使用基于OpenCL的随机森林分类器进行像素和标签分类

项目描述
napari-accelerated-pixel-and-object-classification (APOC)








clesperanto 与 scikit-learn 结合,在 GPU 上使用 OpenCL 在 napari 中对图像中的像素和对象进行分类。
要在Python中使用加速像素和对象分类器,请查看apoc。在这个笔记本中解释了如何从图像和标签掩码文件夹对中训练分类器。要在Fiji中使用clij2执行APOC的像素和对象分类器,请阅读相应Fiji插件的文档[对应Fiji插件文档]。表格分类器和对象合并器目前与Fiji不兼容。
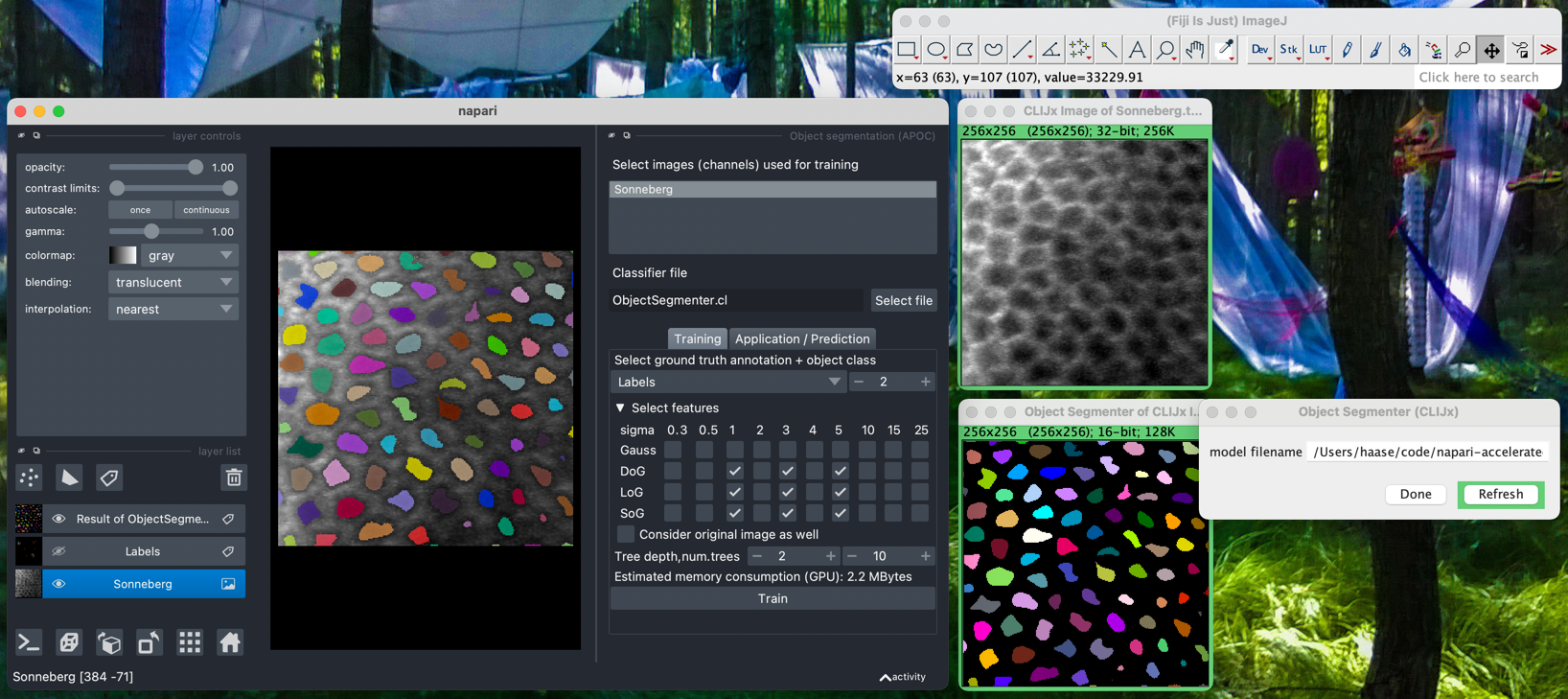
使用方法
对象和语义分割
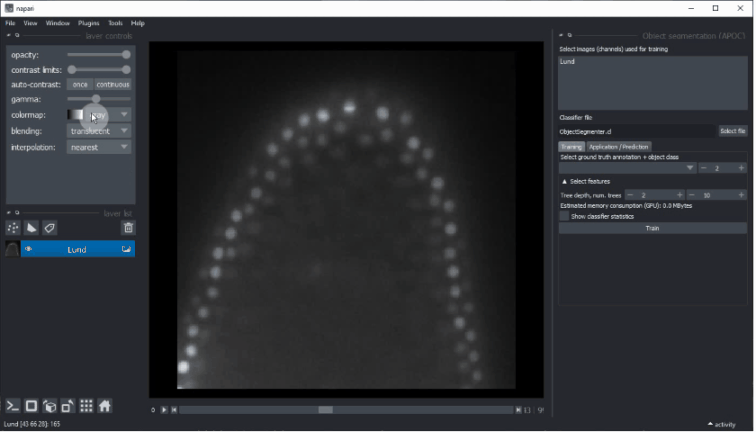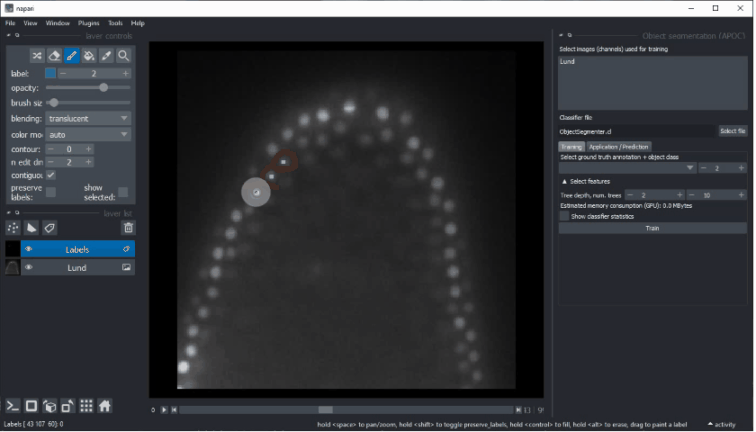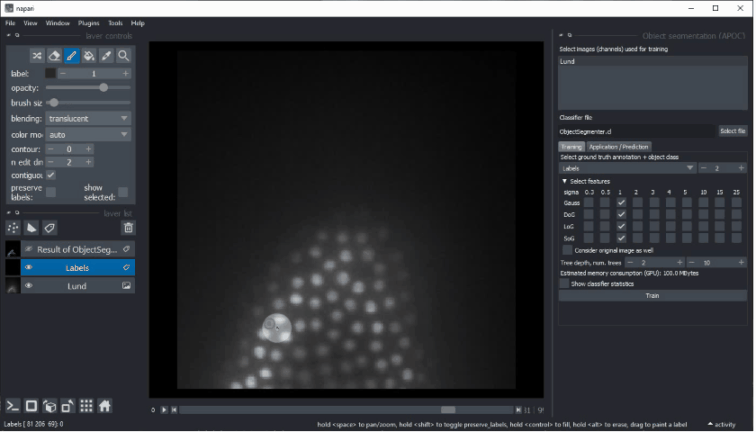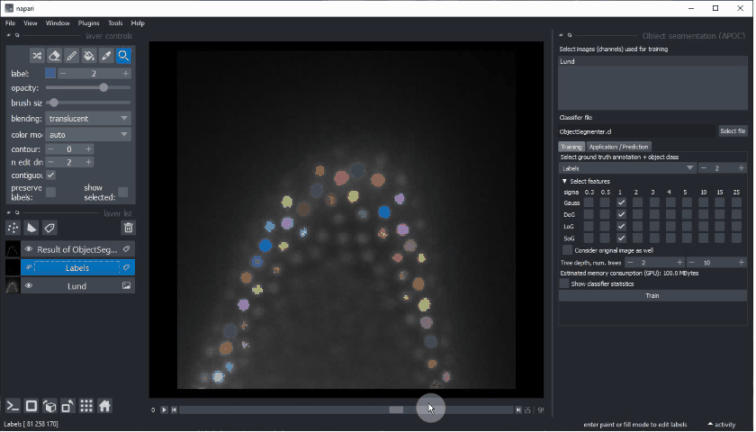
起点是napari,至少包含一个图像层和一个标签层(您的注释)。
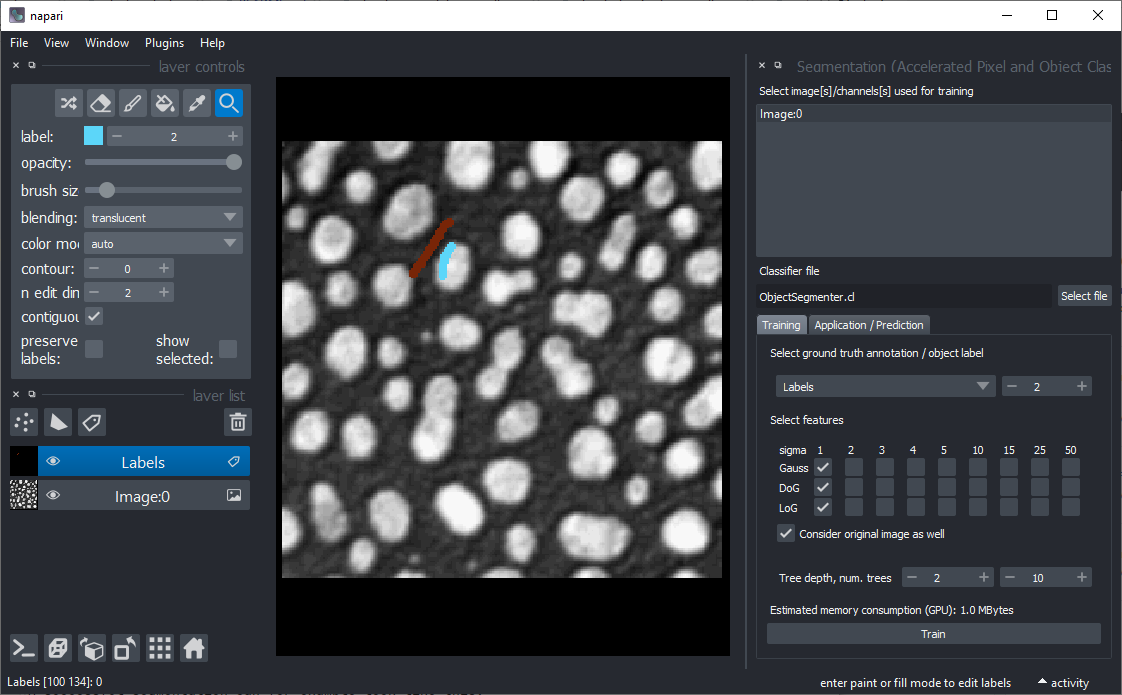
您可以在工具 > 分割/标记中找到对象和语义分割。启动这些工具时,将显示以下图形用户界面。
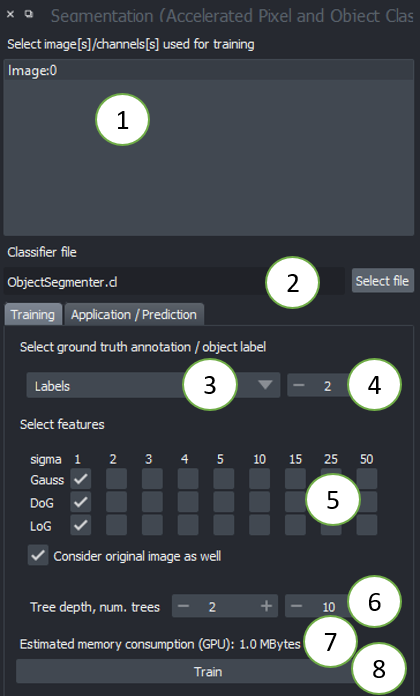
- 选择一个或多个图像进行训练。这些图像将被视为多个通道。因此,它们需要在空间上相关联。从显示不同场景的多个图像中训练(尚不支持从图形用户界面中)。
- 选择一个文件来保存分类器。如果文件已存在,它将被覆盖。
- 选择地面真实注释标签层。
- 选择哪个标签对应于前景(在语义分割中不可用)
- 选择应考虑进行分割的特征图像。如果分割看起来像素化,请尝试增加所选的sigma值并取消勾选
