小巧可定制的多进程多代理爬虫。

项目描述






一个高度可定制的爬虫,使用多进程和代理根据给定的过滤器、搜索和保存功能下载一个或多个网站。
请记住DDoS是非法的。请不要将此软件用于非法目的。
安装TinyCrawler
pip install tinycrawler预览(测试用例)
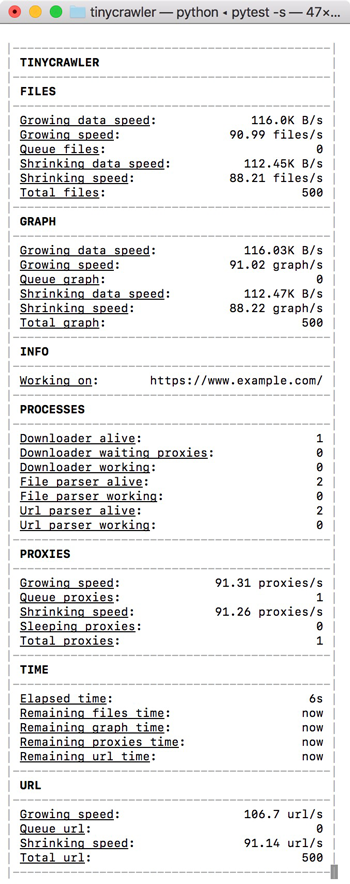
这是运行test_base.py时的控制台预览。
使用示例
from tinycrawler import TinyCrawler, Log, Statistics
from bs4 import BeautifulSoup, SoupStrainer
import pandas as pd
from requests import Response
from urllib.parse import urlparse
import os
import json
def html_sanitization(html: str) -> str:
"""Return sanitized html."""
return html.replace("WRONG CONTENT", "RIGHT CONTENT")
def get_product_name(response: Response) -> str:
"""Return product name from given Response object."""
return response.url.split("/")[-1].split(".html")[0]
def get_product_category(soup: BeautifulSoup) -> str:
"""Return product category from given BeautifulSoup object."""
return soup.find_all("span")[-2].get_text()
def parse_tables(html: str, path: str, strainer: SoupStrainer):
"""Parse table at given strained html object saving them as csv at given path."""
for table in BeautifulSoup(
html, "lxml", parse_only=strainer).find_all("table"):
df = pd.read_html(html_sanitization(str(table)))[0].drop(0)
table_name = df.columns[0]
df.set_index(table_name, inplace=True)
df.to_csv("{path}/{table_name}.csv".format(
path=path, table_name=table_name))
def parse_metadata(html: str, path: str, strainer: SoupStrainer):
"""Parse metadata from given strained html and saves them as json at given path."""
with open("{path}/metadata.json".format(path=path), "w") as f:
json.dump({
"category":
get_product_category(
BeautifulSoup(html, "lxml", parse_only=strainer))
}, f)
def parse(response: Response):
path = "{root}/{product}".format(
root=urlparse(response.url).netloc, product=get_product_name(response))
if not os.path.exists(path):
os.makedirs(path)
parse_tables(
response.text, path,
SoupStrainer(
"table",
attrs={"class": "table table-hover table-condensed table-fixed"}))
parse_metadata(
response.text, path,
SoupStrainer("span"))
def url_validator(url: str, logger: Log, statistics: Statistics)->bool:
"""Return a boolean representing if the crawler should parse given url."""
return url.startswith("https://www.example.com/it/alimenti"")
def file_parser(response: Response, logger: Log, statistics):
if response.url.endswith(".html"):
parse(response)
seed = "https://www.example.com/it/alimenti"
crawler = TinyCrawler(follow_robots_txt=False)
crawler.set_file_parser(file_parser)
crawler.set_url_validator(url_validator)
crawler.load_proxies("http://mytestserver.domain", "proxies.json")
crawler.run(seed)代理应采用以下格式
[
{
"ip": "89.236.17.108",
"port": 3128,
"type": [
"https",
"http"
]
},
{
"ip": "128.199.141.151",
"port": 3128,
"type": [
"https",
"http"
]
}
]许可证
本软件采用MIT许可证发布。









