将多个TensorBoard运行合并为新的事件(或CSV)文件

项目描述







本项目可以导入PyTorch和TensorFlow事件文件,但主要使用PyTorch进行测试。对于仅TF的项目,请参阅
tensorboard-aggregator。
计算多个TensorBoard运行目录的统计信息(mean,std,min,max,median 或任何其他 numpy 操作)。这可以用于例如训练模型集合,以减少损失/准确度/错误曲线的噪声,并建立性能改进的统计显著性,或更好地了解认知不确定性。结果可以保存到磁盘上,作为新的TensorBoard运行或CSV/JSON/Excel。更易于添加更多文件格式,PR欢迎。
示例笔记本
| 基本Python API演示 |    |
演示如何处理本地TensorBoard事件文件。 |
| Functorch MLP集合 | |
展示如何使用TensorBoard Reducer聚合运行指标,在训练模型集合时使用functorch。。 |
| Weights & Biases集成 | |
在MNIST上训练PyTorch CNN集成,结果记录到WandB,从多个WandB运行中下载指标,使用tb-reducer进行聚合,然后将新运行重新上传到WandB。 |
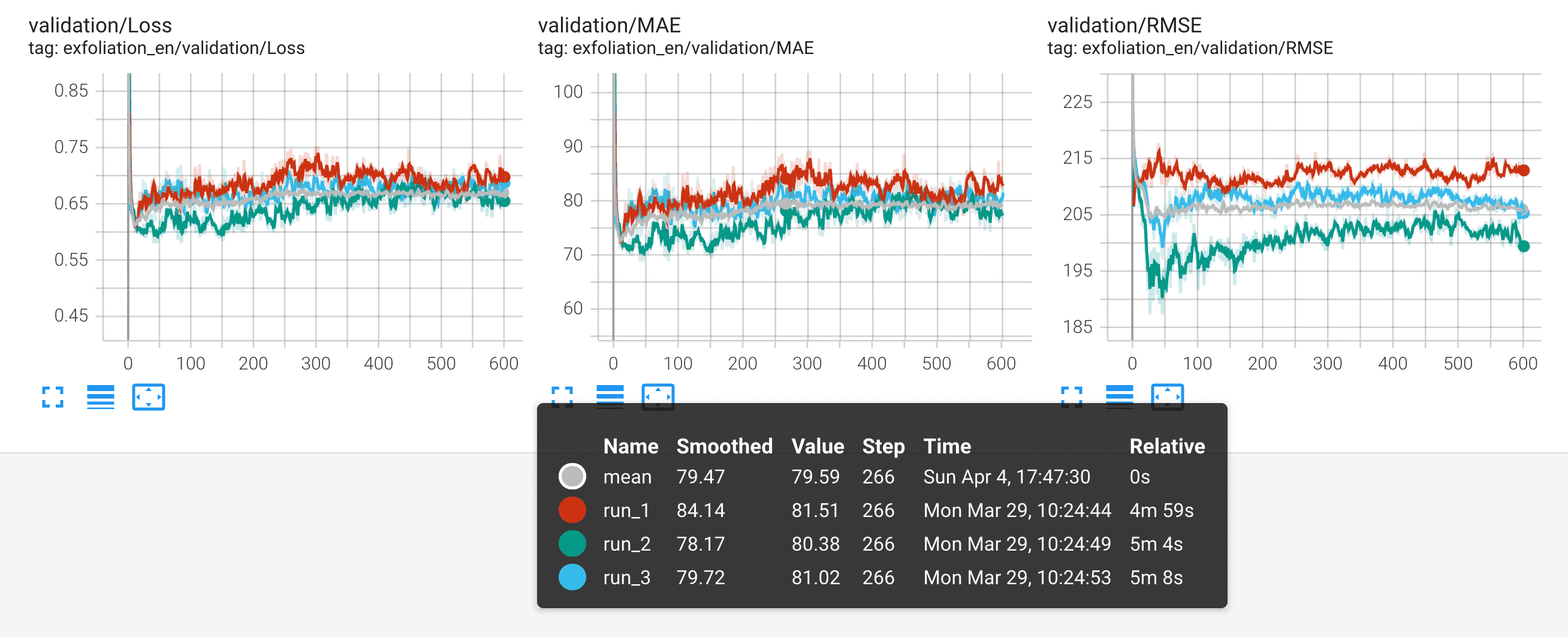
此处以粉色显示的3次运行的均值比单个运行更少噪音,更适合模型之间或不同训练技术之间的比较。
安装
pip install tensorboard-reducer
Excel支持需要安装额外的依赖项
pip install 'tensorboard-reducer[excel]'
用法
命令行界面
tb-reducer runs/of-your-model* -o output-dir -r mean,std,min,max
所有位置命令行参数都被解释为输入目录,并且预期包含TensorBoard事件文件。这些可以单独指定,也可以使用shell扩展通配符。您可以通过在将它们传递给tb-reducer之前运行echo runs/of-your-model*来检查您是否获得了正确的输入目录。
注意:默认情况下,TensorBoard Reducer期望事件文件包含相同的标签和所有标量的相等数量的步骤。如果您对一个模型进行了300个epoch的训练,而对另一个模型进行了400个epoch的训练,并且/或者为每个模型记录了不同的指标集(TensorBoard中的标签),请查看CLI标志--lax-steps和--lax-tags以禁用此保护措施。Python API中的相应kwargs是load_tb_events()上的strict_tags = True和strict_steps = True。
此外,tb-reducer还具有以下标志
-o/--outpath(必需):写入磁盘的文件路径或目录。如果--outpath是目录,输出将保存为TensorBoard运行,每个聚合创建一个新目录,后缀为numpy操作,例如'out/path-mean','out/path-max'等。如果--outpath是文件路径,它必须具有.csv/.json或.xlsx(支持使用例如.csv.gz,json.bz2进行压缩),在这种情况下将创建一个单个文件。CSV将包含包含每个标签(loss,accuracy,...)和减少操作的组合的二级标题。标签名称将在顶级标题中,减少操作在第二级。 提示:将数据保存为CSV或Excel时,请使用pandas.read_csv("path/to/file.csv", header=[0, 1], index_col=0)和pandas.read_excel("path/to/file.xlsx", header=[0, 1], index_col=0)将减少结果加载到多级DataFrame中。-r/--reduce-ops(可选,默认:mean):以逗号分隔的numpy减少操作名称(mean,std,min,max,...)。每个减少将写入一个单独的outpath,后缀为其操作名称。例如,如果outpath='reduced-run',则均值减少将写入'reduced-run-mean'。-f/--overwrite(可选,默认:False):是否要覆盖现有的输出目录/数据文件(CSV,JSON,Excel)。出于安全起见,如果要覆盖的文件/目录不是已知的数据文件并且看起来不像TensorBoard运行目录(即不以'events.out'开头),则覆盖操作将因错误而中止。--lax-tags(可选,默认:False):允许不同的运行有不同的标签集。在此模式下,每个标签减少将运行尽可能多的运行,即使只有一个也是如此。在下游分析中,并非所有标签都将具有相同的统计信息,因此请谨慎行事。--lax-steps(可选,默认:False):允许不同运行中的标签具有不同数量的步骤。