考虑原始图像。 - 树深度和树的数量允许您微调如何处理具有不同特征的区域。这些数字越高,分割所需的时间越长。如果您使用许多图像和许多特征,则可能需要较高的深度和树的数量。(有关随机森林分类器的
max_depth和n_estimators,请参阅scikit-learn文档。) - 内存消耗估计允许您根据您的GPU硬件调整配置。还要考虑希望使用您的分类器的其他人的GPU硬件。
- 配置完成后,请单击“运行”。如果第一次执行后分割不合适,请考虑微调地面真实注释并再次尝试。
成功的分割可能看起来像这样
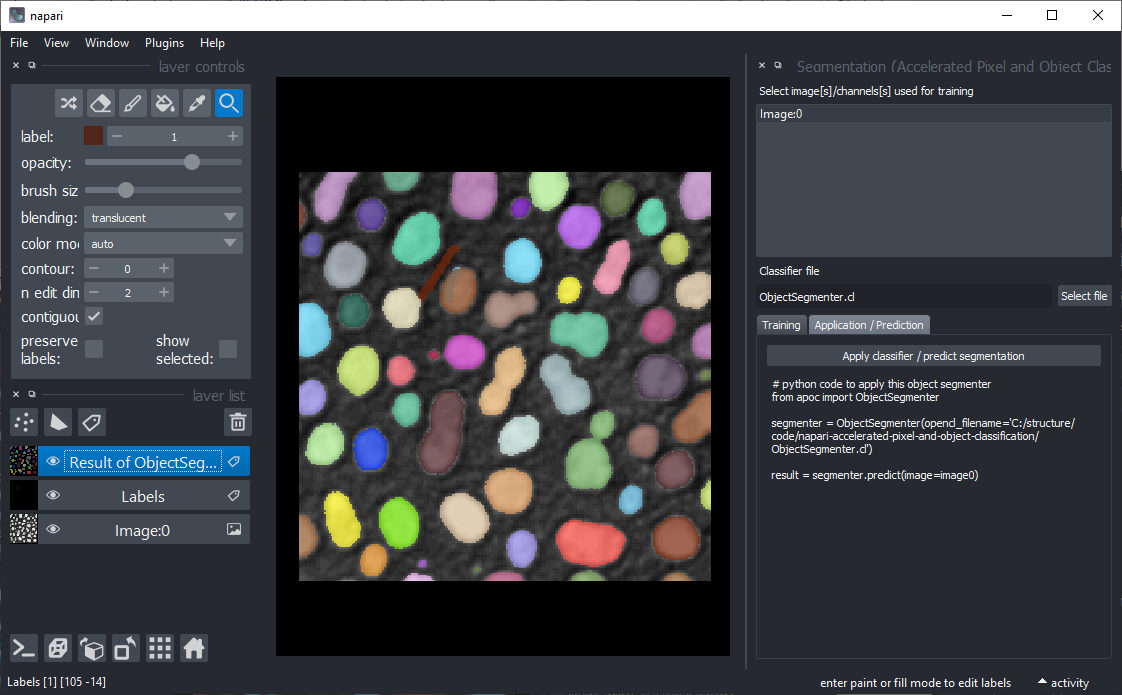
成功训练分类器后,单击“应用/预测”标签。如果您再次应用分类器,将生成Python代码。您可以使用此代码将相同的分类器应用于图像文件夹。如果您是新手,请查看这个笔记本。
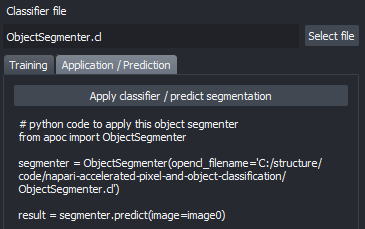
预训练的分类器可以从脚本中应用,如示例笔记本所示,或从工具 > 分割/标记 > 对象分割(应用预训练,APOC)。
与napari-assistant集成
还可以使用napari-assistant将预训练模型组装到工作流程中。您可以在筛选、标签和标签筛选器类别中找到APOC操作。
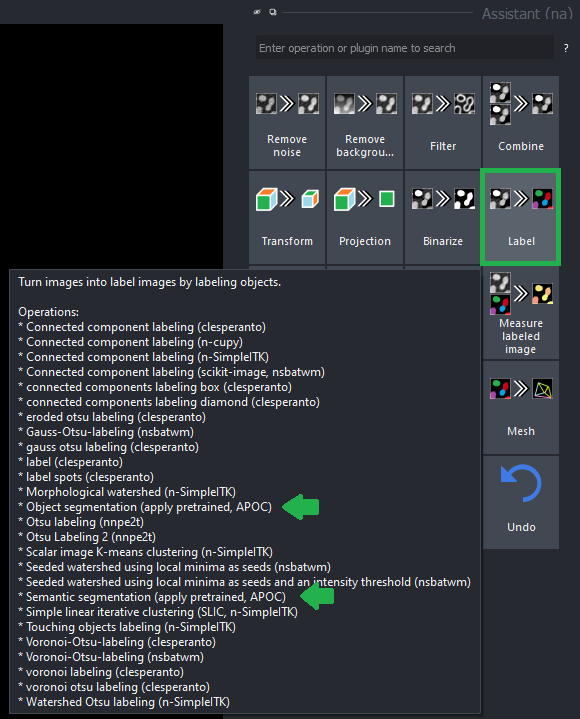
语义分割
用户还可以生成语义分割标签图像,其中标签标识符对应于像素已分配到的类别。该工具可在菜单工具 > 分割/标记 > 语义分割(APOC)中找到。它的工作方式类似于对象分割器,只是不需要指定对象对应的类别标识符。

概率图
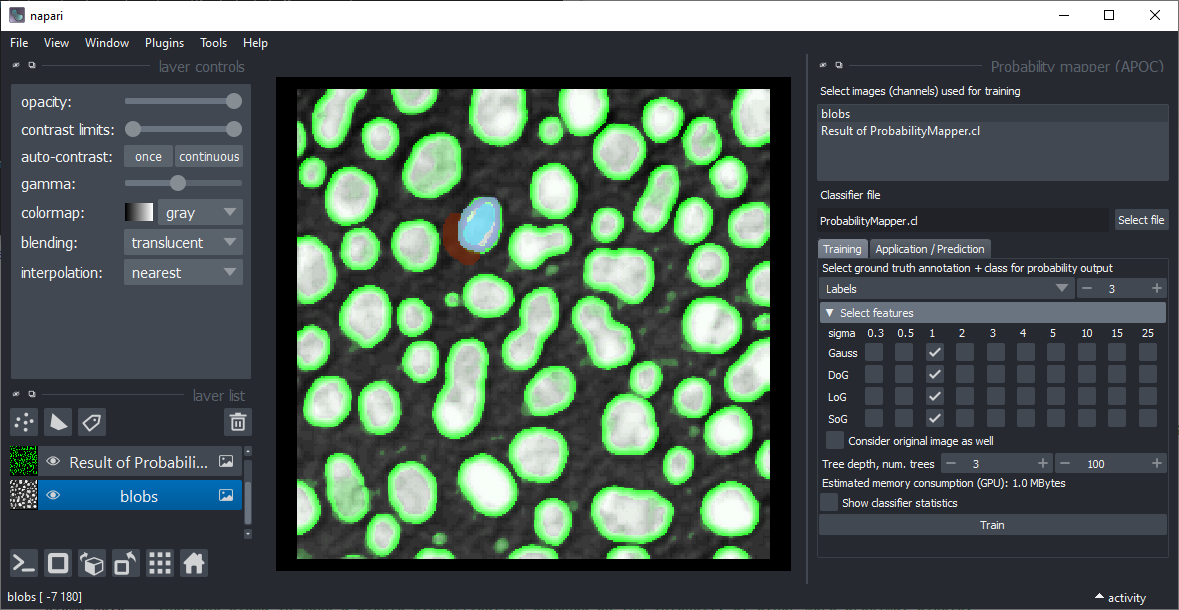
生成概率图的工具(在菜单“工具 > 过滤 > 概率映射器(APOC)”中)与对象分割器的工作方式类似。唯一的区别在于结果图像不是一个标签图像,而是一个强度图像,其中强度代表像素属于特定类别的概率(介于0和1之间)。在这个例子中:原始图像(灰色)被标注了三个类别:背景(黑色,标签1)、前景(白色,标签2)和边缘(灰色,标签3)。概率映射器被配置为创建边缘的概率图像(以绿色显示),标签为3
