一个用于与napari一起使用,根据对象的属性进行聚类的插件





项目描述
napari-clusters-plotter










一个根据对象的属性进行聚类的napari插件。

注意:目前除了以下描述的标签层之外的其他层的支持仅可在开发版本中获取。此说明将在新版本发布后删除。
跳转至
使用方法
起始点
根据对象的属性进行聚类时,起始点是一个灰度值图像和另一个包含在.features属性中的派生测量的层。以下是支持的层类型及其可能表示的示例
标签层包含表示对象分割的标签图像。点层包含表示对象质心坐标的点。表面层包含表示对象分割的表面。标签层包含表示跟踪结果的时序标签图像,其中每个标签数字/颜色对应一个唯一的跟踪ID。
查看示例数据文件夹以了解如何使用代码加载数据。
1. 包含分割结果的标签层
标签图像不应包含标签为0的对象,因为这些对象不能与背景分离,在许多图像中背景也是0,在执行聚类时会引起错误行为。对于分割对象,例如,您可以使用napari插件中的Voronoi-Otsu标记方法。
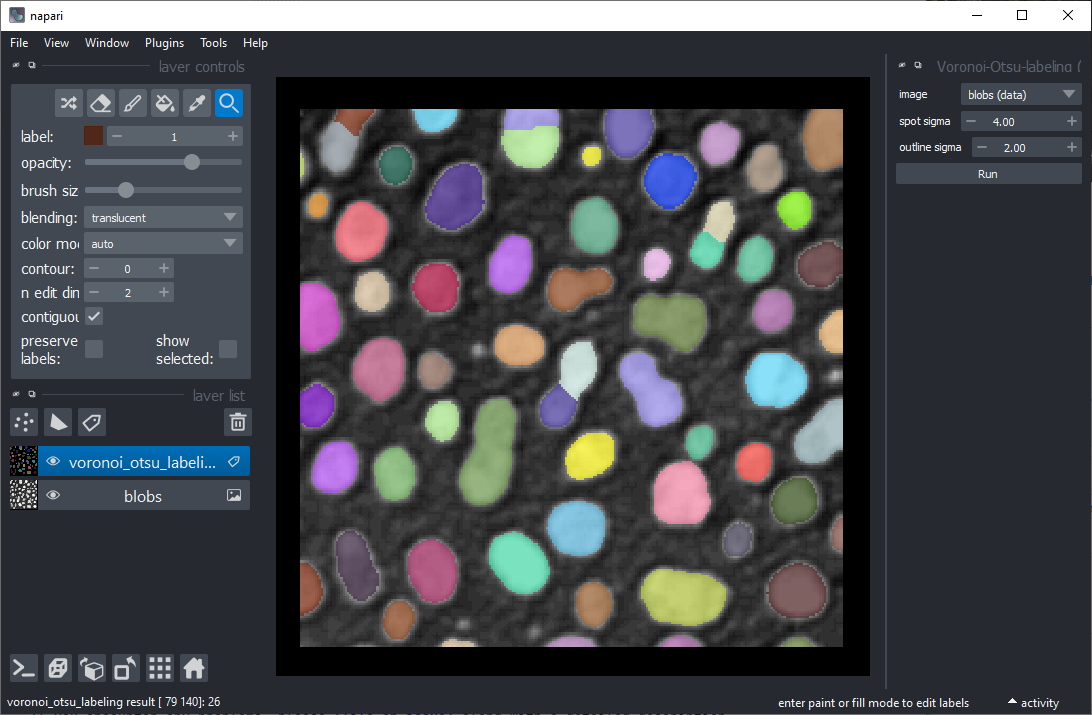
如果您有2D时间间隔数据,需要使用菜单工具 > 通用 > 将3D堆栈转换为2D时间间隔(时间切片器)(文档)将其转换为合适的形状。
测量
第一步是从标记的图像和灰度值图像中的相应像素中导出测量值。使用菜单工具 > 测量表 > Regionprops (scikit-image, nsr)进入测量小部件(文档)。选择图像、相应的标签图像和分析的测量值,然后点击运行。将打开一个包含测量的表格,然后您可以保存和/或关闭测量表。在此阶段,建议关闭表格和测量小部件以释放空间用于后续步骤。
您还可以加载自己的测量值。您可以使用菜单工具 > 测量 > 从CSV加载(nsr)来这样做。如果您加载自定义测量值,请确保有一个指定哪个测量值属于哪个标记对象的label列。请确保避免使用标签0,因为这被保留用于背景。时间间隔数据的表需要包含一个名为frame的额外列。
绘图
