Python屏幕文本通用游戏翻译器

项目描述
pyugt - Python通用游戏翻译器



pyugt是一个用Python编写的通用游戏翻译器:它从您在屏幕上选择的区域捕获屏幕截图,使用OCR(通过Tesseract v5)提取字符,然后将它们输入到机器翻译器(包括多个后端)以显示翻译后的文本。
由于它直接在图像上工作,因此无需破解游戏或任何内容以访问文本。它也是跨平台的(支持Windows、Linux,实验性支持MacOSX)。
以下是一个演示
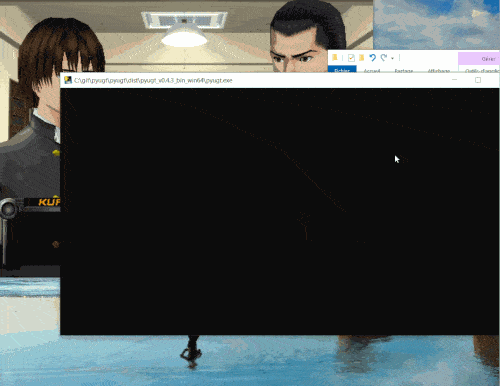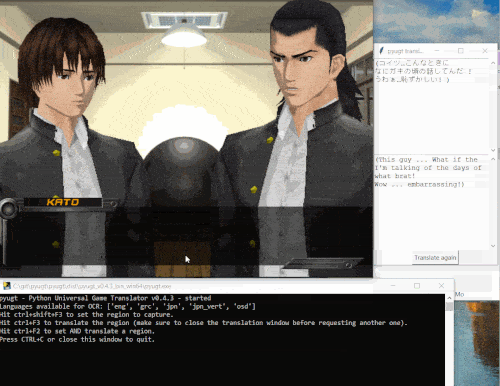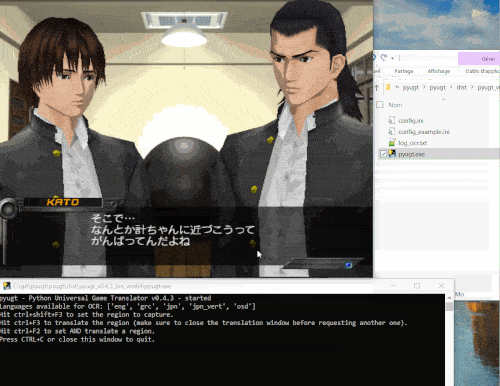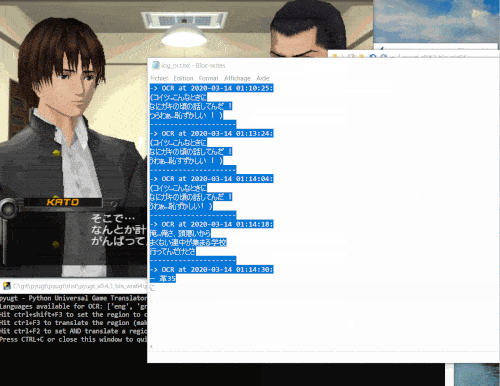
提供多种机器翻译后端:从免费的在线API(如Google Translate)到DeepL(免费或付费订阅),还有Argos Translate和OpenNMT提供的离线翻译器,无需网络访问即可直接在您的电脑上运行。
当然,由于翻译是由机器完成的,不要期望翻译得非常完美,但对于没有翻译的电子游戏,它足以理解大意并能够玩。
该软件对于人工翻译者也有用,因为可以在配置文件中启用OCR文本的记录,这样所有捕获的文本都将保存到日志文件中,以后可以用作人工翻译的源文件。
该软件不仅限于游戏,还可以应用于显示屏幕上文本的任何事物。
本软件灵感来源于Seth Robinson在UGT(通用游戏翻译器)上的出色工作。
如何安装和更新
-
首先,安装Tesseract v5,安装程序由UB Mannheim提供。请确保安装您想要翻译的额外语言(例如,日语,支持水平和垂直的假名)。
-
然后安装pyugt
-
对于Windows操作系统,有一个预包装的二进制文件您可以从这里下载(对于64位请查找pyugt_vx.x.x_bin_win64.zip,对于32位请查找win32)。
-
对于其他平台或如果您想从源代码运行,需要安装Python解释器。《Anaconda》是一个不错的选择,而《Miniconda3》是一个更小的替代品,也可以使用。
然后,安装此软件
pip install --upgrade pyugt对于想要本地运行的开发者,在从GitHub下载存档后,解压缩到任何位置,进入文件夹并输入
python setup.py develop请注意,该软件在Windows 10 x64和Python 3.10(Anaconda)以及3.11上进行了测试。其他用户在Linux上进行了测试,但不是定期测试。
-
Tesseract的语言包可以直接从安装程序下载。离线机器翻译器Argos的语言包在用户需要时即时下载,但也可以从此索引预先下载,该索引还提供了IPFS链接,以防即时下载失败。
如何使用
-
首先,您需要配置配置文件
config.ini。软件附带了一个示例配置文件,应在Windows上运行良好,但在其他平台或某些情况下,您可能需要编辑它,特别是设置Tesseract二进制文件的路径。配置文件还允许您更改热键和要截取屏幕的显示器,以及其他一些事情,如源语言和目标语言(默认情况下,源语言是日语,目标语言是英语)。 -
然后,您可以从终端/控制台启动脚本
pyugt
或者
python -m pyugt
-
然后,使用热键选择要捕获的区域(默认热键:
CTRL+SHIFT+F3)。所选区域不需要非常精确,但需要包含要翻译的文本。 -
最后,使用热键翻译所选区域中显示的内容(默认:
CTRL+F3)。这将显示一个包含原始文本和翻译文本的窗口。根据需要重复操作,无需重新选择要翻译的区域。 -
提示:如果软件在识别字符时遇到困难(你得到的是乱码和非字母字符而不是单词),首先尝试使用CTRL+F2重新定义区域,并确保区域包括所有文本和一些边距,但背景不要太多(文本周围越紧,OCR就越不会被背景混淆,这会有很大帮助!)你可以使用区域选择和翻译快捷键以流线化的方式完成这两项操作(默认:
CTRL+F2)。 -
提示2:尝试使游戏屏幕更大。字符越大,OCR的工作就越容易。
-
提示3:您可以使用
-c或--config参数指定配置文件的路径:pyugt -c <path_to_config_file> -
提示4:在翻译框中,您可以手动编辑OCR识别的文本,并点击“再次翻译”按钮强制进行新的翻译。当OCR错误检测到非字母字符时,这可能很有用。
-
提示5:如果您使用蓝光过滤软件,请在使用OCR之前全部禁用它们,这将提高对比度,从而提高准确性。
重要提示:该软件仍在alpha阶段(并且可能永远处于这个状态)。它是正在运行的,但有时快捷键会出错,不再工作。如果发生这种情况,请将焦点放在Python控制台上,然后按CTRL+C强制退出应用程序,然后再次启动它。选定的区域已保存在配置文件中,因此您不必每次都重做此步骤。
选项
这是一个示例配置文件,包含对各种附加选项的注释(例如OCR文本和翻译文本的日志)
[USER]
