将Twitter数据保存到SQLite数据库

项目描述
twitter-to-sqlite




将Twitter数据保存到SQLite数据库。
- 如何安装
- 身份验证
- 通过特定账户检索推文
- 批量检索用户资料
- 批量检索推文
- 检索Twitter关注者
- 检索朋友
- 检索收藏的推文
- 检索Twitter列表
- 检索Twitter列表成员资格
- 检索关注者和朋友ID
- 从您的个人时间线检索推文
- 检索您的提及
- 使用--sql和--attach提供SQL查询的输入
- 运行搜索
- 使用track和follow实时捕获推文
- 从您的Twitter存档导入数据
- 设计笔记
如何安装
$ pip install twitter-to-sqlite
身份验证
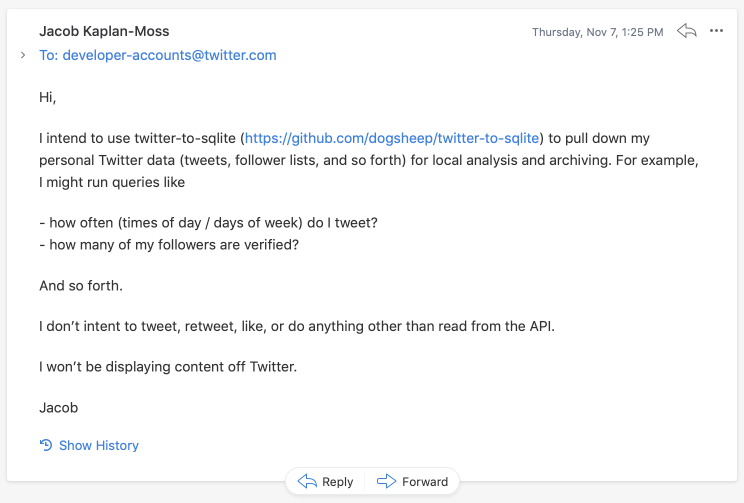
首先,您需要在https://developer.twitter.com/en/apps创建一个Twitter应用程序。您可能需要申请一个Twitter开发者账户 - 如果需要,您可能发现这个已批准的电子邮件应用程序示例很有用。
创建您的应用程序后,导航到“密钥和令牌”页面,并注意以下内容
- 您的API密钥
- 您的API密钥
- 您的访问令牌
- 您的访问令牌密钥
您需要将这四个值都保存到JSON文件中才能使用此工具。
您可以通过运行以下命令并粘贴提示中的值来创建该JSON文件
$ twitter-to-sqlite auth
Create an app here: https://developer.twitter.com/en/apps
Then navigate to 'Keys and tokens' and paste in the following:
API key: xxx
API secret key: xxx
Access token: xxx
Access token secret: xxx
这将创建一个名为auth.json的文件,位于您的当前目录中,包含所需值。要将文件保存在不同的路径或名称,请使用--auth=myauth.json选项。
通过特定账户检索推文
user-timeline命令检索指定用户账户发布的所有推文。默认为认证用户的账户
$ twitter-to-sqlite user-timeline twitter.db
Importing tweets [#####-------------------------------] 2799/17780 00:01:39
所有这些命令都假设当前目录中存在一个auth.json文件。您可以使用-a来提供您的auth.json文件的路径。
$ twitter-to-sqlite user-timeline twitter.db -a /path/to/auth.json
要加载其他用户的推文,请将它们的屏幕名作为参数传递。
$ twitter-to-sqlite user-timeline twitter.db cleopaws nichemuseums
Twitter的API通常只返回大多数用户账户的大约3,200条推文,但您可能会发现它为您自己的用户账户返回所有可用的推文。
您可以使用--ids参数传递数字Twitter用户ID而不是屏幕名。
您可以使用--since来检索自上次导入以来该用户的所有推文,或者使用--since_id=xxx来检索自特定推文ID以来的所有推文。
此命令还接受下面的--sql和--attach选项。
批量检索用户资料
如果您有一份Twitter屏幕名(或用户ID)列表,可以使用users-lookup命令批量获取他们的完整Twitter个人资料。
$ twitter-to-sqlite users-lookup users.db simonw cleopaws
您也可以使用--ids选项传递用户ID。
$ twitter-to-sqlite users-lookup users.db 12497 3166449535 --ids
此命令还接受下面的--sql和--attach选项。
批量检索推文
如果您有一份推文ID列表,可以使用statuses-lookup命令批量获取它们。
$ twitter-to-sqlite statuses-lookup tweets.db 1122154819815239680 1122154178493575169
支持--sql和--attach选项。
以下是一个获取任何推文的方法,这些推文是现有推文的in-reply-to,但尚未存储在您的数据库中。
$ twitter-to-sqlite statuses-lookup tweets.db \
--sql='
select in_reply_to_status_id
from tweets
where in_reply_to_status_id is not null' \