一旦在已分析的标签层中保存了测量值,您可以使用菜单工具 > 可视化 > 绘制测量值(ncp)绘制这些测量值。
在此小部件中,您可以选择已分析的标签层以及应绘制在X轴和Y轴上的测量值。点击绘制以在绘图区域绘制数据点。
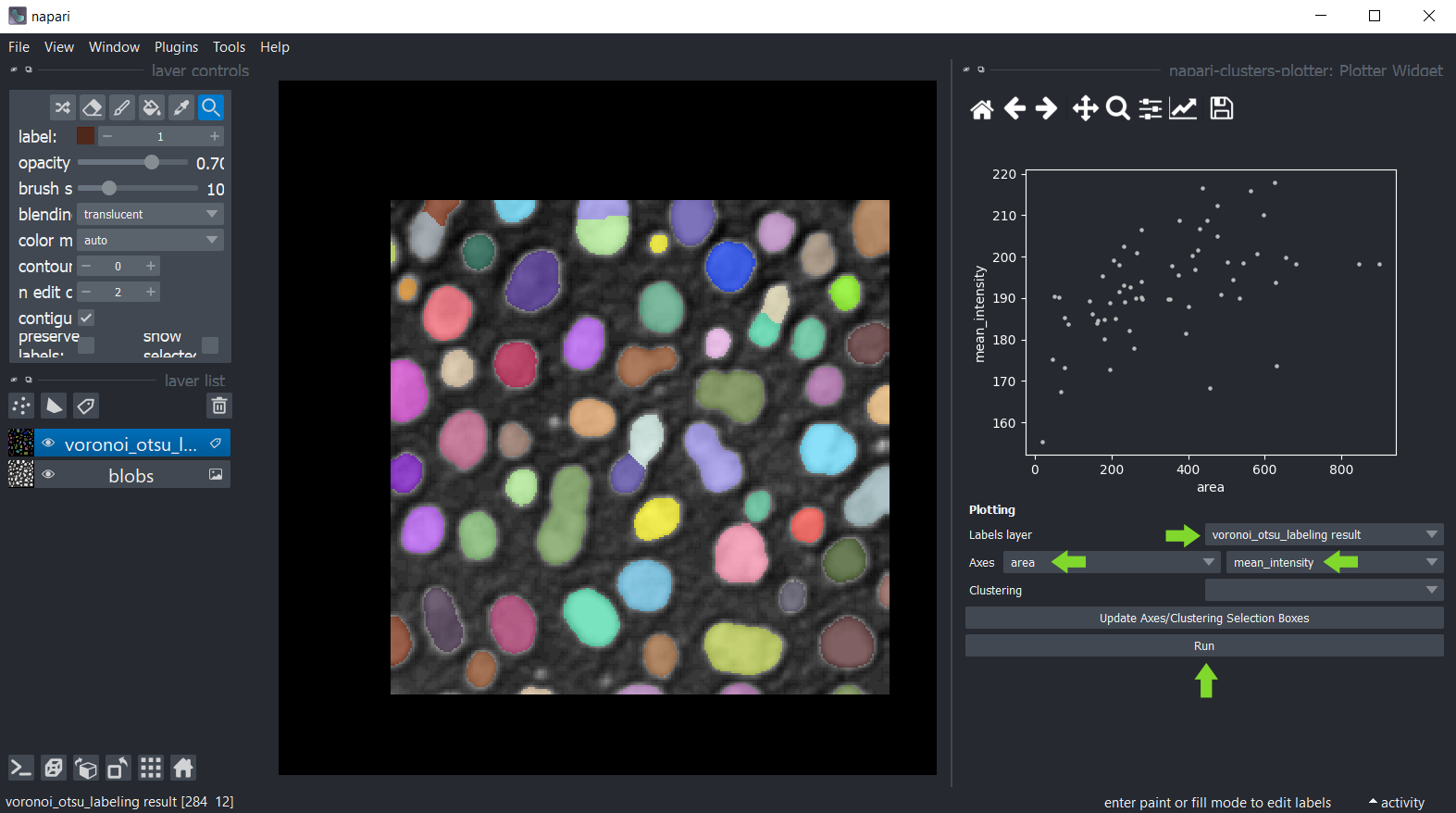
在高级选项中,您还可以选择柱状图类型,这将可视化2D柱状图。如果数据点非常多,建议使用2D柱状图可视化。
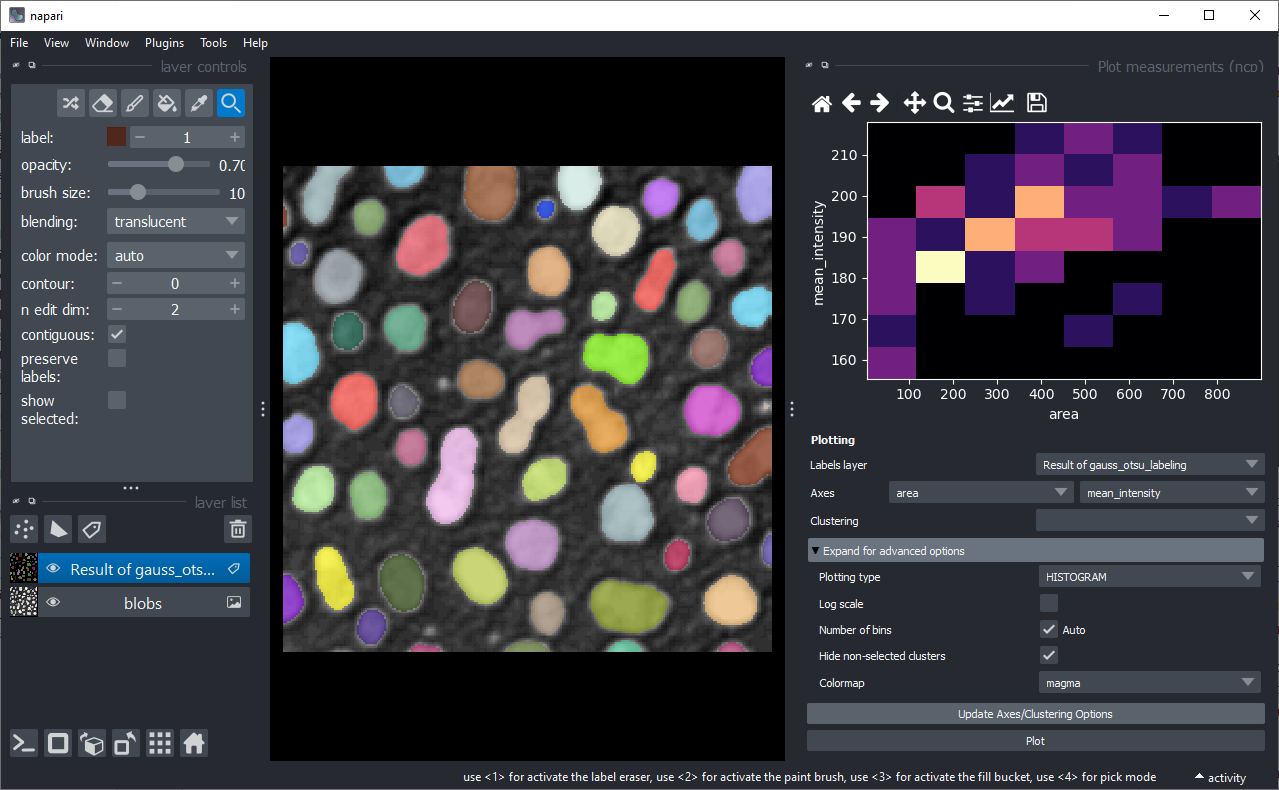
如果您为X轴和Y轴选择相同的测量值,则将显示柱状图。
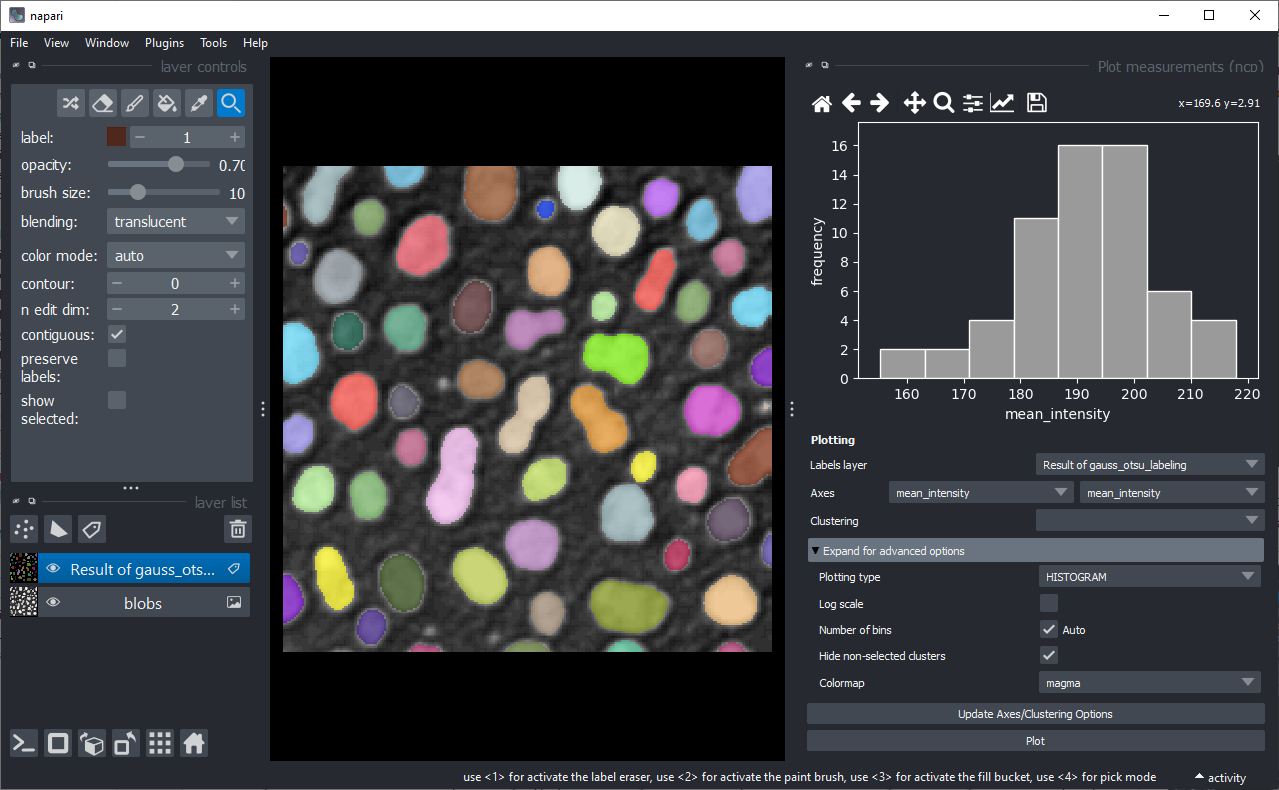
在高级选项中,您还可以找到复选框,以确定是否隐藏未选择的数据点(以灰色显示)或自动将其聚类为另一个簇。
手动聚类
您可以在图中手动选择一个区域。要使用套索(自由手绘)工具,请使用左键单击,要使用矩形,请使用右键单击。结果的手动聚类也将可视化在原始图像中。为了优化图像中的可视化,请关闭已分析的标签层的可见性。