分类器统计信息
在训练过程中,您还可以激活“显示分类器统计信息”复选框。这样做时,建议增加树的数量,以便测量结果更可靠,尤其是在选择多个特征时。训练后,这将打开一个小表格,您可以从中看到每个分析特征图像的决策树所占的比例。
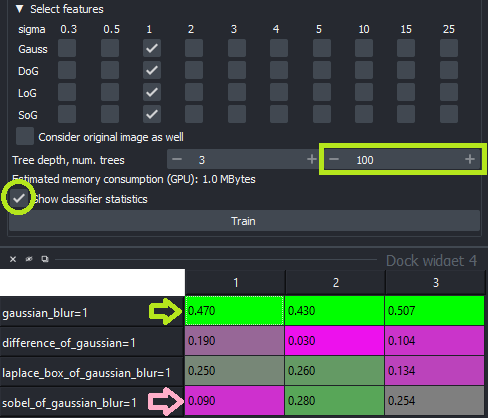
建议关闭/打开在随机森林中持有很大份额(绿色)或很小份额(洋红色)的树的特征。重新训练分类器以查看特征如何影响决策。
注意:多个这些参数可能相关。如果您选择了11个特征图像,这些图像都可以使像素分类相似,但其中10个是相关的,这些10个可能以大约0.05的份额出现,而第11个参数的份额为0.5。因此,请仔细研究这些值。
合并对象
在分割后,您可以使用“工具 > 分割后处理 > 合并对象(APOC)”菜单合并标记的对象。在一个空白标签图像中,用强度1标注应合并的标签边缘,用强度2标注应保留的边缘。选择哪些特征应考虑合并。
touch_portion:一个对象接触另一个对象的相对量。例如,在一个对称的蜂窝状组织中,相邻的细胞之间的接触部分为1/6。touch_count:对象接触的像素数量。当使用此参数时,请确保用于训练和预测的图像具有相同的体素大小。mean_touch_intensity:接触对象之间的平均平均强度。当使用此参数时,请确保用于训练和预测的图像以相同的方式进行归一化。centroid_distance:标记对象质心之间的距离(以像素或体素为单位)。mean_intensity_difference:两个对象平均强度的绝对差异。这种测量方法可以区分亮对象和暗对象,以及[不]合并它们。standard_deviation_intensity_difference:两个对象标准偏差的绝对差异。这种测量方法可以区分[非]均匀对象,以及[不]合并它们。area_difference:面积/体积/像素计数的差异,可以区分小对象和大对象,以及[不]合并它们。mean_max_distance_to_centroid_ratio_difference:此参数是一个形状描述符,类似于伸长率,可以区分圆形和细长对象,以及[不]合并它们。