--skip-existing
--skip-existing选项表示已经存储在数据库中的推文将不会再次检索。
检索Twitter关注者
followers命令检索指定账户的每个粉丝的详细信息。您可以使用它来检索您自己的粉丝,或者您可以通过传递一个或多个屏幕名来拉取其他账户的粉丝。
以下命令检索您的粉丝并将它们保存到名为twitter.db的SQLite数据库文件中。
$ twitter-to-sqlite followers twitter.db
此命令非常慢,因为Twitter对端点实施了每分钟不超过一个请求的限制!如果您针对有数千个粉丝的账户运行它,您应该预计这需要几个小时。
要检索其他账户的粉丝,请使用
$ twitter-to-sqlite followers twitter.db cleopaws
此命令也接受--ids、--sql和--attach选项。
请参阅使用Datasette分析我的Twitter粉丝,了解此命令的原始灵感。
检索朋友
friends命令与followers命令类似,但它检索指定(或当前认证)用户的朋友,即在Twitter API术语中定义的账户,该用户正在关注。
$ twitter-to-sqlite friends twitter.db
它接受与followers命令相同的选项。
检索收藏的推文
favorites命令检索被指定用户收藏的推文。如果没有附加任何额外参数,它将检索当前认证用户收藏的推文。
$ twitter-to-sqlite favorites faves.db
您还可以使用--screen_name或--user_id参数来检索其他用户的收藏推文。
$ twitter-to-sqlite favorites faves-obama.db --screen_name=BarackObama
使用--stop_after=xxx参数仅检索最新的推文数量,例如,获取认证用户的50个最新收藏。
$ twitter-to-sqlite favorites faves.db --stop_after=50
检索Twitter列表
lists命令检索一个或多个用户的所有列表。
$ twitter-to-sqlite lists lists.db simonw dogsheep
此命令也接受--sql、--attach和--ids选项。
要进一步获取每个列表的成员列表,请使用--members。
检索Twitter列表成员资格
list-members命令可以用来检索一个或多个Twitter列表的详细信息,包括所有成员。
$ twitter-to-sqlite list-members members.db simonw/the-good-place
您可以通过传递多个screen_name/list_slug标识符。
如果您知道列表的数字ID,您可以使用--ids。
$ twitter-to-sqlite list-members members.db 927913322841653248 --ids
检索关注者和朋友ID
还有可能检索特定用户关注的账户的数字Twitter ID(在Twitter API术语中称为"朋友")或被关注的账户。
$ twitter-to-sqlite followers-ids members.db simonw cleopaws
此操作将填充以下表格,包含两个指定账户的 followed_id/follower_id 对,列出所有关注这两个账户之一的账户 ID。
$ twitter-to-sqlite friends-ids members.db simonw cleopaws
此操作将执行相同的功能,但提取这些账户所关注的 ID。
这两个命令也支持使用 --sql 和 --attach 作为直接在命令行参数中传递屏幕名称的替代方案。您可以使用 --ids 将输入作为用户 ID 而不是屏幕名称进行处理。
Twitter API 的底层 API 每隔 15 分钟限制为 15 个请求 - 虽然每个调用最多返回 5,000 个 ID。默认情况下,这两个子命令将在 API 调用之间等待 61 秒,以保持在速率限制内 - 如果您知道不会进行很多调用,则可以使用 --sleep=1 将此行为调整为仅延迟一秒。
从您的个人时间线检索推文
home-timeline 命令检索认证用户的主时间线中的最多 800 条推文 - 通常这意味着您关注的用户的推文。
$ twitter-to-sqlite home-timeline twitter.db
Importing timeline [#################--------] 591/800 00:01:14
推文存储在 tweets 表中,并在 timeline_tweets 表中添加一条记录,指出这条推文是由于在您用户的时间线中找到而进入的。
您可以使用 --since 仅检索自上次运行此命令以来发布的推文,或使用 --since_id=xxx 明确传递推文 ID 作为最后位置。