# User parameters to configure the pyUGT program.
# Note that parameters can be modified on-the-fly while the app is running, and changes will be reflected in realtime. For example, translators can be changed on-the-fly.
# Path to Tesseract v5 binary. Easily install it from UB Mannheim installers: https://github.com/UB-Mannheim/tesseract/wiki
path_tesseract_bin = C:\Program Files\Tesseract-OCR\tesseract.exe
# Source language to translate from, for OCR. Both the Optical Recognition Character and the translator will search specifically for strings in this language, this reduces the amount of false positives (eg, translating strings in other languages that are more prominent or bigger on-screen). Language code can be found inside Tesseract tessdata folder (depends on what languages you chose in the installer).
lang_source_ocr = jpn
# Source language to translate from.
lang_source_trans = ja
# Target language to translate to. Must be a language code for the target machine translator: either Google Translate language code (NOT a Tesseract code! See: https://readthedocs.org/projects/py-googletrans/downloads/pdf/latest/ ) or DeepL code (eg, en for Google Translator, Argos and most others, or EN-US for DeepL).
lang_target = en
# Machine translator library to use. Can be online_free to use free online APIs but which can be throttled (eg, Google Translate, DeepL free, Baidu, etc) ; deepl to use DeepL API with your own authkey (not throttled but limited number of translations in free plan, then need to pay for more, but it's best in class japanese->english machine translator) ; offline_argos for offline translation using Argos based on OpenNMT, which produces less accurate translations but is free, unlimited and does not require an internet connection.
translator_lib = online_free
# If online_free is the selected translator_lib, we can specify here the translator service to use. For a list of available services, see: https://github.com/UlionTse/translators#more-about-translators
translator_lib_online_free_service = google
# If translator_lib is set to deepl, the API authorization key must be set here
translator_lib_deepl_authkey = fa14ef6c-d...