注意:大多数特征仅建议用于各向同性图像。
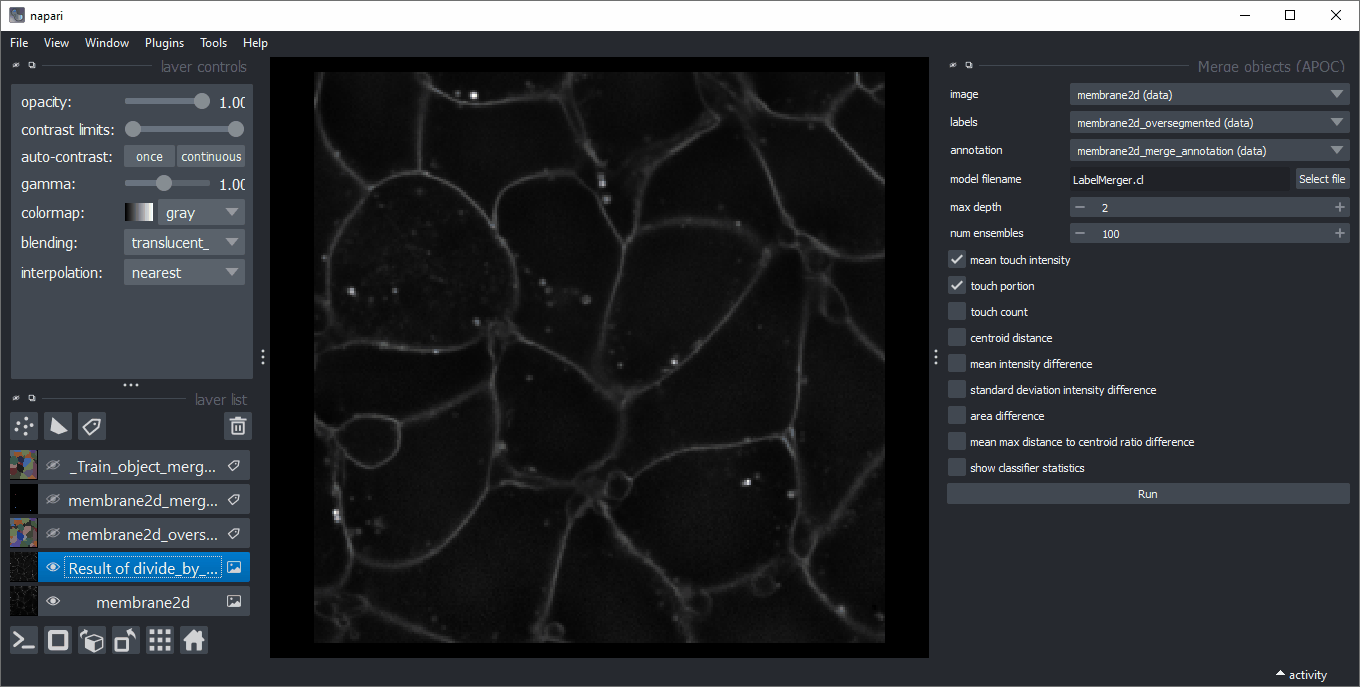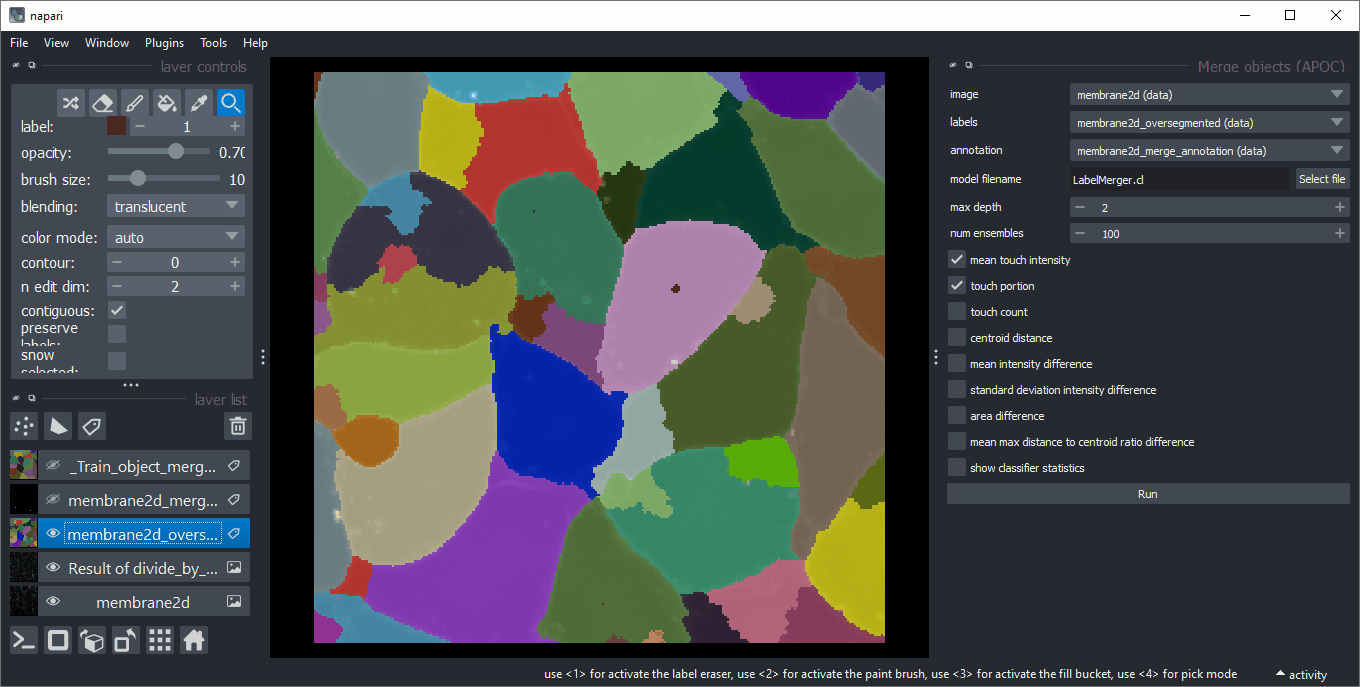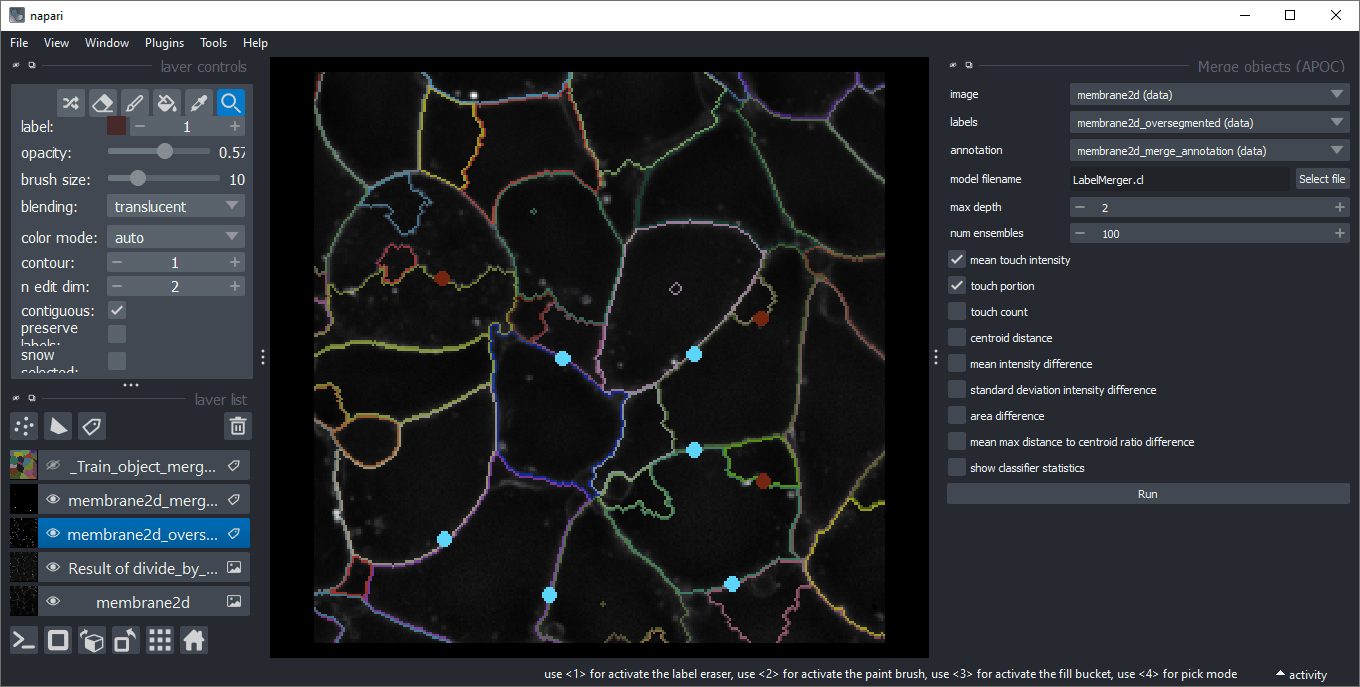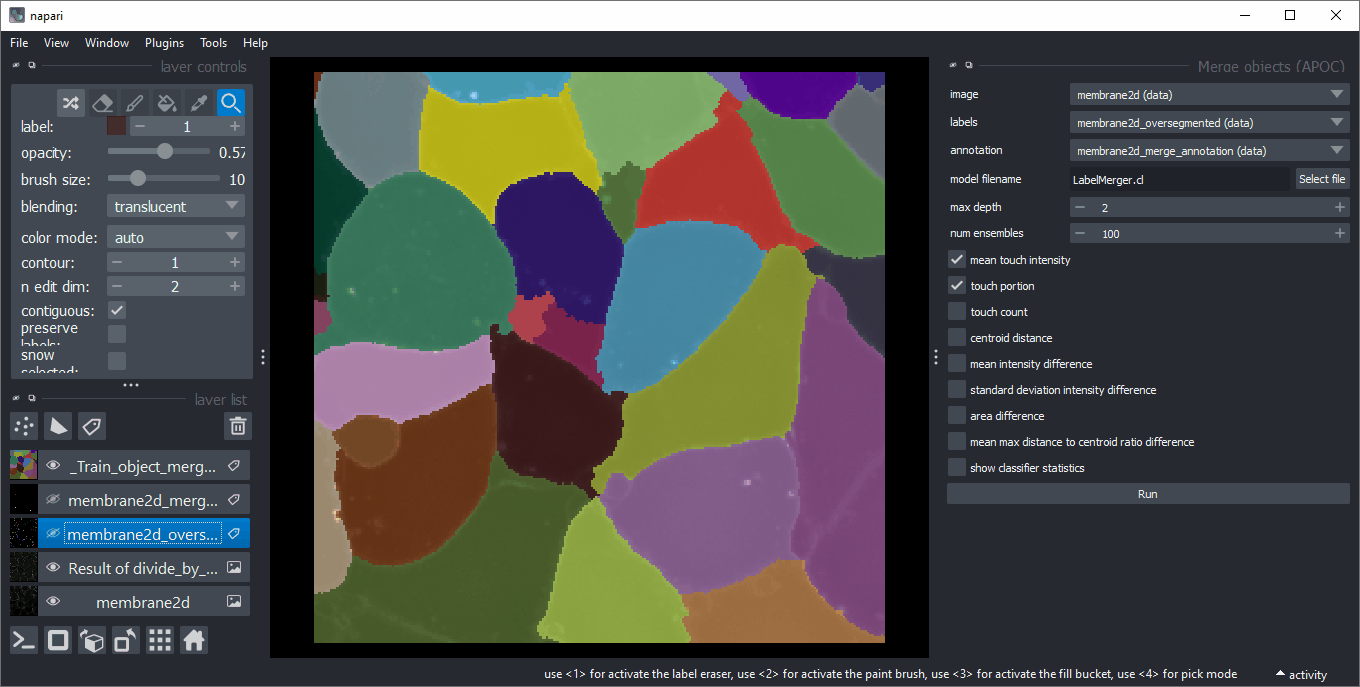
对于训练,请使用等效化强度(1)的图像、过分割的标签图像(2)和注释(3)。在新的标签层中绘制注释时,请确保误导算法在接触对象的边缘绘制1,如果它们应该合并,绘制2,如果应该保留。确保在应合并和保留的标签上都没有1/2注释圆圈。

对象分类
点击菜单“工具 > 分割后处理 > 对象分类(APOC)”。
将显示此用户界面
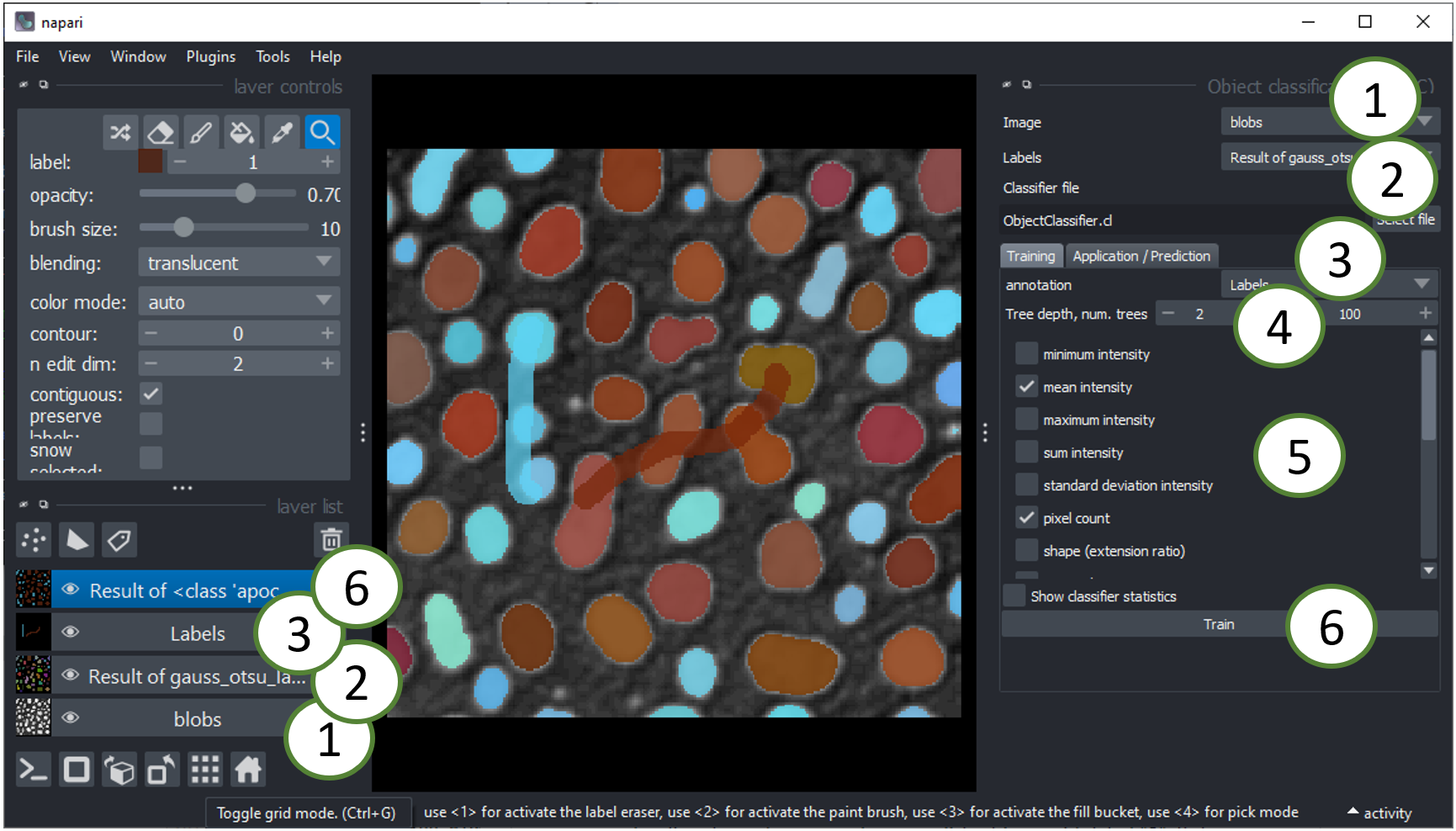
- 将使用图像层进行基于强度的特征提取(见下文)。
- 标签层应包含应被分类的对象的分割。您可以使用上述解释的“对象分割器”创建此层。
- 注释层应包含对象类别的手动注释。您可以绘制穿过单个和多个相同类型对象的线条。例如,绘制一条穿过一些被标记为“1”的细长对象的线条,并绘制另一条穿过一些较圆的对象的线条,标记为“2”。如果这些线条触及背景,则会被忽略。
- 树深度和树的数量允许您微调如何处理不同特性的 manifold 对象。这些数字越高,分类所需时间越长。如果您使用了许多特征,则可能需要高深度和树的数量。(参见 scikit-learn 随机森林分类器文档 中的
max_depth和n_estimators。) - 选择合适的特征进行训练。例如,为了根据上述建议区分形状不同的对象,请选择“形状”。特征提取使用 clEsperanto 完成,并在 此笔记本 中通过示例展示。
- 点击
