VerticaPy简化了在Vertica中的数据探索、数据清洗和机器学习。



项目描述

:star: 2023-12-01: VerticaPy获得200颗星。
:loudspeaker: 2020-06-27: Vertica-ML-Python已重命名为VerticaPy。
:warning: 旧网站已迁移至 https://www.vertica.com/python/old/,并将很快停止使用。我们强烈建议在 2024 年 8 月之前升级到新的大版本。
:warning: 以下 README 文件适用于 VerticaPy 1.0.x 及以后版本,因此其中一些元素可能不在早期版本中存在。
:scroll: 一些基本语法可以在 速查表 中找到。
📰 查看最新通讯 此处。
VerticaPy








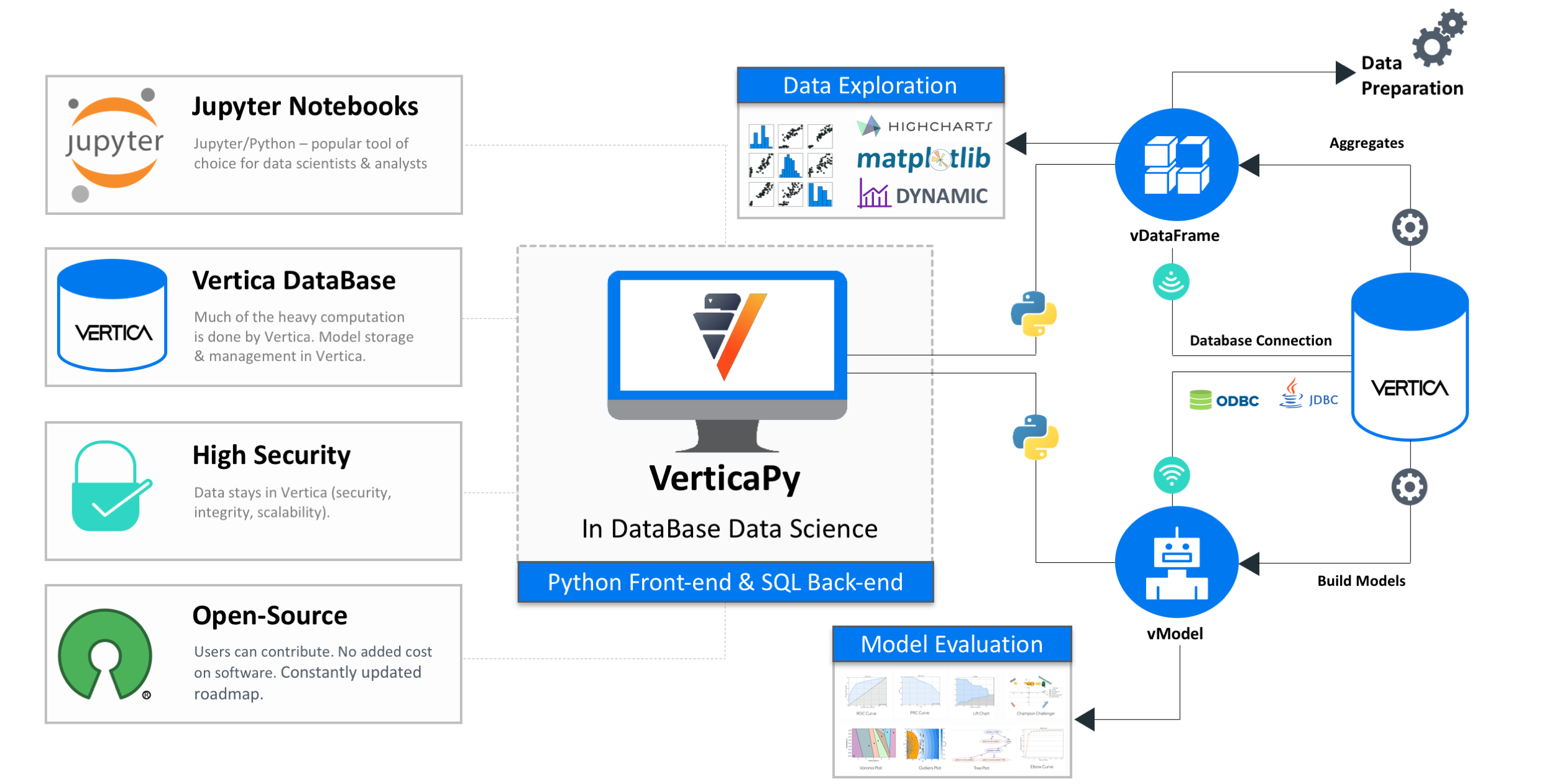
VerticaPy 是一个具有类似 scikit 功能的 Python 库,用于在 Vertica 中存储的数据上执行数据科学项目,利用 Vertica 的速度和内置的分析以及机器学习功能。VerticaPy 为整个数据科学生命周期提供强大的支持,使用“管道”机制来顺序化数据转换操作,并提供美观的图形选项。
目录
简介
Vertica 是第一个真正的分析型列存储数据库,并且仍然是市场上速度最快的数据库。然而,仅使用 SQL 并不足以满足数据科学家的需求。
Python 已经迅速成为这个领域的最流行工具,这主要归功于它的高度抽象和令人印象深刻的大型且不断增长的库集。它的可访问性导致了流行的且性能出色的 API(如 pandas 和 scikit-learn)以及一个专门的科学家社区的发展。不幸的是,Python 只能以单节点进程的形式在内存中运行。这个问题导致了分布式编程语言的兴起,但它们也受到内存进程的限制,因此在这个时代永远无法处理所有数据,并且将数据移动到处理位置的成本非常高。除此之外,数据科学家还必须找到方便的方式来部署他们的数据和模型。整个过程很耗时。
VerticaPy 旨在解决所有这些问题。想法很简单:不是移动数据来处理,而是 VerticaPy 将逻辑带到数据。
经过 3 年的研发,我们自豪地向您推出 VerticaPy。
主要优势
- 易于数据探索。
- 快速数据准备。
- 数据库内机器学习。
- 易于模型评估。
- 易于模型部署。
- 使用 Python 或 SQL 的灵活性。
安装
使用 pip 安装 VerticaPy
# Latest release version
root@ubuntu:~$ pip3 install verticapy[all]
# Latest commit on master branch
root@ubuntu:~$ pip3 install git+https://github.com/vertica/verticapy.git@master
从源安装 VerticaPy,请在根目录下运行以下命令
root@ubuntu:~$ python3 setup.py install
详细的安装指南可在
https://www.vertica.com/python/documentation/installation.html
连接到数据库
VerticaPy 与多个客户端兼容。有关详细信息,请参阅连接页面。
文档
查找特定函数文档的最简单和最准确的方法是使用帮助函数
import verticapy as vp
help(vp.vDataFrame)
官方文档可在
https://www.vertica.com/python/documentation/
要生成文档,请参阅
https://github.com/mail4umar/VerticaPy/blob/master/docs/Documentation%20Generation.md
用例
示例和案例研究
https://www.vertica.com/python/examples/
突出功能
主题
VerticaPy 为用户提供两种视觉上吸引人的主题:暗色和亮色来自定义他们的编码体验。
暗色模式,非常适合夜间编码会话,具有时尚的深色色调,提供一个舒适且对眼睛友好的环境。
另一方面,亮色模式是默认主题,为喜欢传统编码氛围的用户提供了干净且明亮的界面。
可以通过以下方式轻松切换主题
import verticapy as vp
vp.set_option("theme", "dark") # can be switched 'light'.