在标注绘图区域时按住SHIFT键,可以手动选择多个簇。

保存手动聚类
可以通过转到工具 > 测量 > 显示表(nsr)并点击另存为csv来保存手动聚类结果。保存的表将包含一个“MANUAL_CLUSTER_ID”列。每次手动选择不同的簇时,此列都会被覆盖。
时间推移分析
当您绘制时间推移数据集时,您会注意到图看起来略有不同。当前时间框架的数据点以亮色突出显示,您可以在您通过时间导航时看到数据点在图中移动。

您还可以使用套索工具手动选择组,并按帧绘制测量值,以查看组随时间如何表现。此外,您还可以在时间中选择一个组,并查看数据点在另一个特征空间中的位置。

如果您有来自跟踪数据的自定义测量值,其中每一列指定了特定时间点的轨迹的测量值而不是标签,则不应添加frame列。检查以下内容,了解跟踪数据和特征应该是什么样子。
2. 带坐标的点层
Points层通常包含感兴趣对象的坐标(例如,对象质心)。
要获取这些坐标,您可以使用斑点检测算法(请参阅此处使用scikit-image的参考,此处使用pcylesperanto的参考,以及此处用于spotflow插件的参考),或者如果您有分割结果,则可以使用对象质心作为坐标。最后一种方法可以通过napari-process-points-and-surfaces插件中的工具 > Points > 从标签质心创建点(nppas)来完成。