# Hotkey to set the region on screen to capture future screenshots from. The region does not need to be precise, but must contain the region where text is likely to be found.
hotkey_set_region_capture = ctrl+shift+F3
# Hotkey to translate from the selected region
hotkey_translate_region_capture = ctrl+F3
# Hotkey to set a region AND translate it directly on mouse click release. This is useful for games where the contrast between the text and background is bad (eg, transparent dialog box), so reselecting a tight region for each dialogue may yield better results, this is a faster way to do that with one shortcut instead of 2.
hotkey_set_and_translate_region_capture = ctrl+F2
# Hotkey to preview in a window the postprocessed screenshot that is fed to OCR, this helps with tweaking parameters here and see how it improve the text contrast
hotkey_show_ocr_preview = ctrl+p
# On which monitor the screen region capture should display? If you have only one screen, leave this to 0 (first monitor)
monitor = 0
# Save all OCR'ed text into a log file? Set a path or file name different than None to activate (exemple: log_ocr = log_ocr.txt). This can be very useful for human translators to gather game text data.
log_ocr = None
# Save all translated text into a log file? Set a path or file name different than None to activate (exemple: log_translation = log_trans.txt).
log_translation = None
# Only capture text by OCR without translating (set this value to True, else to also translate set to False). This is useful if you only want to use pyugt as a OCR tool, or don't want to send your OCR'ed text to Google.
ocr_only = False
# Remove line returns automatically, so that we consider all sentences to be one (this can help the translator make more sense because it will have more context to work with).
remove_line_returns = True
# Preprocess screenshots to improve OCR?
preprocessing = True
# Preprocessing filters to apply (set to None to disable, else input a list of strings with strings being methods of PILLOW.ImageFilter). Example: ['SMOOTH', 'SHARPEN', 'UnsharpMask']
preprocessing_filters = ['SHARPEN']
# Preprocessing binarization of image? Set to None to disable, else set a value between 0-255 (255 being white)
preprocessing_binarize_threshold = 180
# Preprocessing invert image (if text is white, it's better to invert to get black text, Tesseract OCR will be more accurate). Set to False to disable.
preprocessing_invert = True
# Show debug information
debug = False
缺点 & 优点
与UGT相比,翻译的文本不是覆盖在原始文本的截图上。这可能可以通过Tesseract提供的某些函数(如image_to_boxes()或image_to_osd()或image_to_data())来完成。如果有人想尝试,PR总是受欢迎!
UGT还可以直接选择并翻译活动窗口。我们放弃了这个特性,因为它依赖于平台,因此区域选择似乎是最可靠和跨平台的屏幕捕获实现方式,即使它增加了一个额外的步骤。
另一方面,我们的方法有几个优点
-
它是跨平台的(目前是Windows和Linux,MacOSX应该也以实验性方式支持,但全局快捷键有时会失败,因为
keyboard模块只为这个平台提供实验性支持), -
我们使用Tesseract,这样OCR就是本地完成的(而不是通过Google Cloud Vision API),所以我们只发送更小的文本,从而更便宜(通常是免费的),一个很大的优点是可以自由地将游戏窗口调整到更大的大小,更大的字符可以提高OCR识别,而且由于没有图像传输,不需要下采样/质量降低,
-
可以选定区域,因此可以消除可能使OCR混淆的不必要屏幕对象(更新:UGT现在也实现了此功能:tada:),
-
我们强制执行源语言和目标语言,这样OCR和翻译器都知道应该期待什么,而不是尝试自动检测,这可能会失败,尤其是当有可能会用另一种语言或字符形式(例如,不是汉字)书写的名称时。
类似项目
-
Universal Game Translator(Windows,开源)- 本项目的灵感来源。
-
ByJacob的pyUGT分支(Windows,Linux,MacOS,开源)- 本项目的分支,但实现的是Marian Machine Translation离线翻译器而不是Argos-Translate。MMT有时比Argos-Translate更准确,但速度更慢,占用空间更多。然而,这两个离线翻译器都比DeepL在线翻译器准确度低。
-
Capture2Text(Windows,开源)- OCR屏幕文本,但没有翻译。
-
OwlOCR (MacOSX, 免费软件) - 与Capture2Text类似,屏幕文字OCR,不提供翻译。
-
Sugoi Japanese Translator 结合(视觉小说OCR)[https://visual-novel-ocr.sourceforge.io/] 由同一作者提供:提供与pyUGT类似的功能,但为闭源,因此无法改进。另外,不清楚使用了哪种OCR后端。
-
Translator++,一款免费但闭源的软件,可翻译非模拟游戏,可以访问文本,可以利用自动机器翻译。
许可证
该软件由Stephen Larroque制作,并使用MIT公共许可证发布。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。
源代码分发
构建分发
pyugt-1.0.10.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 616deb51314d9e044df416bf166090845af19d2c820967fae72cc6f1e4fa4894 |
|
| MD5 | 6de7a72369dc784f724d2b89b2fdb003 |
|
| BLAKE2b-256 | ff997005314605cf5c5bc512031c9901ef9900df294f2d8ef969c5983274dfe2 |
pyugt-1.0.10-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 45998cc8521c79979b4a242587729f1f3699bbcd840b0beede53fdc7bf35bf80 |
|
| MD5 | 626f91d9448caeca738ef7ed5eba925f |
|
| BLAKE2b-256 | b74229c21cd544204f3ac66dfd928871c12f3254b9ad6a15cc6bdf07259dadf6 |