VerticaPy的主题切换选项确保用户可以根据自己的喜好定制体验,使数据探索和分析变得更加个性化和愉悦。
SQL 魔法
您可以使用VerticaPy在Jupyter笔记本中直接执行SQL查询。详细信息请参阅SQL Magic
示例
加载SQL扩展。
%load_ext verticapy.sql
执行您的SQL查询。
%%sql
SELECT version();
# Output
# Vertica Analytic Database v11.0.1-0
SQL 图表
您可以直接从SQL创建交互式、专业的图表。
要创建图表,只需提供图表类型和SQL命令。
示例
%load_ext verticapy.jupyter.extensions.chart_magic
%chart -k pie -c "SELECT pclass, AVG(age) AS av_avg FROM titanic GROUP BY 1;"
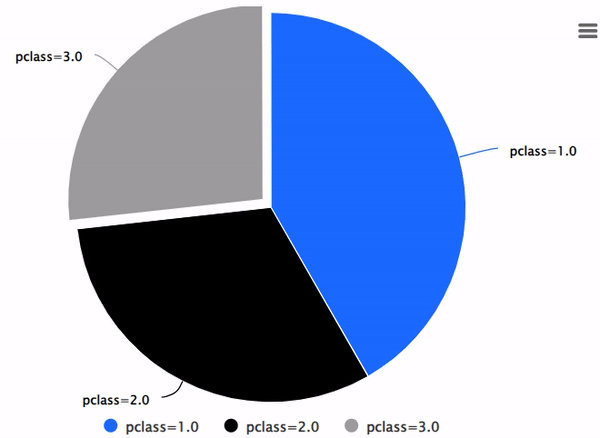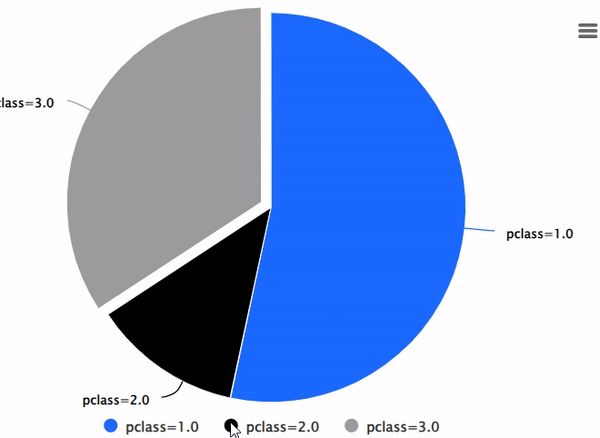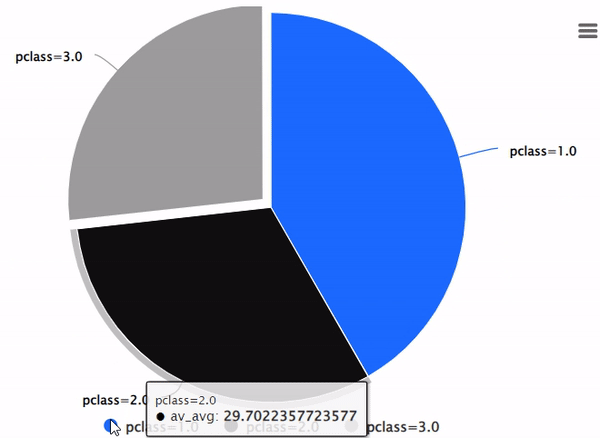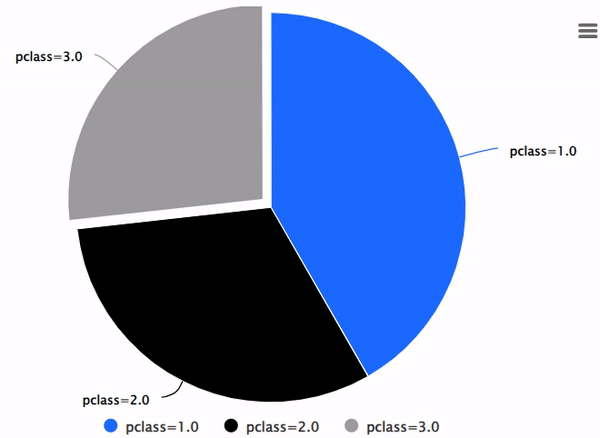
使用DBLINK进行多个数据库连接
在单个平台上,可以使用SQL和Python访问多个数据库(例如,PostgreSQL、Vertica、MySQL、内存数据库)。
示例
%%sql
/* Fetch TAIL_NUMBER and CITY after Joining the flight_vertica table with airports table in MySQL database. */
SELECT flight_vertica.TAIL_NUMBER, airports.CITY AS Departing_City
FROM flight_vertica
INNER JOIN &&& airports &&&
ON flight_vertica.ORIGIN_AIRPORT = airports.IATA_CODE;
在上面的示例中,'flight_vertica'表存储在Vertica中,而'airports'表存储在MySQL中。我们可以将特殊的符号"&&&"与不同的数据库关联起来以获取数据。最好的部分是,所有的聚合都推送到数据库中(即不在内存中执行)!
