将时间序列数据(例如电子健康记录)转换为宽格式数据的软件包。

项目描述
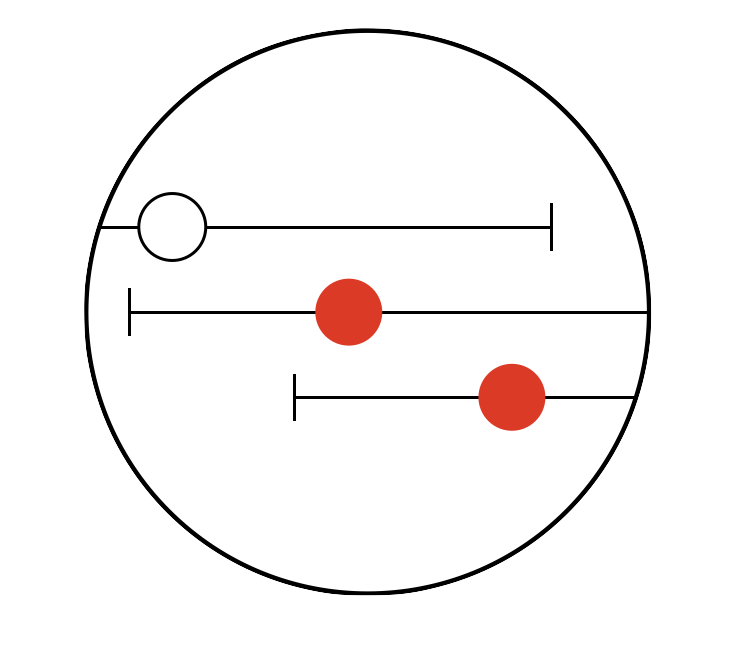
Timeseriesflattener




来自电子健康记录等的时间序列数据通常具有大量变量,以不规则的时间间隔采样,并且往往具有大量缺失值。在可以使用机器学习方法(如逻辑回归或XGBoost)进行预测建模之前,需要对这些数据进行重塑。
本质上,需要将时间序列展平,以便每个预测时间由一组预测值和一个结果值表示。这些预测值可以通过在一定时间窗口内聚合时间序列中的先前值来构建。
timeseriesflattener旨在通过提供易于使用且完全指定的流程来简化复杂时间序列的展平过程。
🔧 安装
要开始使用timeseriesflattener,只需使用pip安装,在您的终端中运行以下行
pip install timeseriesflattener
⚡ 快速开始
import datetime as dt
import numpy as np
import polars as pl
# Load a dataframe with times you wish to make a prediction
prediction_times_df = pl.DataFrame(
{"id": [1, 1, 2], "date": ["2020-01-01", "2020-02-01", "2020-02-01"]}
)
# Load a dataframe with raw values you wish to aggregate as predictors
predictor_df = pl.DataFrame(
{
"id": [1, 1, 1, 2],
"date": ["2020-01-15", "2019-12-10", "2019-12-15", "2020-01-02"],
"predictor_value": [1, 2, 3, 4],
}
)
# Load a dataframe specifying when the outcome occurs
outcome_df = pl.DataFrame({"id": [1], "date": ["2020-03-01"], "outcome_value": [1]})
# Specify how to aggregate the predictors and define the outcome
from timeseriesflattener import (
MaxAggregator,
MinAggregator,
OutcomeSpec,
PredictionTimeFrame,
PredictorSpec,
ValueFrame,
)
predictor_spec = PredictorSpec(
value_frame=ValueFrame(
init_df=predictor_df, entity_id_col_name="id", value_timestamp_col_name="date"
),
lookbehind_distances=[dt.timedelta(days=1)],
aggregators=[MaxAggregator(), MinAggregator()],
fallback=np.nan,
column_prefix="pred",
)
outcome_spec = OutcomeSpec(
value_frame=ValueFrame(
init_df=outcome_df, entity_id_col_name="id", value_timestamp_col_name="date"
),
lookahead_distances=[dt.timedelta(days=1)],
aggregators=[MaxAggregator(), MinAggregator()],
fallback=np.nan,
column_prefix="outc",
)
# Instantiate TimeseriesFlattener and add the specifications
from timeseriesflattener import Flattener
result = Flattener(
predictiontime_frame=PredictionTimeFrame(
init_df=prediction_times_df, entity_id_col_name="id", timestamp_col_name="date"
)
).aggregate_timeseries(specs=[predictor_spec, outcome_spec])
result.df
输出
| id | date | prediction_time_uuid | pred_test_feature_within_30_days_mean_fallback_nan | outc_test_outcome_within_31_days_maximum_fallback_0_dichotomous | |
|---|---|---|---|---|---|
| 0 | 1 | 2020-01-01 00:00:00 | 1-2020-01-01-00-00-00 | 2.5 | 0 |
| 1 | 1 | 2020-02-01 00:00:00 | 1-2020-02-01-00-00-00 | 1 | 1 |
| 2 | 2 | 2020-02-01 00:00:00 | 2-2020-02-01-00-00-00 | 4 | 0 |
📖 教程
💬 哪里可以提问
| 类型 | |
|---|---|
| 🚨 错误报告 | GitHub问题跟踪器 |
| 🎁 功能请求和想法 | GitHub问题跟踪器 |
| 👩💻 使用问题 | GitHub 讨论区 |
| 🗯 通用讨论 | GitHub 讨论区 |
🎓 项目
PSYCOP 项目使用 timeseriesflattener,更多详情请参阅 monorepo。


下载文件
下载适用于您的平台的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。
源代码分发
timeseriesflattener-2.4.0.tar.gz (9.6 MB 查看散列)
构建分发
关闭
timeseriesflattener-2.4.0.tar.gz 的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 72e67a1daf75df89d10d19a6a4da4e4ce58894a09f56a620d459ad618055d74e |
|
| MD5 | bfe9583584e14e07fea54afd438bf4d0 |
|
| BLAKE2b-256 | 7aaf787698d5417f58aebc54322b97194f491ab1234fc580f39be38348374a9d |
关闭
timeseriesflattener-2.4.0-py3-none-any.whl 的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | bba93d5e35112689adc671231a6994cb4024cbc0ca697aa950c748445d8b91a2 |
|
| MD5 | 69db11b5e47534a5d95505bab38bbaf8 |
|
| BLAKE2b-256 | 39ea17b134b912fa8465e441be9d1818d1b8e30758fa22d00aec71318280fac3 |