您可以通过将它们分配给Points层的.feature属性来将这些对象特征加载到这些点上,如下面的Python代码所示
points_layer.features = features_table
表中的行数应与点的数量匹配。
您可以使用以下部分解释的相同算法对这些特征进行聚类,或手动聚类,并相应地着色点,如下所示

请参阅此笔记本了解如何从代码中加载数据。
3. 带分割结果的表面层
Surface层可以包含表示分割结果的表面。
要从包含分割结果的标签图像生成此表面,一个经典算法是Marching Cubes。它在scikit-image中可用,您也可以通过napari-process-points-and-surfaces插件中的工具 > 表面 > 从任何标签创建表面(Marching Cubes,scikit-image,nppas)应用它。选择您想将其转换为表面的标签ID,然后点击运行

您将注意到将创建表面层。

您可以通过napari-process-points-and-surfaces插件中的工具 > 测量表 > 表面质量表(vedo,nppas)从表面的顶点导出定量测量。

与绘图器(工具 > 可视化 > 绘制测量(ncp))相同的方式,可以绘制和分类表面顶点的测量值。

查看此笔记本,了解如何从代码中加载数据。
4. 标签层与跟踪结果
标签层也可以用来显示跟踪结果。
这些笔记本展示了如何从Mastodon中加载和格式化跟踪特征,使其与napari-clusters-plotter兼容。
例如,如果您有一个时间间隔标签图像,其中每个标签数字代表一个唯一的跟踪ID,您可以将跟踪特征加载到这个标签层,并使用绘图器对它们进行聚类。在下面的'gif'中,跟踪层并未用于聚类,只是作为方便展示。目前尚不支持跟踪层。