有关如何设置DBLINK的更多详细信息,请访问github存储库。要了解如何在VerticaPy中使用DBLINK,请参阅文档页面。
Python 和 SQL 组合
VerticaPy在市场上占有独特的位置,因为它允许用户在同一个环境中使用Python和SQL。
示例
import verticapy as vp
selected_titanic = vp.vDataFrame(
"(SELECT pclass, embarked, AVG(survived) FROM public.titanic GROUP BY 1, 2) x"
)
selected_titanic.groupby(columns=["pclass"], expr=["AVG(AVG)"])
图表
Verticapy集成了三个流行的绘图库:matplotlib、highcharts和plotly。
VerticaPy生成的图表画廊可在以下位置查看
https://www.vertica.com/python/documentation/chart.html
完整的机器学习管道
-
数据摄取
VerticaPy允许用户从各种来源摄取数据,例如AVRO、Parquet、CSV、JSON等。使用简单的命令"read_file",VerticaPy会自动推断源类型和数据类型。
import verticapy as vp read_file( "/home/laliga/2012.json", table_name="laliga", )
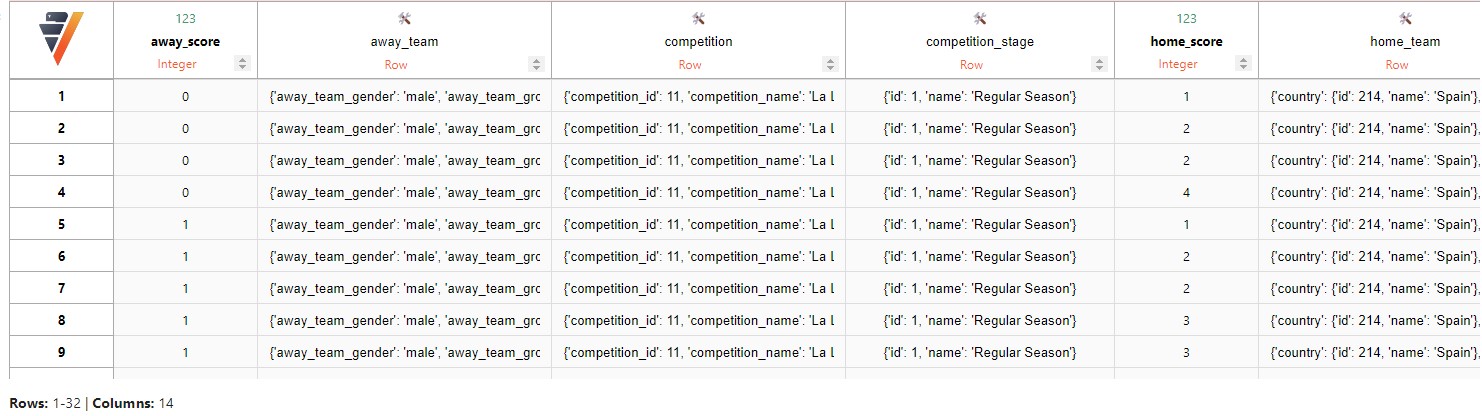
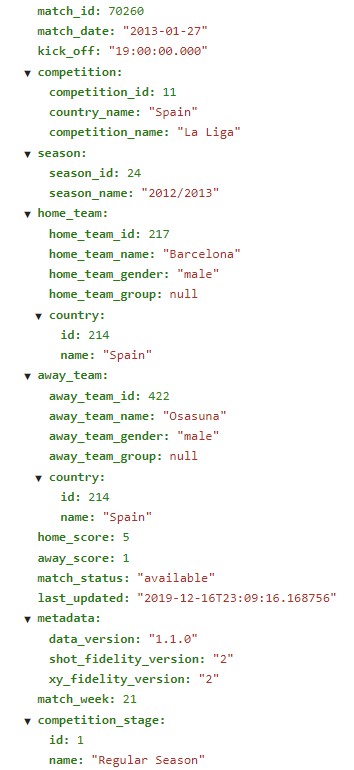
如上图所示,它已为复杂数据创建了一个嵌套结构。实际的文件结构如下
通过开启genSQL选项,我们甚至可以看到每个VerticaPy命令背后的SQL
import verticapy as vp
read_file("/home/laliga/2012.json", table_name="laliga", genSQL=True)
CREATE LOCAL TEMPORARY TABLE "laliga"
("away_score" INT,
"away_team" ROW("away_team_gender" VARCHAR,
"away_team_group" VARCHAR,
"away_team_id" INT, ...
ROW("id" INT,
"name" VARCHAR)),
