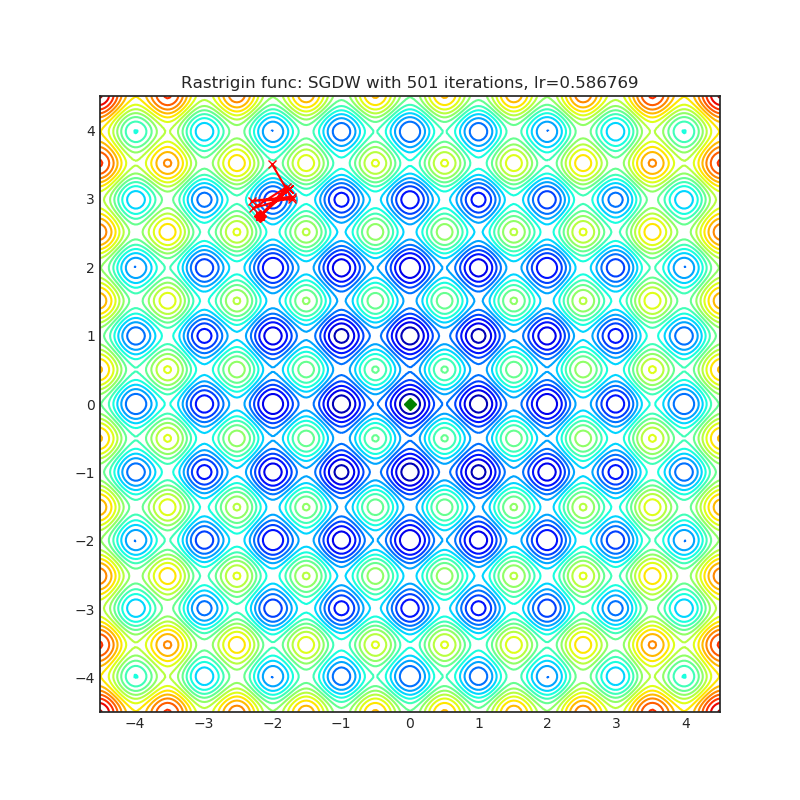
|
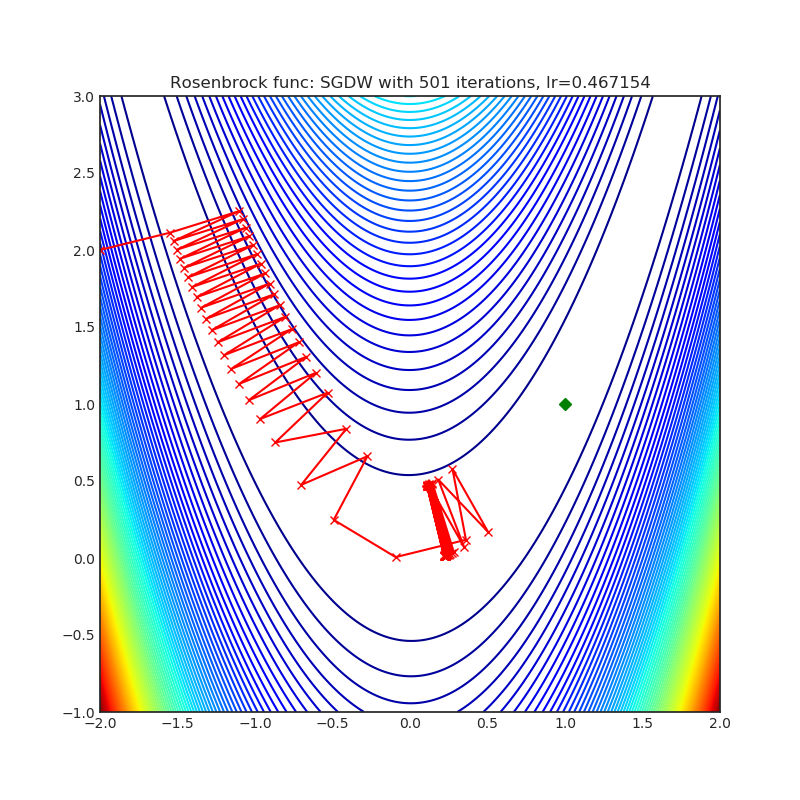
|
import torch_optimizer as optim
# model = ...
optimizer = optim.SGDW(
m.parameters(),
lr= 1e-3,
momentum=0,
dampening=0,
weight_decay=1e-2,
nesterov=False,
)
optimizer.step()论文: 《SGDR:具有热重启的随机梯度下降法》(2017)[https://arxiv.org/abs/1608.03983]