运行按钮。如果第一次尝试分类效果不佳,请尝试更改选定的特征。
如果分类效果良好,例如看起来可能如下所示。请注意,绘制了两条粗线来注释细长和圆形对象,分别用棕色和青色标记
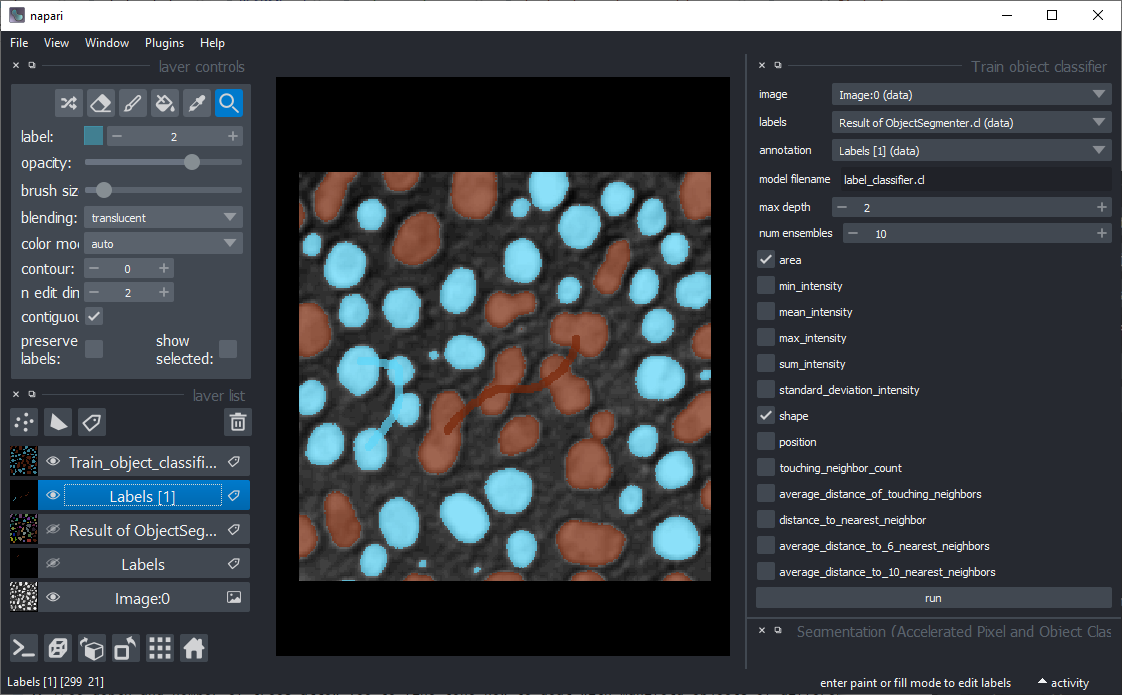
预训练的模型可以从以下示例笔记本中的脚本应用或使用菜单 工具 > 分割后处理 > 对象分类(应用预训练,APOC)。
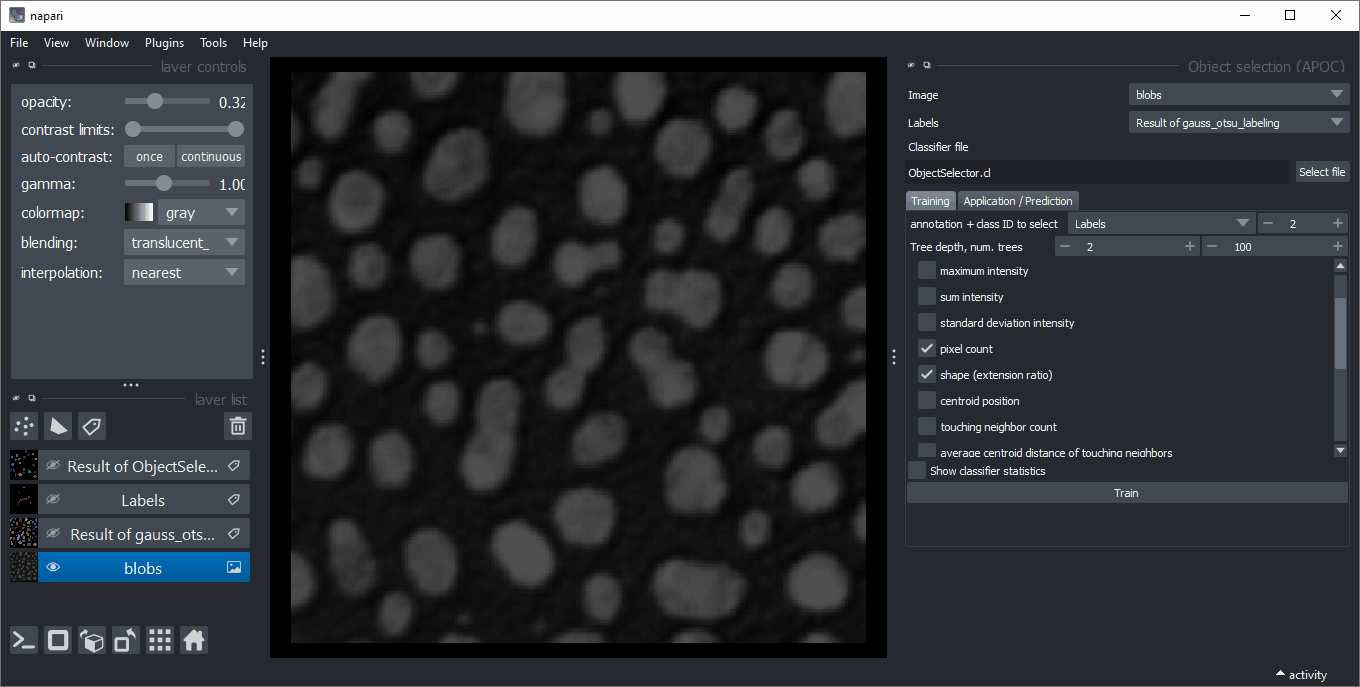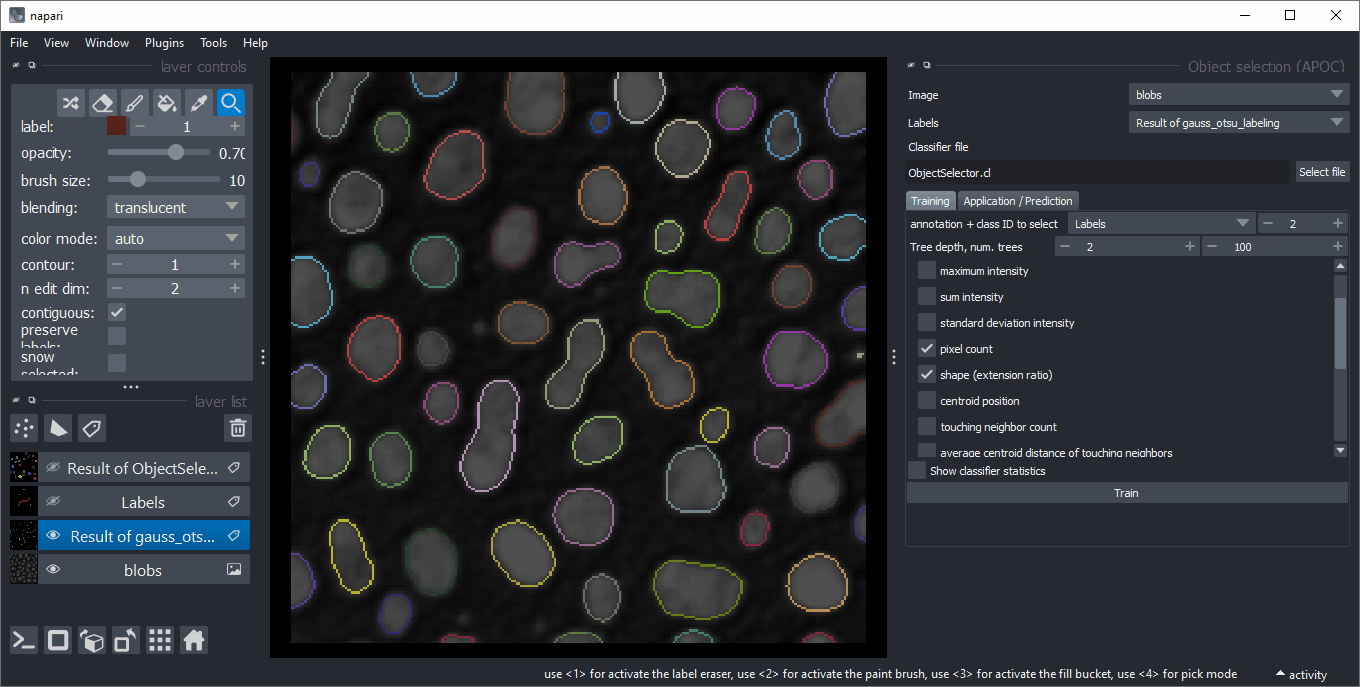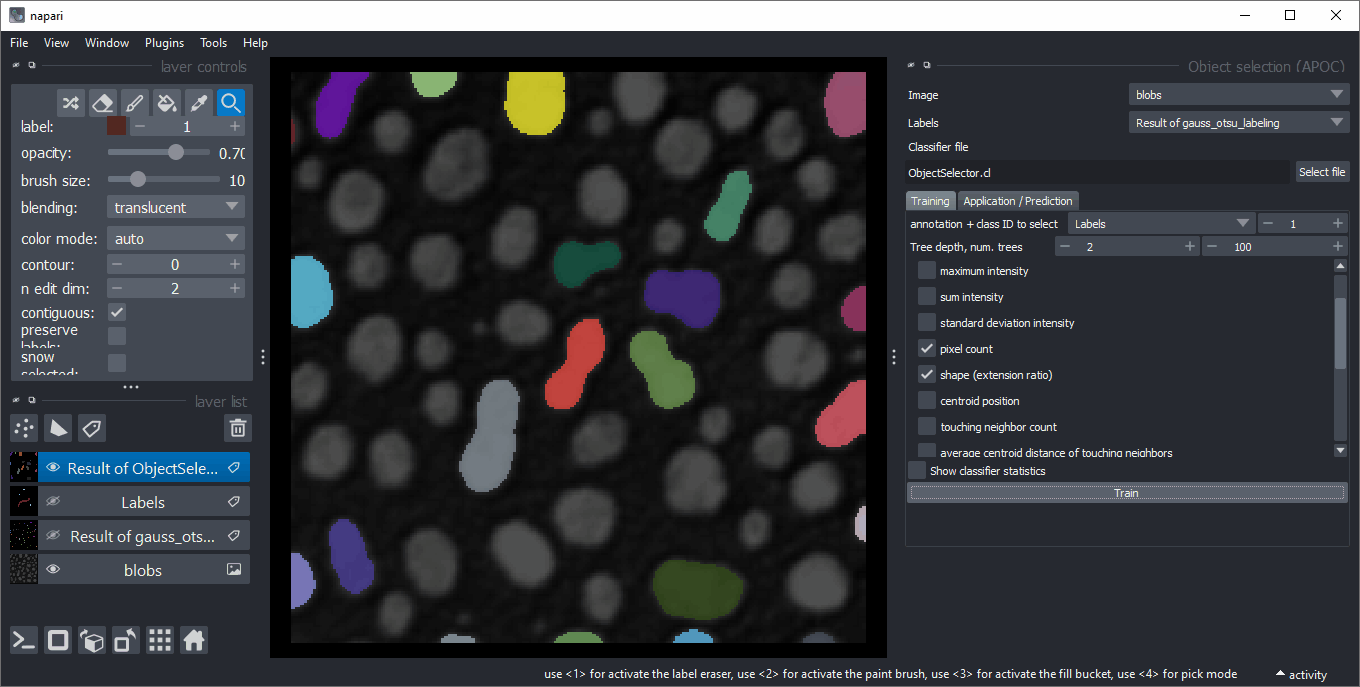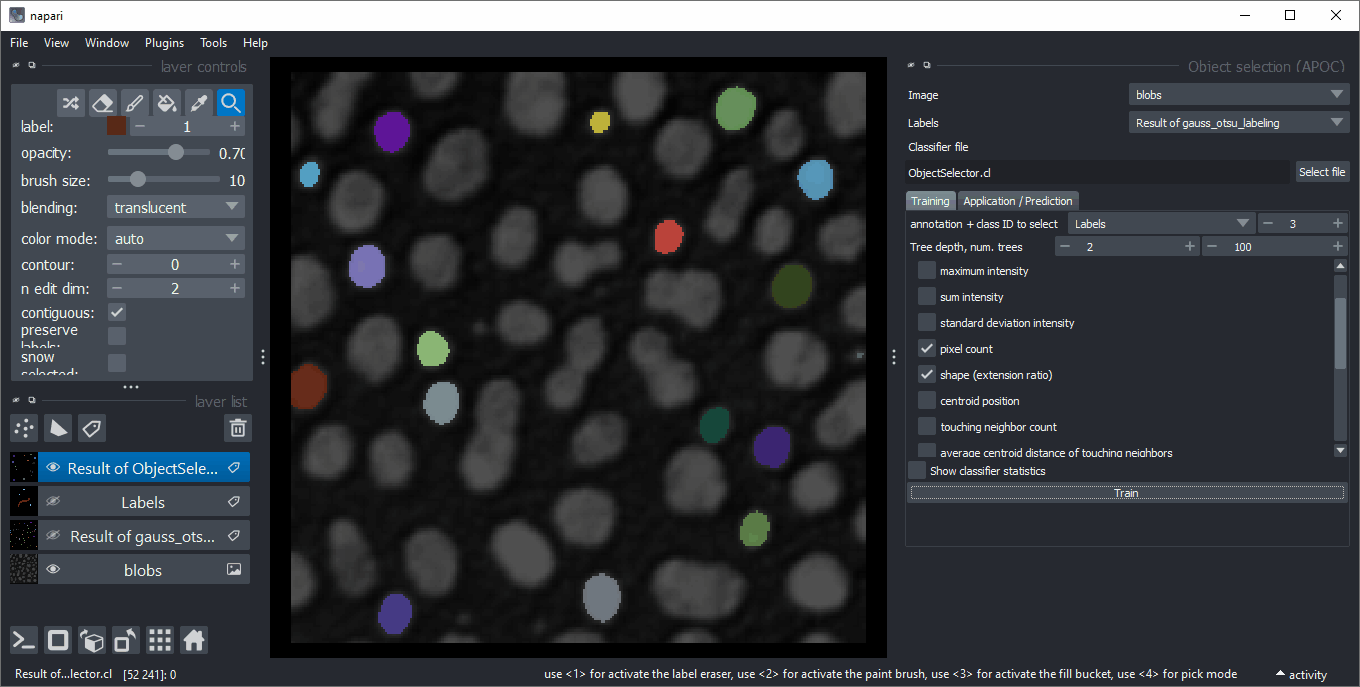
对象选择
类似于对象分类,对象选择器从标签图像中删除不属于指定类别的所有对象。您可以在菜单 工具 > 分割后处理 > 对象选择(APOC) 中找到它。
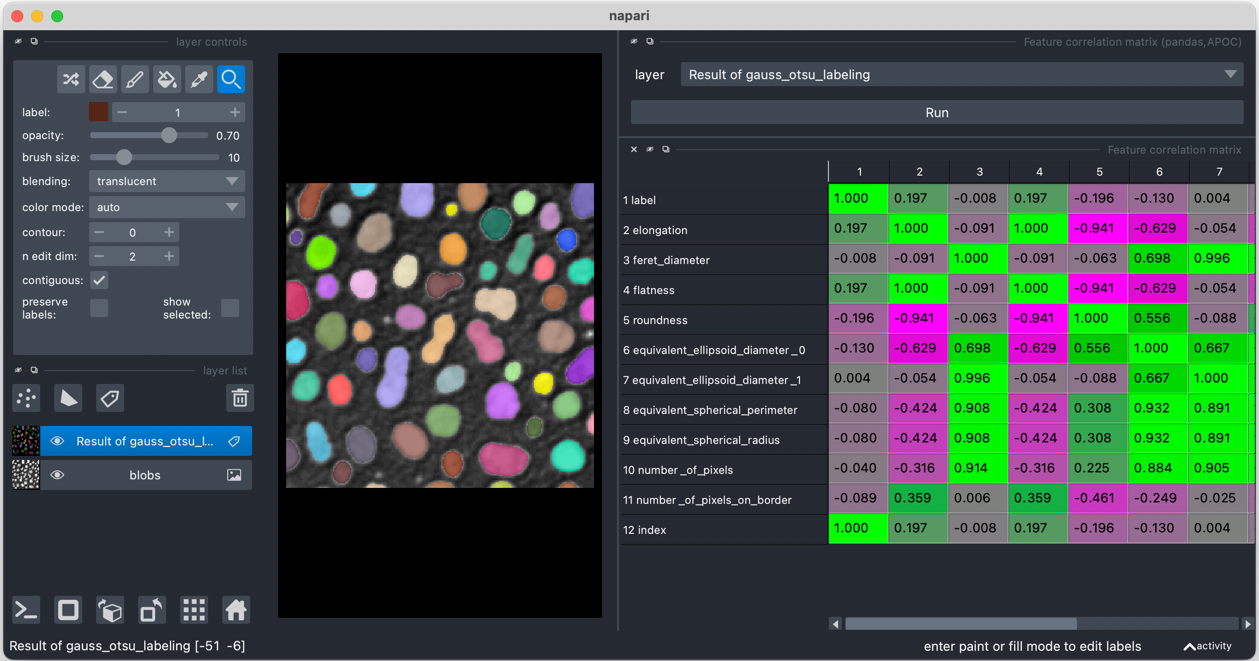
特征相关性矩阵
在训练对象分类器时,调查特征的相关程度并选择正确、最好是无关的特征以稳健地分类对象至关重要。在以下任何兼容的 napari 插件测量特征后,您可以使用菜单 工具 > 测量表 > 显示特征相关性矩阵(pandas,APOC) 和选择已分析的标签层来可视化特征相关性矩阵。在计算相关性矩阵之前,所有包含 NaN 值的行都会被移除。有关更多详细信息,请参阅 pandas 底层函数文档。
表面顶点分类(SVeC)
当与 napari-process-points-and-surfaces>=0.3.3 结合使用 napari-APOC 时,还可以对顶点进行分类。因此,例如使用菜单 测量 > 表面质量表(vedo,nppas) 确定定量测量,并使用菜单 表面 > 手动注释表面(nppas) 进行手动注释。建议将整个表面注释为值 1 作为背景,并将感兴趣的具体区域注释为整数 > 1。在提取测量并完成注释后,从 表面 > 表面顶点分类(自定义属性,APOC) 菜单启动 SVeC。它可以像上述对象分类器一样使用。