"competition" ROW("competition_id" INT,
"competition_name" VARCHAR,
"country_name" VARCHAR),
"competition_stage" ROW("id" INT,
"name" VARCHAR),
"home_score" INT,
"home_team" ROW("country" ROW("id" INT,
"name" VARCHAR),
"home_team_gender" VARCHAR,
"home_team_group" VARCHAR,
"home_team_id" INT, ...),
"kick_off" TIME,
"last_updated" DATE,
"match_DATE" DATE,
"match_id" INT, ...
ROW("data_version" DATE,
"shot_fidelity_version" INT,
"xy_fidelity_version" INT),
"season" ROW("season_id" INT,
"season_name" VARCHAR))
ON COMMIT PRESERVE ROWS
COPY "v_temp_schema"."laliga"
FROM '/home/laliga/2012.json'
PARSER FJsonParser()
VerticaPy提供了导入其他特定文件类型的函数,例如read_json和read_csv。由于这些函数专注于特定文件类型,因此它们提供了更多处理数据的选项。例如,read_json有一个"flatten_arrays"参数,允许您展开嵌套的JSON数组。
-
数据探索
有很多选项可以进行描述性和可视化探索。
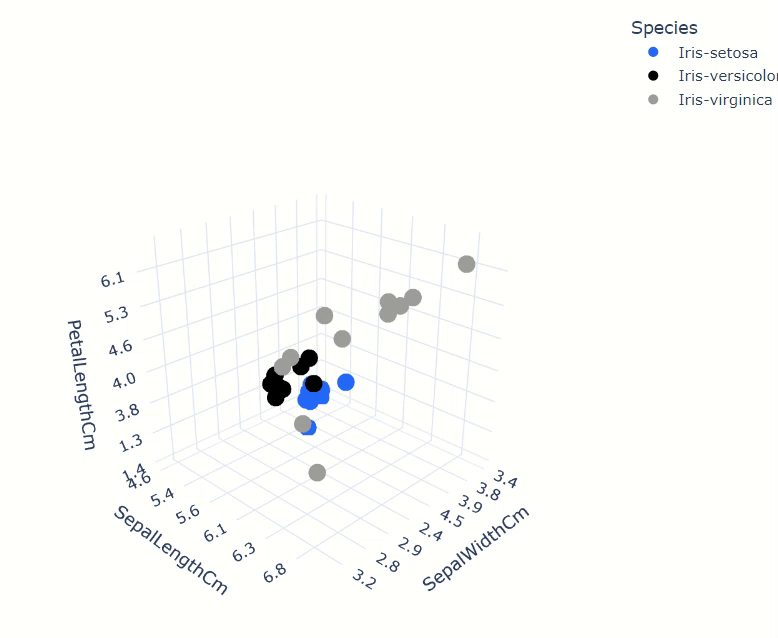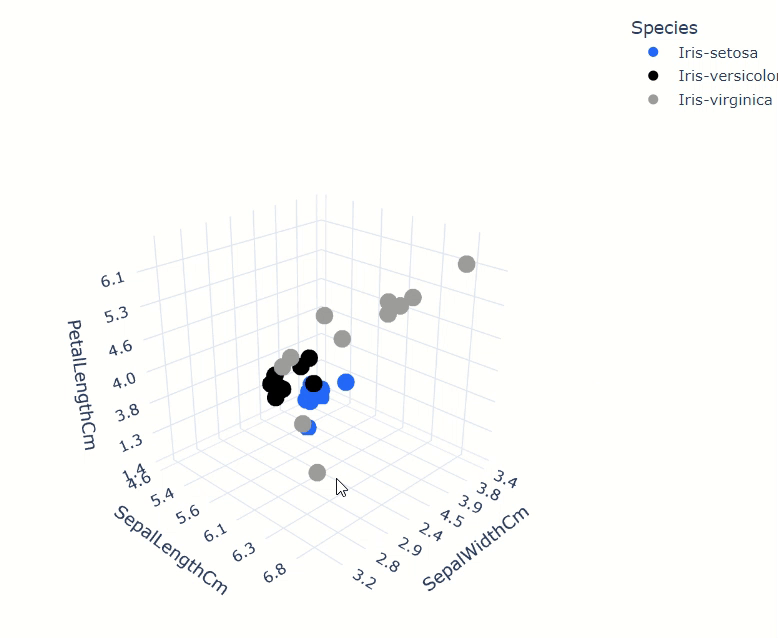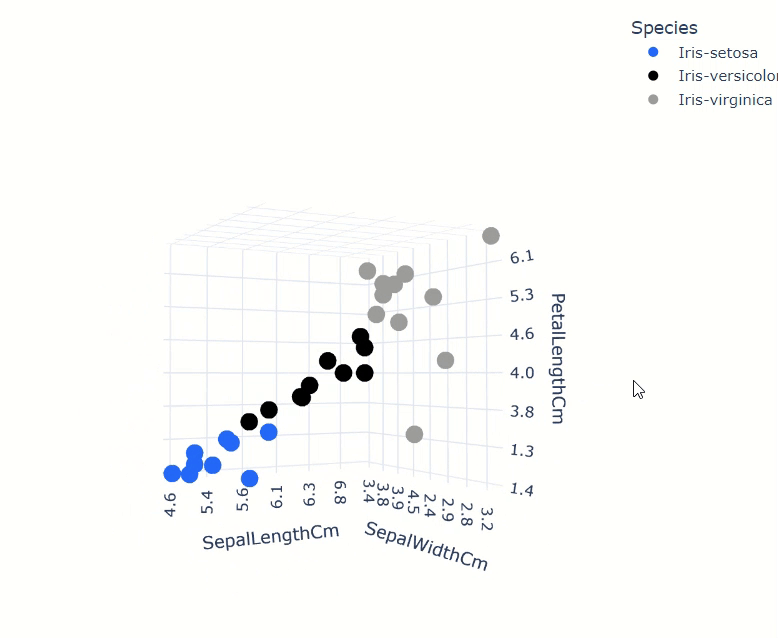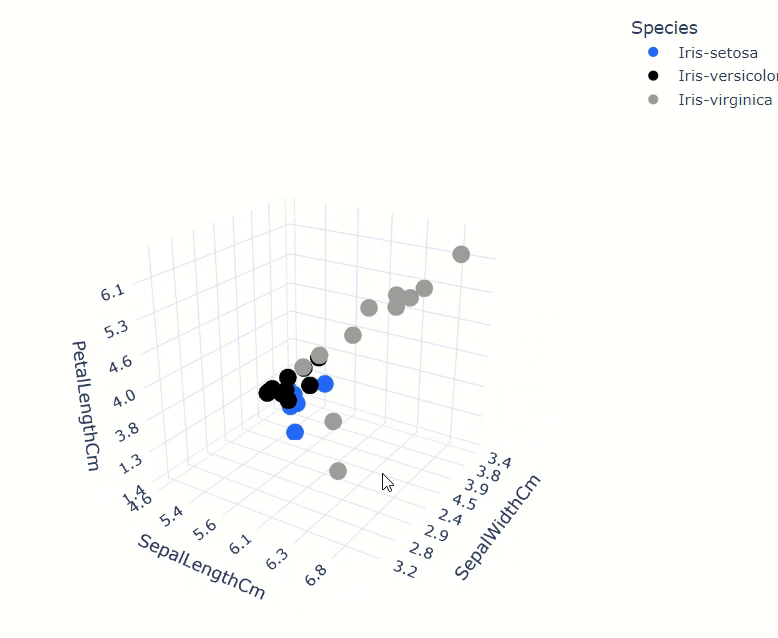
from verticapy.datasets import load_iris
iris_data = load_iris()
iris_data.scatter(
["SepalWidthCm", "SepalLengthCm", "PetalLengthCm"],
by="Species",
max_nb_points=30
)