在此模式下,每个减少将只使用最短运行中可用的步骤数(与zip(short_list, long_list)的行为相同,它会在short_list耗尽时停止)。--handle-dup-steps(可选,默认:None):如何处理单次运行中同一标签和步骤记录的重复值。可以是'keep-first'、'keep-last'或'mean'之一。'keep-first/last'将保留重复步骤的第一个/最后一个出现,而 'mean' 计算它们的平均值。默认行为是在重复步骤上引发ValueError。--min-runs-per-step(可选,默认:None):给定步骤必须记录的最小运行次数,以便保留。跨更少运行的步骤将被删除。仅在lax_steps为 true 时起作用。警告:请注意,使用此设置,您将减少记录了给定步骤值的运行次数,只要至少有--min-runs-per-step。换句话说,减少的统计将在运行中改变。例如,如果您正在绘制错误曲线的平均值,那么该平均值的样本大小将从,比如说,10 减少到 4,如果在绘图过程中有 4 个模型的训练时间比其他模型长。使用时请务必记住这一点。-v/--version(可选):获取当前版本。
Python API
您还可以将 tensorboard_reducer 导入 Python 脚本或 Jupyter 笔记本以进行更复杂的操作。以下是一个使用所有主要函数 load_tb_events、reduce_events、write_data_file 和 write_tb_events 的简单示例,以帮助您入门
from glob import glob
import tensorboard_reducer as tbr
input_event_dirs = sorted(glob("glob_pattern/of_tb_directories_to_reduce*"))
# where to write reduced TB events, each reduce operation will be in a separate subdirectory
tb_events_output_dir = "path/to/output_dir"
csv_out_path = "path/to/write/reduced-data-as.csv"
# whether to abort or overwrite when csv_out_path already exists
overwrite = False
reduce_ops = ("mean", "min", "max", "median", "std", "var")
events_dict = tbr.load_tb_events(input_event_dirs)
# number of recorded tags. e.g. would be 3 if you recorded loss, MAE and R^2
n_scalars = len(events_dict)
n_steps, n_events = list(events_dict.values())[0].shape
print(
f"Loaded {n_events} TensorBoard runs with {n_scalars} scalars and {n_steps} steps each"
)
print(", ".join(events_dict))
reduced_events = tbr.reduce_events(events_dict, reduce_ops)
for op in reduce_ops:
print(f"Writing '{op}' reduction to '{tb_events_output_dir}-{op}'")
tbr.write_tb_events(reduced_events, tb_events_output_dir, overwrite)
print(f"Writing results to '{csv_out_path}'")
tbr.write_data_file(reduced_events, csv_out_path, overwrite)
print("Reduction complete")


哈希 对于 tensorboard_reducer-0.3.1-py2.py3-none-any.whl
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 0196a8ec49b3c4535fe42a13dd5407953622e169985fc0ad5f7528bdfba5afbf |
|
| MD5 | 4fa60e6dc2a116e64342777deaea3dba |
|
| BLAKE2b-256 | a4be8325bd474f40c49f47e9a2edce9a4cf4fe3babcaae001e43f591f14c59d7 |