您可以使用以下 URL 在 Datasette 中查看您的推文时间线:
/tweets/tweets?_where=id+in+(select+tweet+from+[timeline_tweets])&_sort_desc=id&_facet=user
这将过滤您的推文表,仅包含出现在您时间线中的推文,按时间顺序排列,并使用分面显示哪些用户负责最多的推文。
检索您的提及
mentions-timeline 命令与 home-timeline 类似,除了它检索提到认证用户账户的推文。它将在 mentions_tweets 表中记录被提到的用户账户。
它支持与 home-timeline 相同的 --since 和 --since_id。
使用--sql和--attach提供SQL查询的输入
此选项对于某些子命令可用 - 运行 twitter-to-sqlite command-name --help 检查。
您可以直接作为命令行参数提供 Twitter 屏幕名称(或用户 ID 或推文 ID),或者您可以通过执行 SQL 查询来提供这些屏幕名称或 ID。
例如:考虑一个包含 attendees 表的 SQLite 数据库,列出名称和 Twitter 账户 - 类似这样
| 第一 | 最后 | |
|---|---|---|
| Simon | Willison | simonw |
| Avril | Lavigne | AvrilLavigne |
您可以使用 users-lookup 命令通过使用 --sql 查询加载屏幕名称来检索数据库中列出的每个用户的 Twitter 个人资料
$ twitter-to-sqlite users-lookup my.db --sql="select Twitter from attendees"
如果您的数据库表包含 Twitter ID,您可以选择这些 ID 并传递 --ids 参数。例如,要使用 twitter-to-sqlite friends-ids 命令检索已将用户 ID 插入 following 表中的用户的个人资料
$ twitter-to-sqlite users-lookup my.db --sql="select follower_id from following" --ids
或避免重新检索已检索的用户
$ twitter-to-sqlite users-lookup my.db \
--sql="select followed_id from following where followed_id not in (
select id from users)" --ids
如果您的数据位于单独的数据库文件中,您可以使用 --attach 将其附加。例如,考虑上述示例,但数据位于 attendees.db 文件中,并且您希望将用户个人资料提取到 tweets.db 文件中。您可以这样做
$ twitter-to-sqlite users-lookup tweets.db \
--attach=attendees.db \
--sql="select Twitter from attendees.attendees"
文件名(不带扩展名)将用作 SQLite 中的数据库别名。如果出于某种原因您希望使用不同的别名,您可以使用冒号指定,如下所示
$ twitter-to-sqlite users-lookup tweets.db \
--attach=foo:attendees.db \
--sql="select Twitter from foo.attendees"
运行搜索
search 命令针对 Twitter 的 标准搜索 API 运行搜索。
$ twitter-to-sqlite search tweets.db "dogsheep"
这将导入最多约320条与搜索词匹配的推文到tweets表中。它还会在search_runs表中创建一条记录,记录搜索发生的情况,以及在search_runs_tweets表中创建多对多记录,记录当时看到哪些推文。
您可以使用--since参数来检查具有相同参数的先前搜索运行,并且只检索自上次检索到的匹配推文以来的推文。
以下是对search支持的附加选项
--geocode:格式为纬度,经度,半径,其中半径是一个后面跟mi或km的数字--lang:ISO 639-1语言代码,例如en或es--locale:区域设置:目前只有ja有效--result_type:mixed、recent或popular。默认为mixed--count:每页的结果数,默认为100的最大值--stop_after:停止后的结果数--since_id:从此推文ID开始拉取推文。您可能想使用--since而不是此选项。
使用track和follow实时捕获推文
此功能是实验性的。如果您发现任何问题,请提交错误报告!