相关矩阵也非常快速和方便计算。用户可以从广泛的关联中选择,包括cramer、spearman、pearson等。
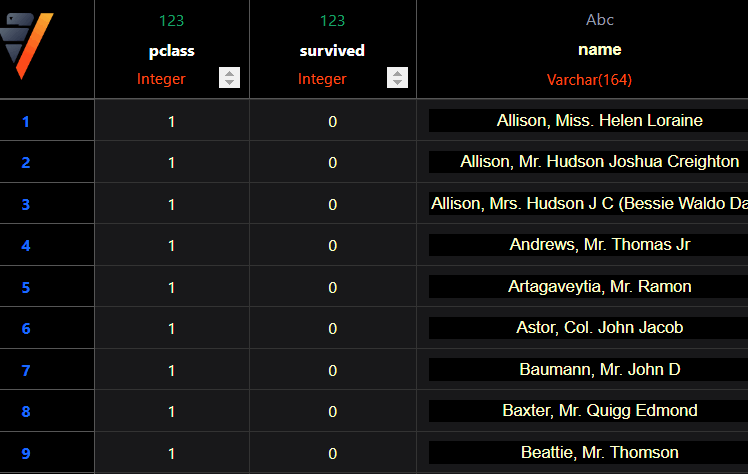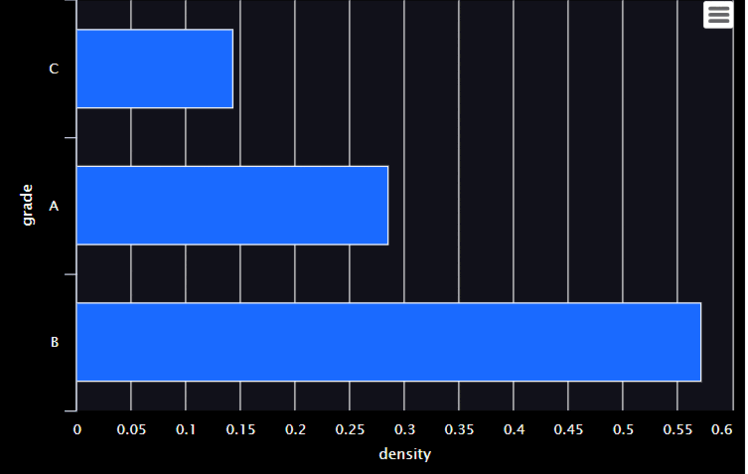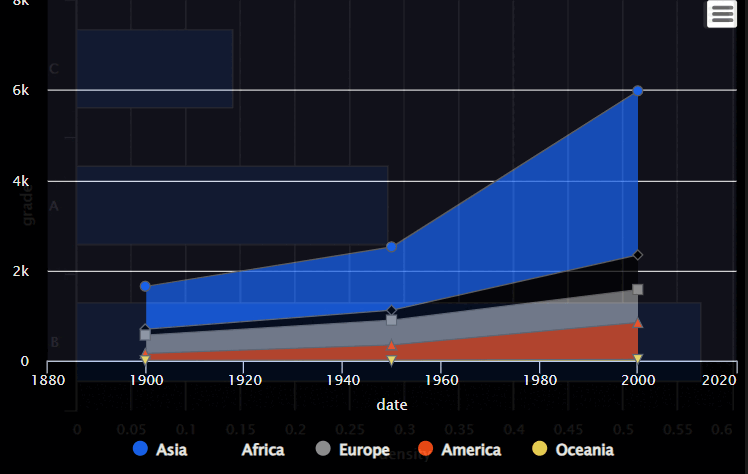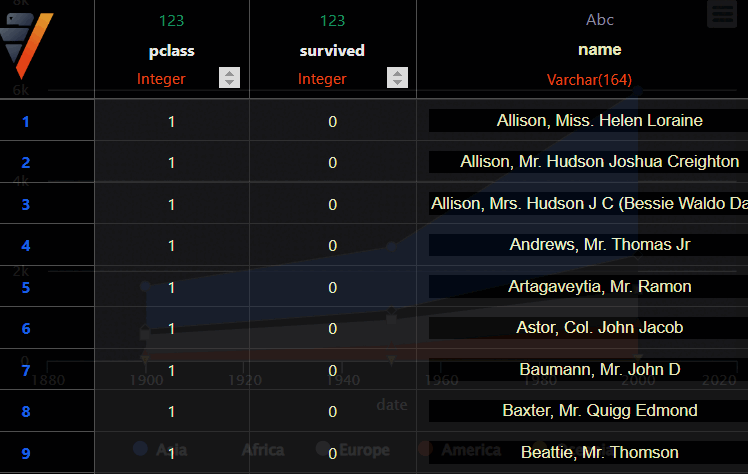
from verticapy.datasets import load_titanic
titanic = load_titanic()
titanic.corr(method="spearman")
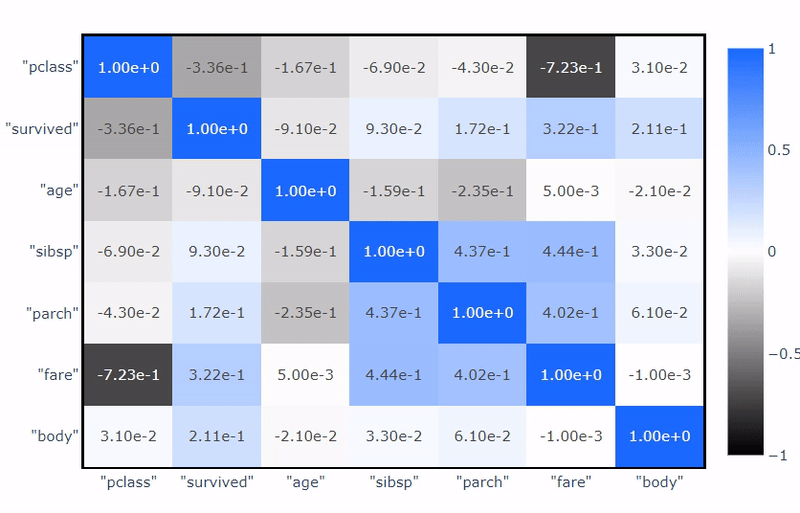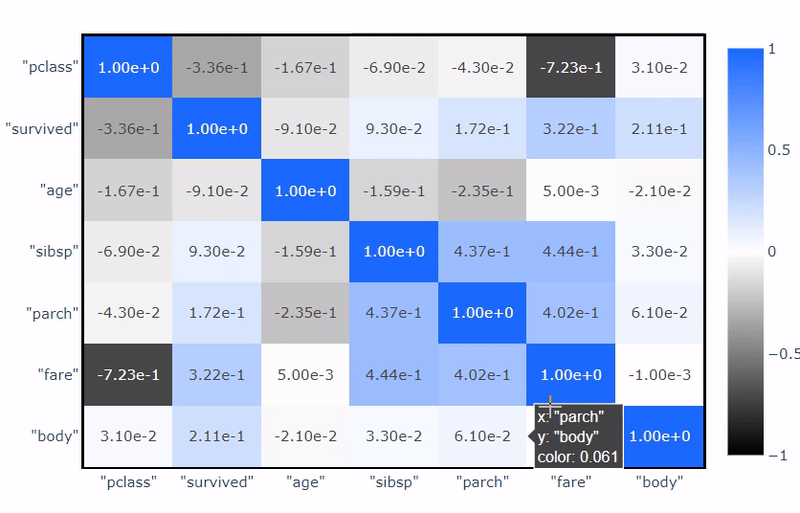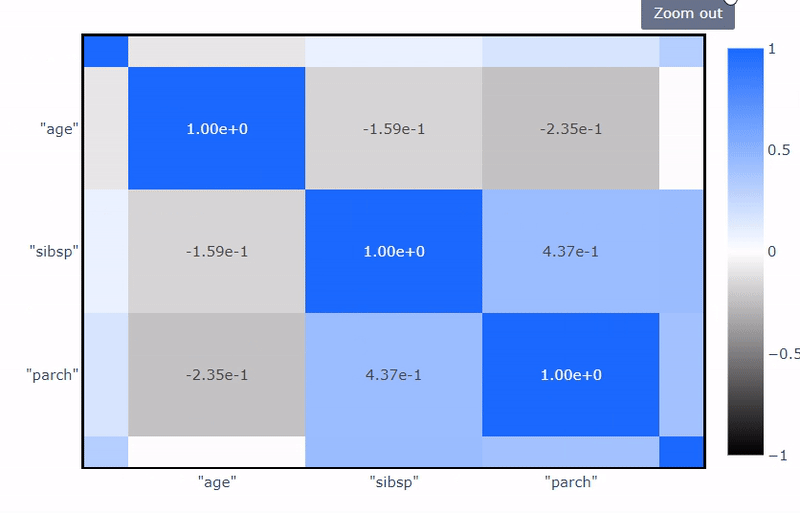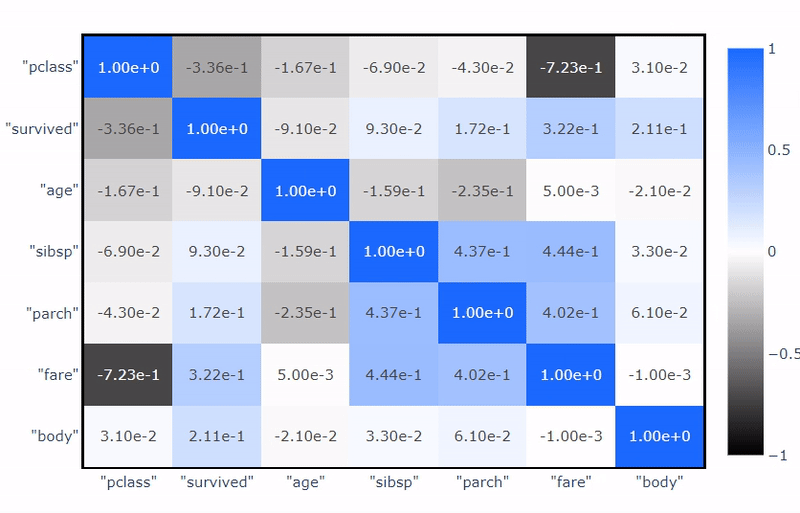
通过开启SQL打印选项,用户可以查看和复制SQL查询
from verticapy import set_option
set_option("sql_on", True)
SELECT
/*+LABEL('vDataframe._aggregate_matrix')*/ CORR_MATRIX("pclass", "survived", "age", "sibsp", "parch", "fare", "body") OVER ()
FROM
(
SELECT
RANK() OVER (ORDER BY "pclass") AS "pclass",
RANK() OVER (ORDER BY "survived") AS "survived",
RANK() OVER (ORDER BY "age") AS "age",
RANK() OVER (ORDER BY "sibsp") AS "sibsp",
RANK() OVER (ORDER BY "parch") AS "parch",
RANK() OVER (ORDER BY "fare") AS "fare",
RANK() OVER (ORDER BY "body") AS "body"
FROM
"public"."titanic") spearman_table