查看此笔记本,了解如何从代码中加载数据。
降维
为了更深入地了解您的数据,您可以使用这些算法来降低测量的维度:
要应用它们到您的数据,使用菜单工具 > 测量后处理 > 降维(ncp)。选择分析的标签图像,在下面的列表中,选择所有要降维的测量。默认情况下,所有测量都选中在框中。您可以通过悬停在问号上或单击它们来读取有关这两个算法参数的更多信息。完成选择后,点击运行,片刻后,测量表将重新出现,包含代表数据集降维的额外两列。这些列自动保存到标签层,并可以由其他插件进一步处理。
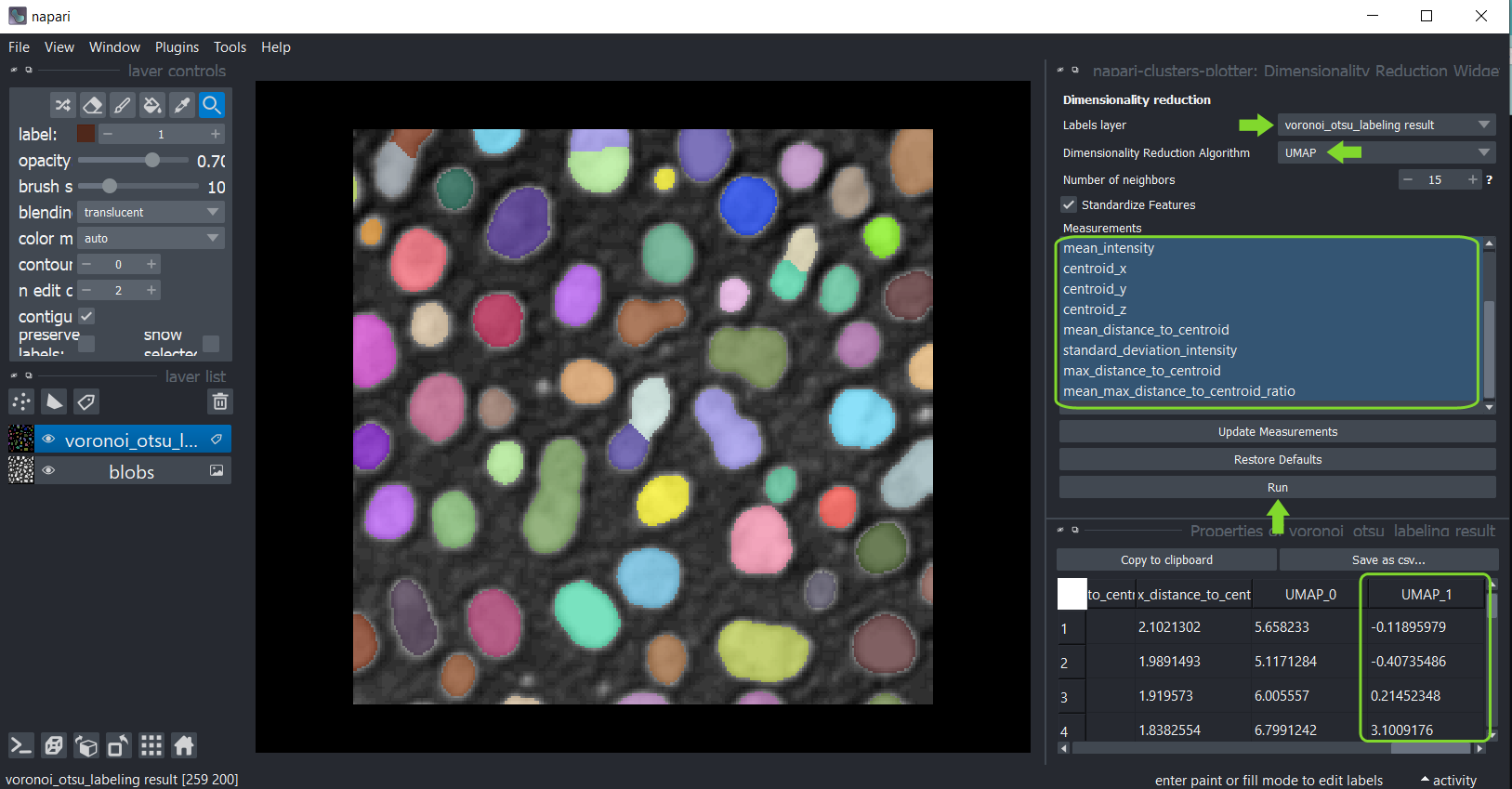
之后,您可以再次保存和/或关闭表格。
聚类
如果如上所示的手动聚类不是选项,您可以使用这些实现的算法自动聚类您的数据:
因此,点击菜单工具 > 测量后处理 > 聚类(ncp),选择分析的标签层。选择要聚类的测量,例如,仅选择仅的UMAP测量。选择聚类方法KMeans并点击运行。测量表将重新出现,包含包含每个数据点聚类ID的额外列ALGORITHM_NAME_CLUSTERING_ID。
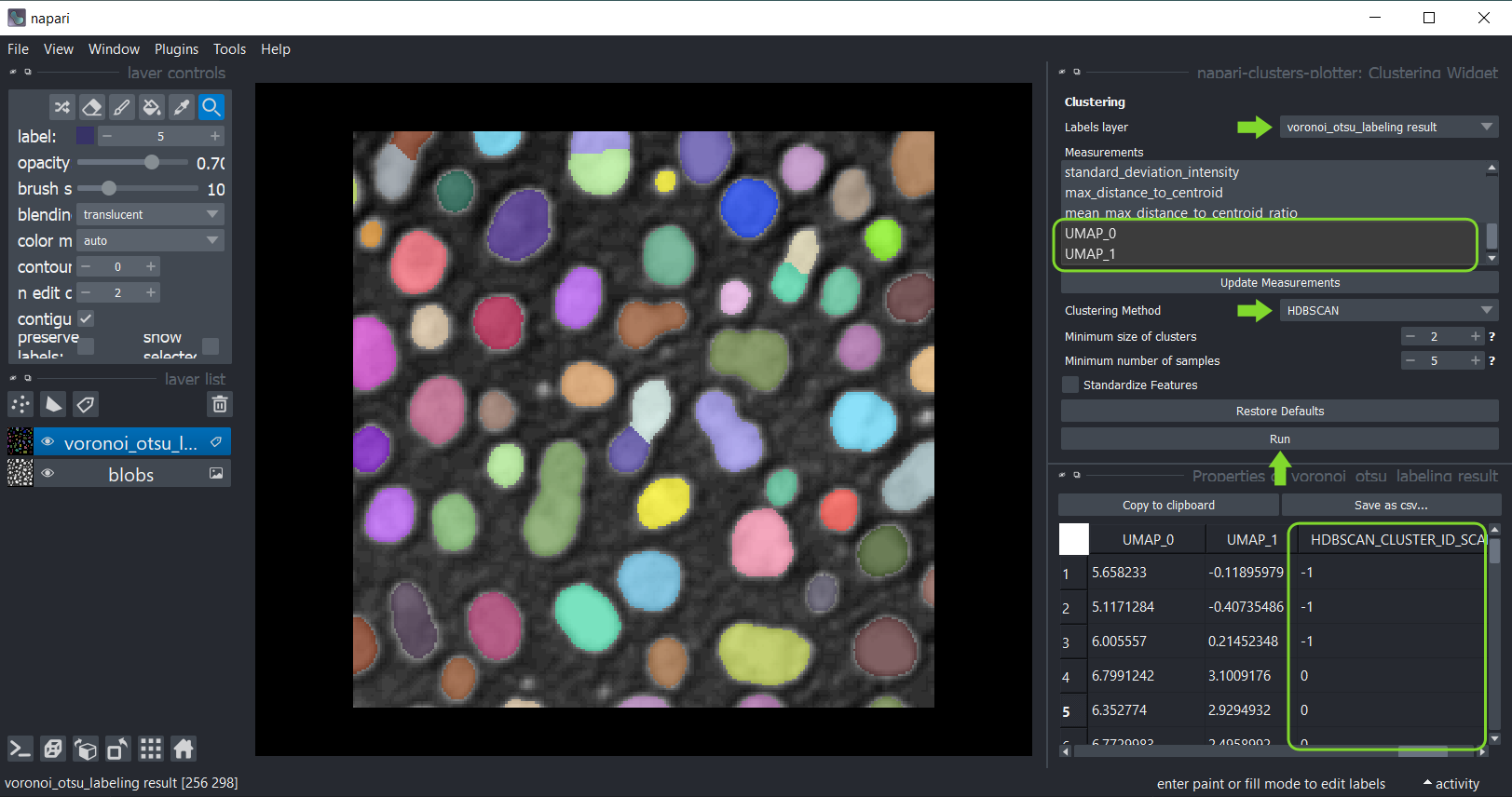
之后,您可以保存和/或关闭表格。
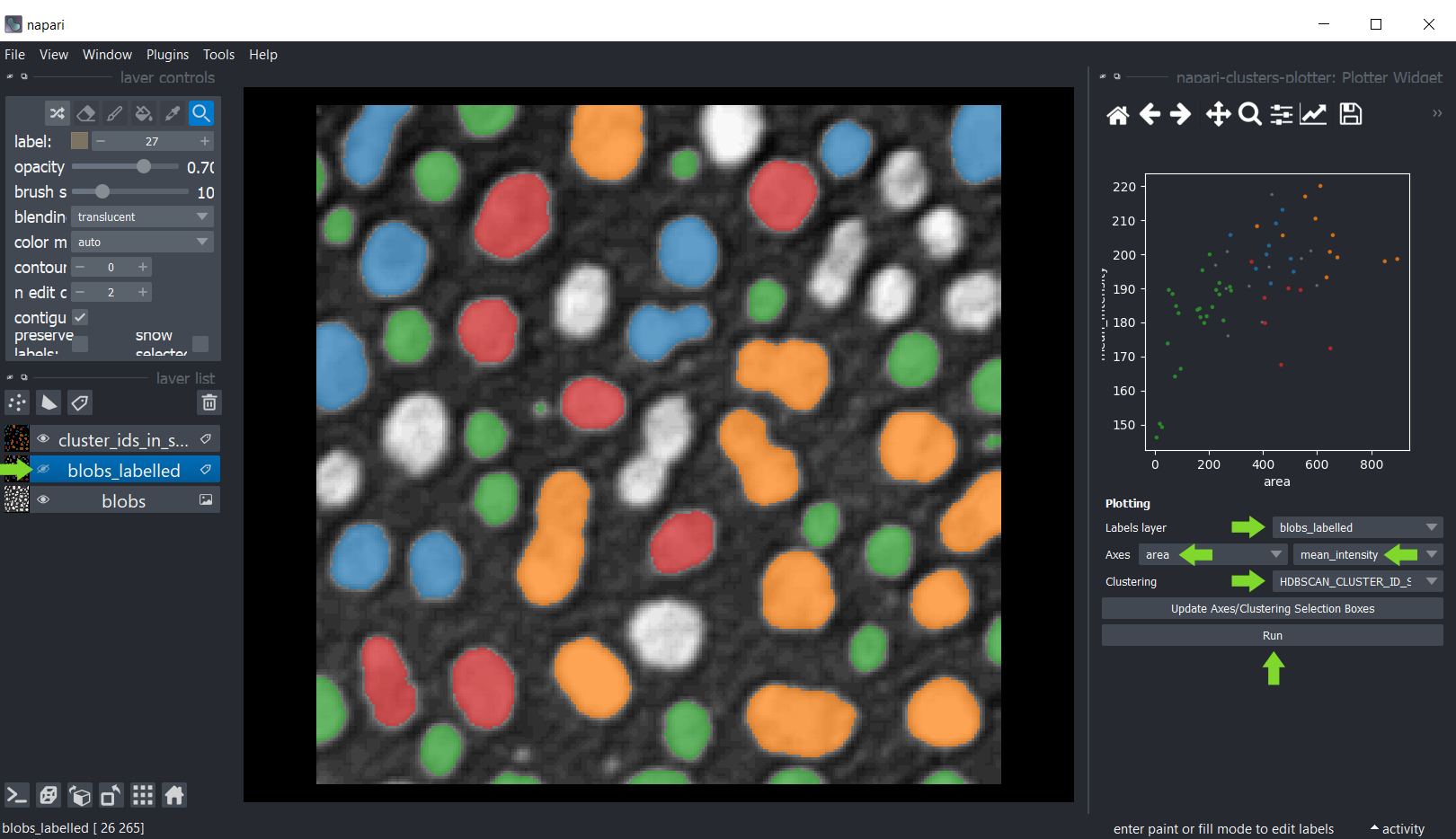
绘制聚类结果
使用菜单 工具 > 可视化 > 绘制测量(ncp) 返回绘图小部件。选择 UMAP_0 和 UMAP_1 作为 X 轴和 Y 轴,将 ALGORITHM_NAME_CLUSTERING_ID 作为 聚类,然后点击 绘图。
安装
Devbio-napari 安装
安装此插件最简单的方法是安装 devbio-napari 插件集合。napari-clusters-plotter 是其中的一部分。
最小安装
-