Twitter提供了一个实时API,可以用来订阅正在发生的推文。twitter-to-sqlite可以使用此API不断更新SQLite数据库,以包含匹配某些关键词或引用特定用户的推文。
track
要跟踪关键词,请使用track命令
$ twitter-to-sqlite track tweets.db kakapo
此命令将持续运行,直到您按Ctrl+C。它将捕获任何提及关键词kakapo的推文,并将它们存储在tweets.db数据库文件中。
您可以传递多个关键词作为空格分隔的列表。这将捕获匹配这些关键词中的任何一个的推文
$ twitter-to-sqlite track tweets.db kakapo raccoon
您可以将短语放在引号内,以搜索匹配这两个关键词的推文
$ twitter-to-sqlite track tweets.db 'trash panda'
有关使用此命令的高级提示,请参阅Twitter track文档
添加--verbose选项以在终端中显示捕获到的匹配推文(以它们的详细JSON形式)
$ twitter-to-sqlite track tweets.db raccoon --verbose
follow
follow命令将捕获与一个或多个特定Twitter用户相关的所有推文。
$ twitter-to-sqlite follow tweets.db nytimes
这包括这些用户的推文、回复或引用这些用户的推文以及该用户转发的推文。有关详细信息,请参阅Twitter follow文档
该命令接受一个或多个屏幕名。
您可以使用--ids标志使用数字Twitter用户ID而不是屏幕名。
该命令还支持--sql和--attach选项,以及用于显示捕获到的推文的--verbose选项。
以下是如何开始关注following表中当前表示为关注的每个用户ID的推文(使用friends-ids命令填充)
$ twitter-to-sqlite follow tweets.db \
--sql="select distinct followed_id from following" \
--ids
从您的Twitter存档导入数据
您可以通过遵循这些说明来请求您的Twitter数据存档。
Twitter会发送一个链接,您可以下载一个.zip文件。您可以使用import命令将此文件的包含内容导入到名为archive.db的新数据库文件中的某些表(每个表以archive_前缀开始)
$ twitter-to-sqlite import archive.db ~/Downloads/twitter-2019-06-25-b31f2.zip
此命令不会填充任何常规表,因为Twitter的导出数据与Twitter API返回的模式不完全匹配。
每次运行它时都会删除并重新创建相应的archive_*表。如果您不希望这样做,请针对一个新SQLite数据库文件名运行该命令,而不是针对已经存在的文件运行。
如果您已经解压了存档,您可以对解压到的目录运行此命令
$ twitter-to-sqlite import archive.db ~/Downloads/twitter-2019-06-25-b31f2/
您还可以运行它来处理该文件夹中的一个或多个特定文件。例如,要导入follower.js和following.js文件
$ twitter-to-sqlite import archive.db \
~/Downloads/twitter-2019-06-25-b31f2/follower.js \
~/Downloads/twitter-2019-06-25-b31f2/following.js
您可能想使用其他命令来根据存档中的数据填充表格。例如,要检索存档中您喜欢的每条推文的完整API版本,您可以运行以下命令
$ twitter-to-sqlite statuses-lookup archive.db \
--sql='select tweetId from archive_like' \
--skip-existing
如果您希望导入的推文反映在favorited_by表中,您可以执行以下SQL查询来实现
$ sqlite3 archive.db
SQLite version 3.22.0 2018-01-22 18:45:57
Enter ".help" for usage hints.
sqlite> INSERT OR IGNORE INTO favorited_by (tweet, user)
...> SELECT tweetId, 'YOUR_TWITTER_ID' FROM archive_like;
<Ctrl+D>
将YOUR_TWITTER_ID替换为您的数字Twitter ID。如果您不知道该ID,可以通过运行以下命令来查找
$ twitter-to-sqlite fetch \
"https://api.twitter.com/1.1/account/verify_credentials.json" \
| grep '"id"' | head -n 1
设计笔记
- 推文ID存储为整数,以便可以通过ID进行合理的排序
- 当我们配置表之间的外键关系时,我们不要求SQLite强制执行它们。这由
following表使用,以允许followers-ids和friends-ids命令用用户ID填充它,即使用户账户尚未在users表中


下载文件
下载适合您平台的自定义文件。如果您不确定选择哪一个,请了解更多关于安装包的信息。
源代码分发
构建分发
twitter-to-sqlite-0.22.tar.gz的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | fbc9a0cc525d3ded4638df6e1aa4608135490bd7279ebf38abbb98d79ae1a200 |
|
| MD5 | ccb2a56b9a6269d410c953b535051a2c |
|
| BLAKE2b-256 | 485fe1ebc7a6140f04c7020a85d80e91e729919a48c8bed427cd03f1cd1b8bb5 |
twitter_to_sqlite-0.22-py3-none-any.whl的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | d45a8f4fce2dd73ff96554823a42be637c0fe9b2712913330d81bdb886dd7a2f |
|
| MD5 | dcb4dc06718b02f4410ff87575b0702d |
|
| BLAKE2b-256 | c47b622fc8f04d477c4cf93a48478d0e1dc7b8f0d05dae2b911f797a7645e0a6 |








{kind=link}