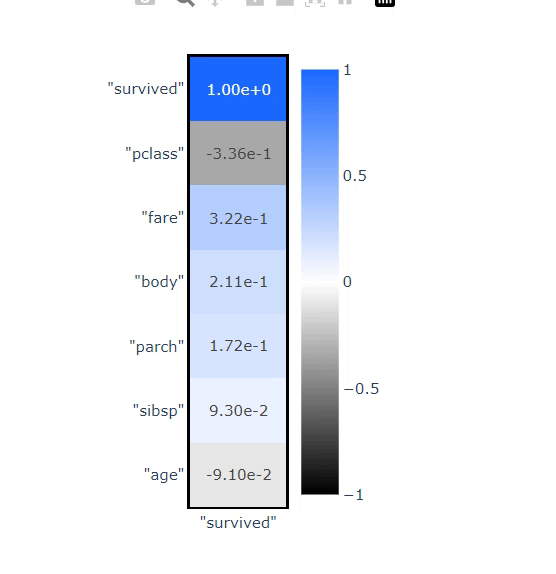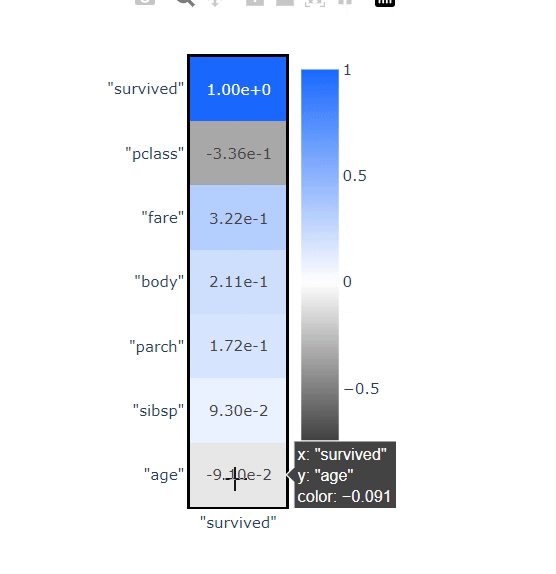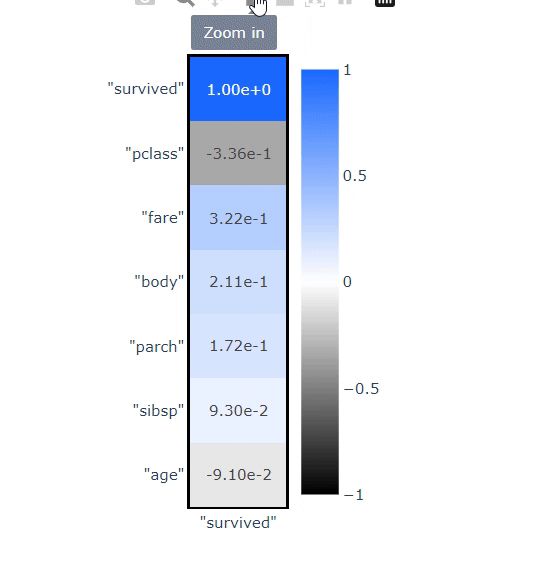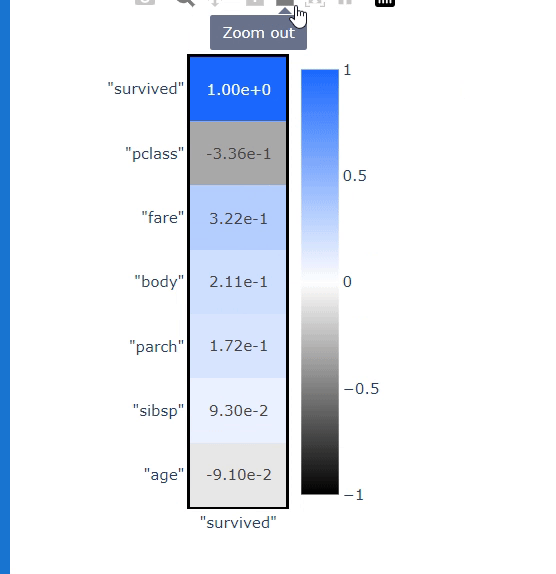
VerticaPy允许用户使用"focus"参数计算聚焦的相关性
titanic.corr(method="spearman", focus="survived")
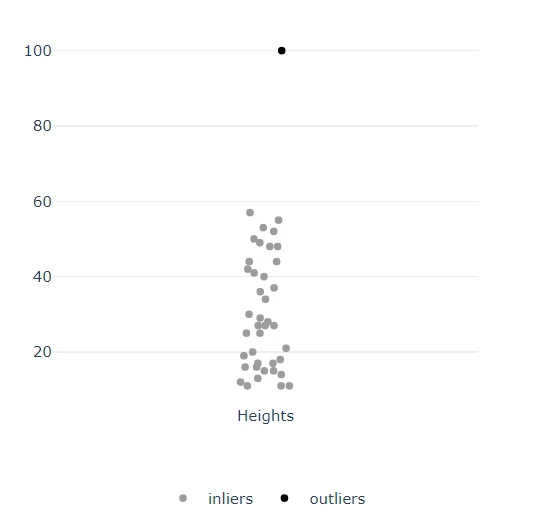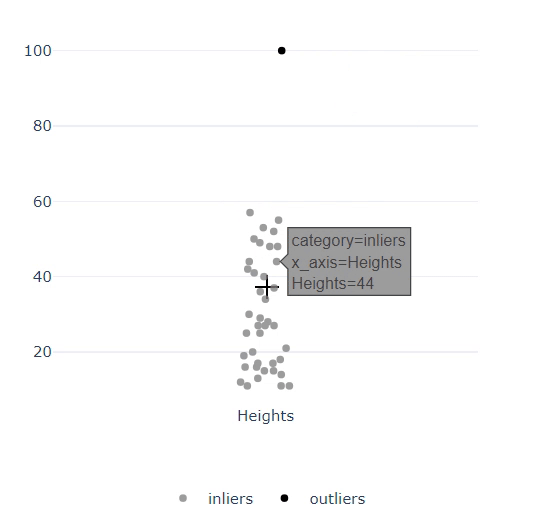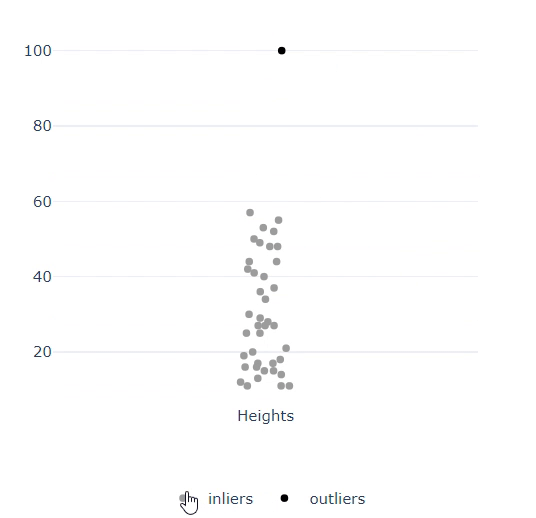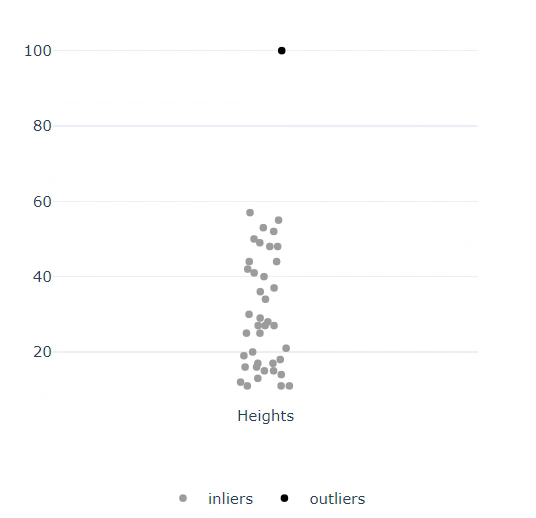
import random
import verticapy as vp
data = vp.vDataFrame({"Heights": [random.randint(10, 60) for _ in range(40)] + [100]})
data.outliers_plot(columns="Heights")
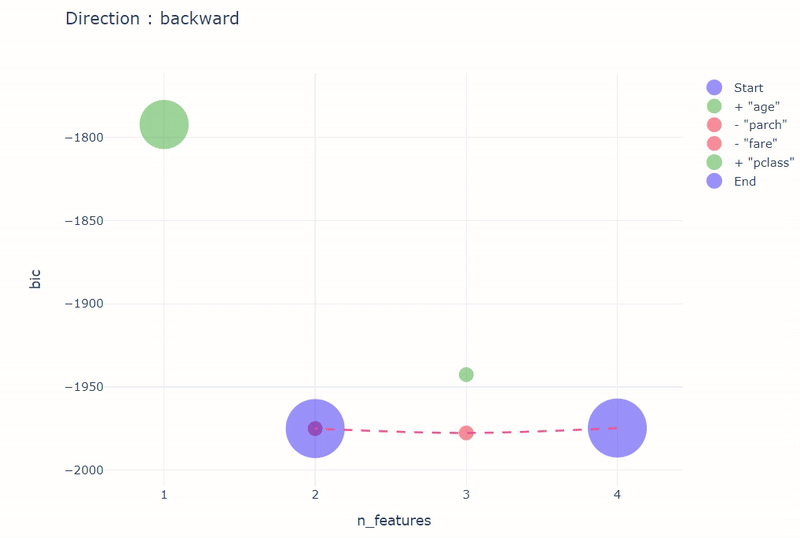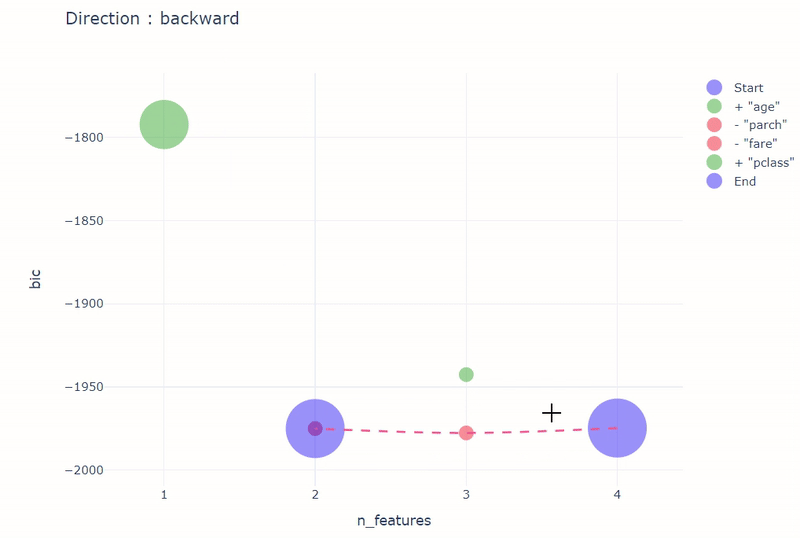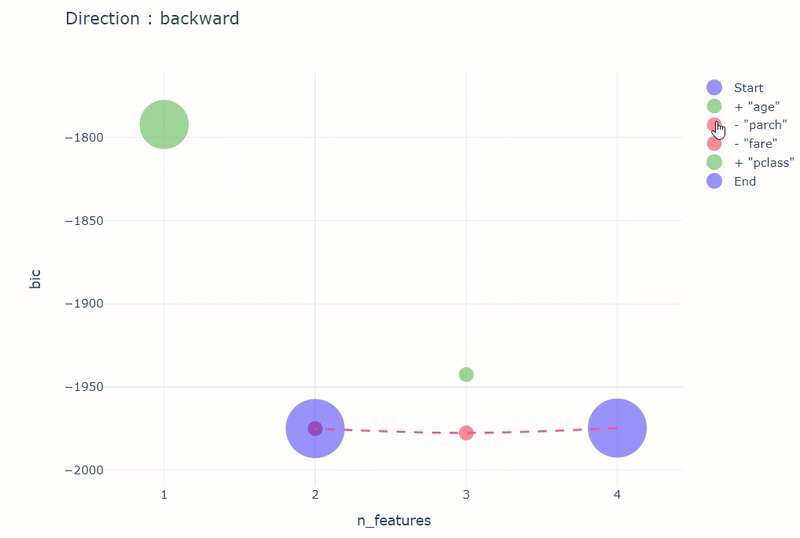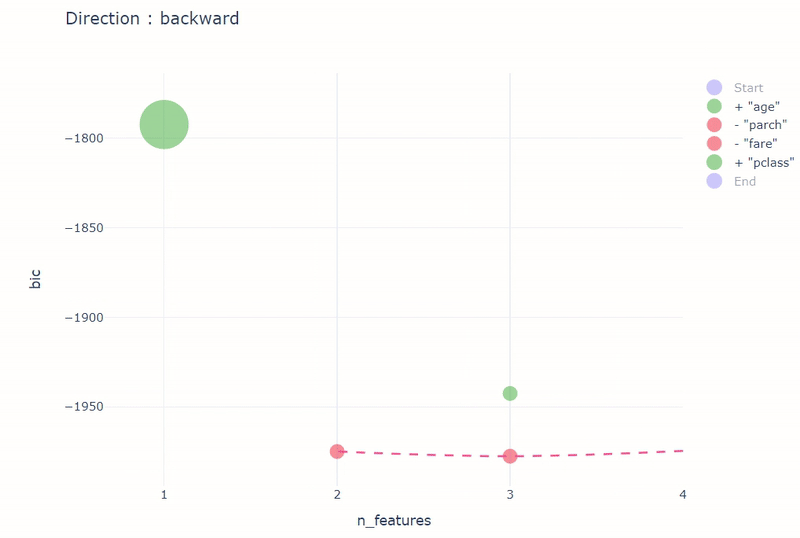
# titanic_vd is already loaded
# Logistic Regression model is already loaded
stepwise_result = stepwise(
model,
input_relation=titanic_vd,
X=[
"age",
"fare",
"parch",
"pclass",
],
y="survived",
direction="backward",
height=600,
width=800,
)
加载预定义数据集
VerticaPy提供了一些可以轻松加载的预定义数据集。这些数据集包括鸢尾花数据集、泰坦尼克号数据集、亚马逊数据集等。
访问提供的数据集有两种方式
(1) 使用标准的Python方法
from verticapy.datasets import load_iris
iris_data = load_iris()
(2) 使用公共模式中数据集的标准名称
iris_data = vp.vDataFrame(input_relation = "public.iris")