获取一个 Python 环境,例如通过 mini-conda。如果您之前从未使用过 mamba/conda 环境,请首先遵循此博客文章中的说明 在此。
-
创建一个新的环境,例如
mamba create --name ncp-env python=3.9
- 使用 conda 激活新环境
mamba activate ncp-env
mamba install -c conda-forge napari
之后,您可以通过 conda 安装 napari-clusters-plotter
mamba install -c conda-forge napari-clusters-plotter
安装故障排除
错误:无法为使用 PEP 517 构建的 wheel 构建 hdbscan,无法直接安装
如果您在安装时使用了 pip,可能会发生这种情况。为了解决这个问题,在安装插件之前,请先使用 conda 安装 hdbscan
mamba install -c conda-forge hdbscan
ValueError:numpy.ndarray 大小已更改,可能表示二进制不兼容。从 C 标头期望 96,从 PyObject 获取 88
与上述错误类似,此错误可能在通过 pip 或错误顺序导入 hdbscan 时发生。可以通过以下顺序通过 conda 分别安装软件包来修复此错误
mamba install -c conda-forge napari hdbscan
pip install napari-clusters-plotter
贡献
非常欢迎贡献。可以使用 pytest 运行测试,请在提交拉取请求之前确保覆盖率至少保持不变。
许可
在 BSD-3 许可证的条款下分发,“napari-clusters-plotter” 是免费和开源软件
致谢