SWATS
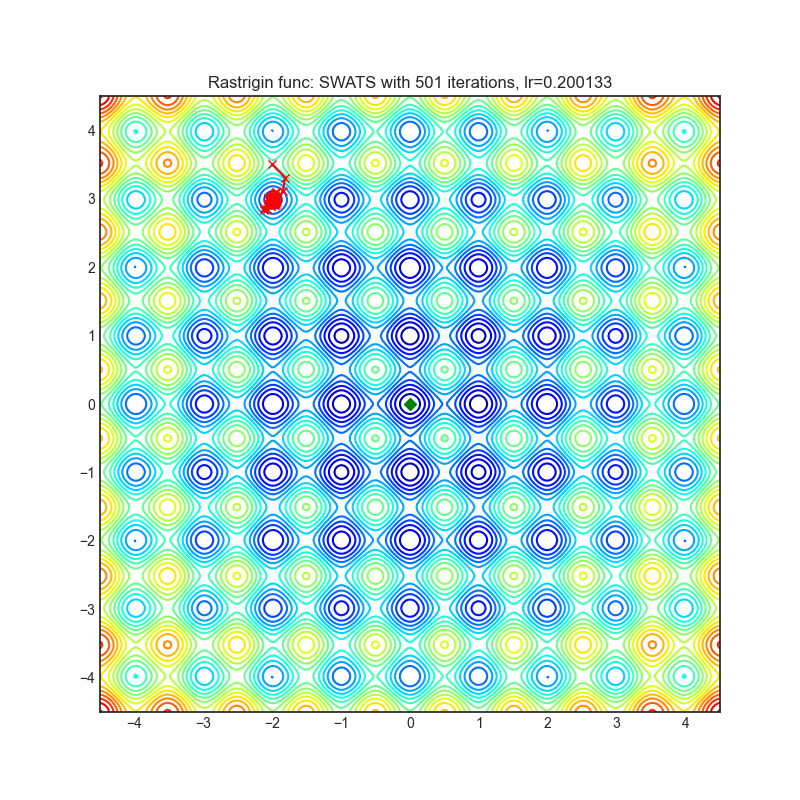
|
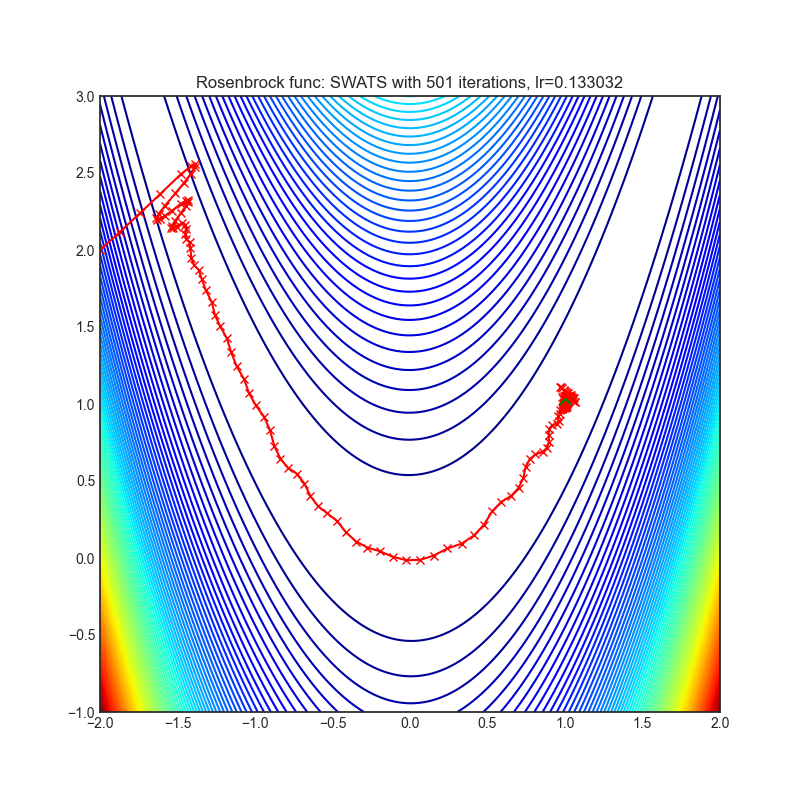
|
import torch_optimizer as optim
# model = ...
optimizer = optim.SWATS(
model.parameters(),
lr=1e-1,
betas=(0.9, 0.999),
eps=1e-3,
weight_decay= 0.0,
amsgrad=False,
nesterov=False,
)
optimizer.step()论文: 《从Adam切换到SGD以提高泛化性能》(2017)[https://arxiv.org/abs/1712.07628]
Shampoo
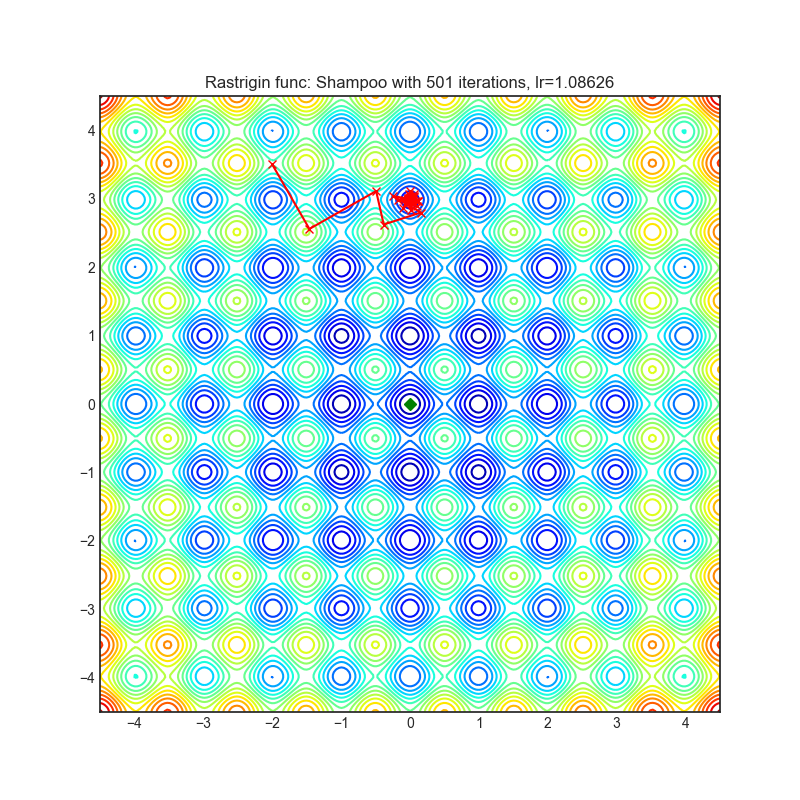