快速入门
以下示例遵循VerticaPy快速入门指南。
使用pip安装库。
root@ubuntu:~$ pip3 install verticapy[all]
创建一个新的Vertica连接
import verticapy as vp
vp.new_connection({
"host": "10.211.55.14",
"port": "5433",
"database": "testdb",
"password": "XxX",
"user": "dbadmin"},
name="Vertica_New_Connection")
使用新创建的连接
vp.connect("Vertica_New_Connection")
为原生VerticaPy模型创建VerticaPy模式(即VerticaPy中可用但Vertica本身不可用的模型)
vp.create_verticapy_schema()
为您的关联创建一个vDataFrame
from verticapy import vDataFrame
vdf = vDataFrame("my_relation")
加载一个示例数据集
from verticapy.datasets import load_titanic
vdf = load_titanic()
检查您的数据
vdf.describe()
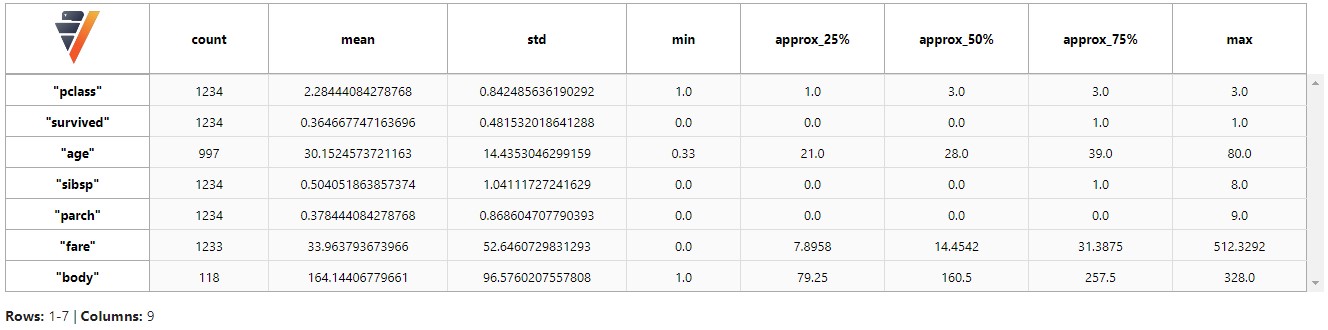
使用set_option打印SQL查询
set_option("sql_on", True)
vdf.describe()
# Output
## Compute the descriptive statistics of all the numerical columns ##
SELECT
SUMMARIZE_NUMCOL("pclass", "survived", "age", "sibsp", "parch", "fare", "body") OVER ()
FROM public.titanic
使用VerticaPy,现在可以用几行代码解决ML问题。
from verticapy.machine_learning.model_selection.model_validation import cross_validate
from verticapy.machine_learning.vertica import RandomForestClassifier