分类器统计信息
在分类器训练后,通过激活复选框 显示分类器统计信息 和 显示特征相关性矩阵,您可以研究各个特征/测量的份额以及它们的相关性。
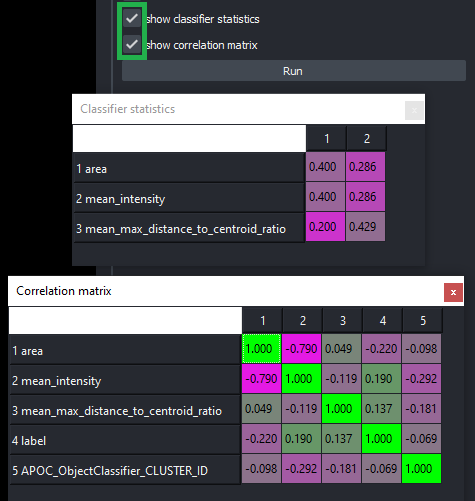
这有助于理解分类器的工作方式。此外,您可以通过减少相关特征的数量来加速分类器。
基于自定义测量的物体分类
您还可以根据自定义测量对标记过的物体进行分类。为了获取这些测量值,您可以使用以下napari插件
- 形态计量学
- PartSeg
- napari-simpleitk-image-processing
- napari-cupy-image-processing
- napari-pyclesperanto-assistant
- napari-skimage-regionprops
此外,如果您使用Python中的napari,您还可以创建一个包含测量值的字典或pandas DataFrame,并将其存储在labels_layer.features中,以便在物体分类器中使用。
在测量标签后,您可以从工具 > 分割后处理菜单启动物体分类器(自定义属性,APOC)
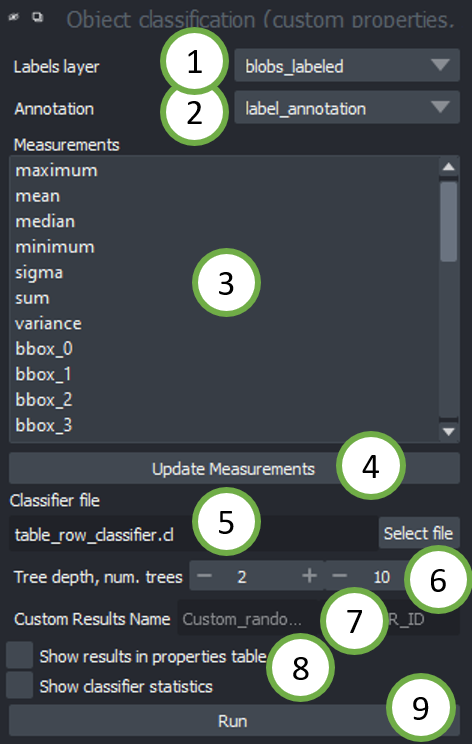
- 选择已测量的标签层。
- 注释层应包含对象类别的手动注释。您可以绘制穿过单个和多个相同类型对象的线条。例如,绘制一条穿过一些被标记为“1”的细长对象的线条,并绘制另一条穿过一些较圆的对象的线条,标记为“2”。如果这些线条触及背景,则会被忽略。
- 选择用于物体分类的测量/特征。
- 如果您在物体分类器对话框打开后进行了新的测量,请使用
更新测量按钮。 - 在此处输入要训练的分类器文件名。如果该文件已存在,它将被覆盖。
- 树深度和树的数量允许您微调如何处理不同特性的 manifold 对象。这些数字越高,分类所需时间越长。如果您使用了许多特征,则可能需要高深度和树的数量。(参见 scikit-learn 随机森林分类器文档 中的