该项目得到了德国卓越战略 - EXC2068 - 德累斯顿工业大学“生命物理”卓越集群的支持。该项目部分得益于 Chan Zuckerberg Initiative DAF 的赠款,该赠款是硅谷社区基金会的受托基金,赠款编号为 2021-240341(Napari 插件加速器赠款)。
问题
如果您遇到任何问题,请 提交一个问题 并附上详细描述。


下载文件
下载您平台的文件。如果您不确定选择哪个,请了解更多关于 安装软件包 的信息。
源分布
构建分布
napari_clusters_plotter-0.8.1.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | eef3a5e2afddf57808c8e61f5fc5f4c530af89c72721c381d4795bcc4606f678 |
|
| MD5 | e15a0757f837c74a9d491cbcf8022b43 |
|
| BLAKE2b-256 | cac0c544ebb10af9f91e641dab673ab8cc41e4a470f83f932c9d711363b8706b |
napari_clusters_plotter-0.8.1-py3-none-any.whl 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 9fbdac30a719561aea8468ce1687a7135a804aff7b7ebdf355a5055ee5acdd68 |
|
| MD5 | eeddce93c5774877865cdbbe86d13dfe |
|
| BLAKE2b-256 | 968a4e098348948aae376dc2878374bdb5882f23738bc1fc367e7749c95547c6 |