# Data Preparation
vdf["sex"].label_encode()["boat"].fillna(method="0ifnull")["name"].str_extract(
" ([A-Za-z]+)\."
).eval("family_size", expr="parch + sibsp + 1").drop(
columns=["cabin", "body", "ticket", "home.dest"]
)[
"fare"
].fill_outliers().fillna()
# Model Evaluation
cross_validate(
RandomForestClassifier("rf_titanic", max_leaf_nodes=100, n_estimators=30),
vdf,
["age", "family_size", "sex", "pclass", "fare", "boat"],
"survived",
cutoff=0.35,
)

# Features importance
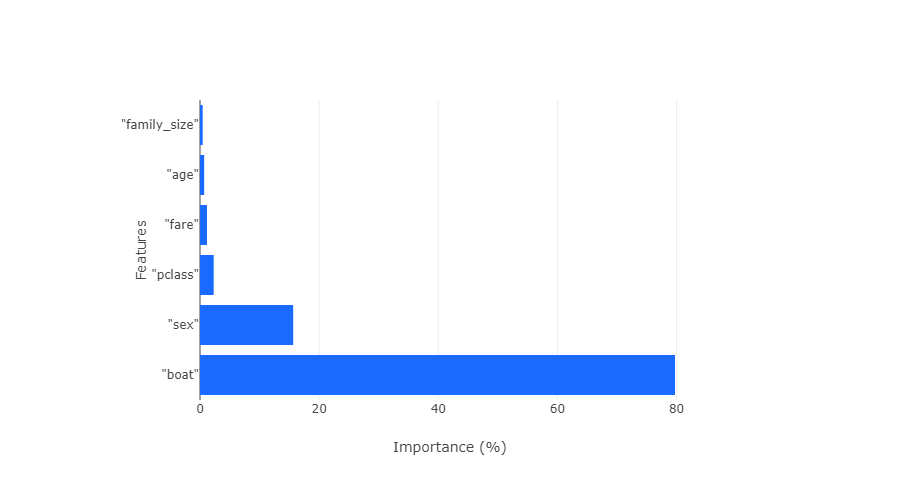
model.fit(vdf, ["age", "family_size", "sex", "pclass", "fare", "boat"], "survived")
model.features_importance()
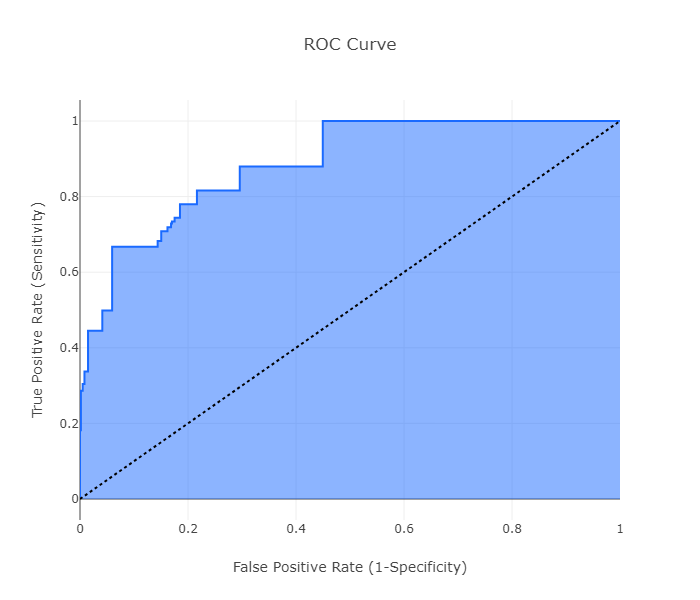
# ROC Curve
model = RandomForestClassifier(
name = "public.RF_titanic",
n_estimators = 20,
max_features = "auto",
max_leaf_nodes = 32,
sample = 0.7,
max_depth = 3,
min_samples_leaf = 5,
min_info_gain = 0.0,
nbins = 32
)
model.fit(
"public.titanic", # input relation
["age", "fare", "sex"], # predictors
"survived" # response
)
# Roc Curve
model.roc_curve()
享受吧!
帮助和支持
贡献
有关贡献标准的简要指南,请参阅贡献指南。
通讯


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。