max_depth和n_estimators。) - 分类结果将存储在此名称下,在标签层的属性中。
- 选择是否显示结果表。选择是否显示分类器统计信息。有关分类器统计信息更多信息。
- 单击
运行以开始训练和预测。
您还可以从Python中训练这些分类器并重复使用它们:有关使用TableRowClassifier的更多信息
分类器统计信息和相关矩阵
在分类器训练后,您可以通过激活复选框显示分类器统计信息和显示相关矩阵来研究各个特征/测量的比例以及它们之间的相关性。
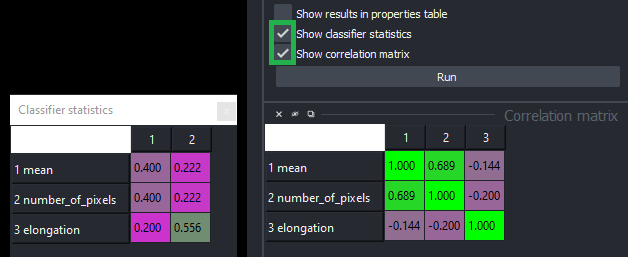
这有助于理解分类器的工作方式。此外,您可以通过减少相关特征的数量来加速分类器。
此napari插件是用Cookiecutter利用@napari的cookiecutter-napari-plugin模板生成的。
安装
建议在conda环境中安装此插件。因此,首先安装conda,例如mini-conda。如果您以前从未使用过conda,阅读此简短介绍可能有所帮助。
可选:设置一个新的conda环境,激活它并安装napari
conda create --name napari_apoc python=3.9
conda activate napari_apoc
conda install napari
如果您的conda环境已设置,您可以使用pip安装napari-accelerated-pixel-and-object-classification。注意:您需要先安装pyopencl。
conda install -c conda-forge pyopencl
pip install napari-accelerated-pixel-and-object-classification
Mac用户请也安装此软件
conda install -c conda-forge ocl_icd_wrapper_apple
Linux用户请也安装此软件