|
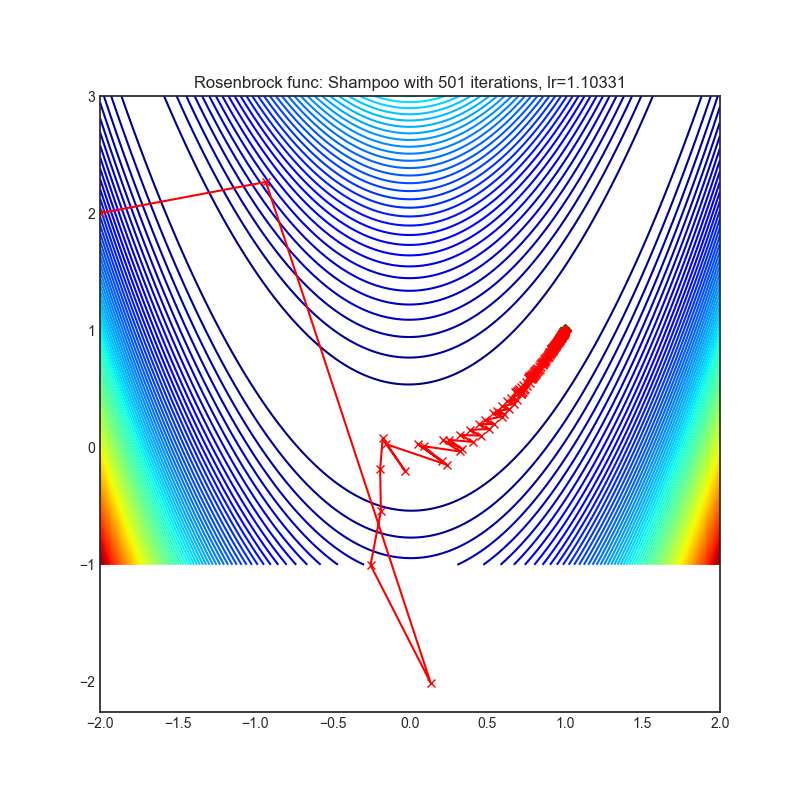
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Shampoo(
m.parameters(),
lr=1e-1,
momentum=0.0,
weight_decay=0.0,
epsilon=1e-4,
update_freq=1,
)
optimizer.step()论文: 《Shampoo:预条件随机张量优化》(2018)[https://arxiv.org/abs/1802.09568]
Yogi
Yogi是一种基于ADAM的优化算法,具有更精细的有效学习率控制,在收敛性方面的理论保证与ADAM相似。
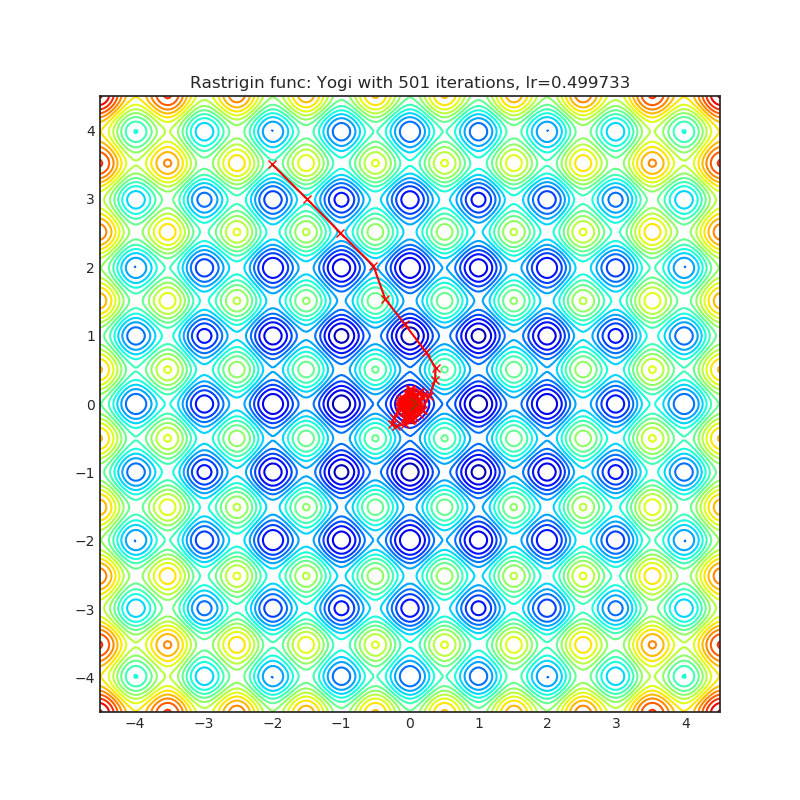
|
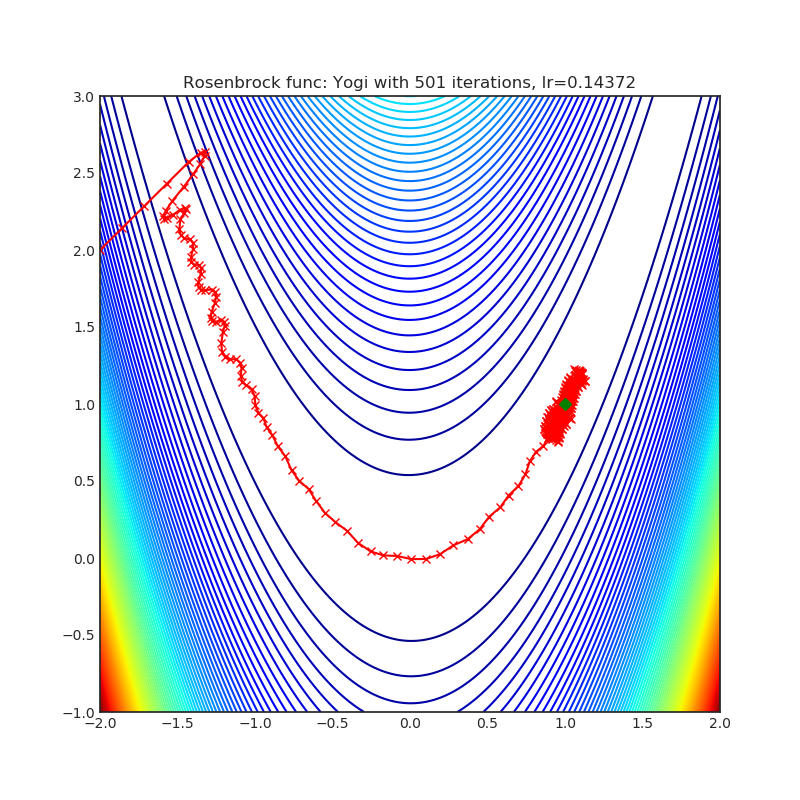
|
import torch_optimizer as optim
# model = ...
optimizer = optim.Yogi(
m.parameters(),
lr= 1e-2,
betas=(0.9, 0.999),
eps=1e-3,
initial_accumulator=1e-6,
weight_decay=0,
)
optimizer.step()论文: 《非凸优化的自适应方法》(2018)[https://papers.nips.cc/paper/8186-adaptive-methods-for-nonconvex-optimization]
Adam(PyTorch内置)
|
|
SGD(PyTorch内置)
|
|
变更
0.3.0 (2021-10-30)
撤销Drop RAdam。
0.2.0 (2021-10-25)
删除Drop RAdam优化器,因为它已包含在PyTorch中。
不包含测试作为可安装包。
尽可能保留内存布局。
添加MADGRAD优化器。
0.1.0 (2021-01-01)
初始发布。
添加了对A2GradExp、A2GradInc、A2GradUni、AccSGD、AdaBelief、AdaBound、AdaMod、Adafactor、Adahessian、AdamP、AggMo、Apollo、DiffGrad、Lamb、Lookahead、NovoGrad、PID、QHAdam、QHM、RAdam、Ranger、RangerQH、RangerVA、SGDP、SGDW、SWATS、Shampoo、Yogi的支持。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。