conda install -c conda-forge ocl-icd-system
贡献
欢迎贡献、反馈和建议。可以使用tox运行测试,请在提交pull request之前确保覆盖率至少保持不变。
类似软件
还有其他napari插件和其他具有类似功能的软件,用于交互式像素和物体分类。
许可证
根据BSD-3许可证发布,“napari-accelerated-pixel-and-object-classification”是免费和开源软件
问题
如果您遇到任何问题,请在image.sc上打开一个线程,并附上详细描述和标签@haesleinhuepf。


napari-accelerated-pixel-and-object-classification-0.14.1.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 2f626a9c2d671bf32cade62df74666eef328e6dc3f6d7f3ab6091a992131fb5c |
|
| MD5 | e7044d9a2833a4303c90e8d7a832efe7 |
|
| BLAKE2b-256 | 2a02deee925bd122e5eab619122d794460bfa0e998aeea099dded78c45746b24 |
napari_accelerated_pixel_and_object_classification-0.14.1-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 041bc5347e40cf8b4581a9e0c1f1d20c6526c9f1fa68e7056c594db4dd057b88 |
|
| MD5 | 0ace4e511dd0c6be41f806545c4fe42b |
|
| BLAKE2b-256 | cb0d11fca309754dd4c97332f0e4837ab985d91c65c71d0b07e5614ede74c35d |







