一般时间序列数据的统计测试和绘图函数,

项目描述
时间序列测试
针对一般时间序列数据的统计测试和绘图函数,特别是针对认知眼动追踪和脑电图(EEG)实验中的数据。基于线性混合效应模型(或常规多重线性回归)、交叉验证和基于聚类的置换测试。
Sebastiaan Mathôt (@smathot)
版权 2021 - 2024


内容
引用
Mathôt, S., & Vilotijević, A. (2022). 认知眼动追踪方法:设计、预处理和分析. 行为研究方法. https://doi.org/10.1101/2022.02.23.481628
关于
此库提供了两个主要功能用于时间序列数据的统计测试:lmer_crossvalidation_test() 和 lmer_permutation_test()。有关详细信息,请参阅上面的手稿,但以下是对这两个函数及其各自的优缺点进行简要介绍。
何时使用交叉验证?
一般来说,lmer_crossvalidation_test() 实现了分析时间序列数据时对特定但常见问题的统计测试
一个或多个独立变量是否在任何时间点影响一个连续记录的因变量(即“时间序列”)?
何时使用此测试
- 对于只包含一个成分的时间序列,即当每个独立变量只对时间序列有单一影响时。例如,当呈现不同强度的光闪光时,对瞳孔大小的刺激强度的影响。
- 当您不知道事先要测试哪些时间点时。
何时不使用此测试
- 对于包含多个成分的时间序列,即每个独立变量以多种方式影响时间序列,并且这些方式随时间变化。例如,视觉注意力对侧化脑电图记录的影响,其中不同的脑电图成分在不同时间点出现。
- 当你事先知道要测试哪些时间点时。
更具体地说,lmer_crossvalidation_test()在时间序列数据中定位和统计检验效应。它是通过交叉验证来识别测试时间点,然后使用线性混合效应模型来实际进行统计检验。更具体地说,数据被细分为多个子集(默认为4个)。它从完整数据集中取出一个子集(测试集),并对剩余数据的每个样本(训练集)进行线性混合效应模型分析。训练集中绝对z值最高的样本用作测试集的测试样本。这个过程对数据的所有子集和模型的所有固定效应都重复进行。最后,对因此确定的样本中的每个固定效应进行单个线性混合效应模型分析。
此包还提供了一个函数(plot())来可视化时间序列数据,以便直观地注释lmer_crossvalidation_test()的结果。
何时使用lmer_permutation_test()?
lmer_permutation_test()实现了一种相当标准的基于聚类的置换检验,与其他大多数实现的不同之处在于,它依赖于线性混合效应模型来计算检验统计量。因此,此函数的计算量可能非常大,但应该比基于平均数据的基于聚类的置换检验更敏感。与lmer_crossvalidation_test()相比,它的主要优势是它也适用于具有多个成分的数据,例如事件相关电位(ERPs)。
测试也可以基于常规多重回归(而不是线性混合效应模型)吗?
是的。如果你将任何函数中的groups=None传递,分析将基于常规多重线性回归而不是线性混合效应模型。
安装
pip install time_series_test
依赖项
用法
我们将使用来自Zhou, Lorist, and Mathôt (2021)的数据。简而言之,这是来自视觉工作记忆实验的数据,在该实验中,参与者在3秒的保持期内记住了一种或多种颜色(集合大小:1,2,3或4),同时记录瞳孔大小。
此数据集包含以下列
pupil,这是我们的因变量。它是一个基线校正的瞳孔时间序列,包含300个样本,以100 Hz记录subject_nr,我们将将其用作随机效应set_size,我们将将其用作固定效应color_type,我们将将其用作固定效应
首先,加载数据集
from datamatrix import io
dm = io.readpickle('data/zhou_et_al_2021.pkl')
plot()函数提供了一个方便的方式来绘制瞳孔大小随时间变化作为一个或两个因素(在这种情况下为集合大小和颜色类型)的函数
import time_series_test as tst
from matplotlib import pyplot as plt
tst.plot(dm, dv='pupil', hue_factor='set_size', linestyle_factor='color_type',
sampling_freq=100)
plt.savefig('img/signal-plot-1.png')
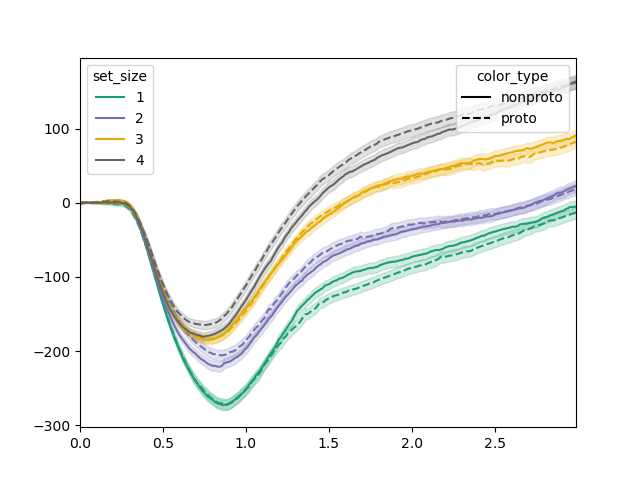
从这个图中,我们可以看出,在1500到2000毫秒的时间间隔内似乎有效应。为了检验这一点,我们可以对这个区间进行线性混合效应模型分析,这对应于样本150到200。
下方的模型使用150-200样本范围内的平均瞳孔大小作为因变量,将设置大小和颜色类型设为固定效应,随机效应为按主体截距。在R包lme4中更熟悉的记法中,这对应于mean_pupil ~ set_size * color_type + (1 | subject_nr)。(要使用更复杂的随机效应结构,可以使用mixedlm()函数的re_formula参数。)
from statsmodels.formula.api import mixedlm
from datamatrix import series as srs, NAN
dm.mean_pupil = srs.reduce(dm.pupil[:, 150:200])
dm_valid_data = dm.mean_pupil != NAN
model = mixedlm(formula='mean_pupil ~ set_size * color_type',
data=dm_valid_data, groups='subject_nr').fit()
print(model.summary())
输出
Mixed Linear Model Regression Results
=============================================================================
Model: MixedLM Dependent Variable: mean_pupil
No. Observations: 7300 Method: REML
No. Groups: 30 Scale: 38610.3390
Min. group size: 235 Log-Likelihood: -48952.3998
Max. group size: 248 Converged: Yes
Mean group size: 243.3
-----------------------------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
-----------------------------------------------------------------------------
Intercept -144.024 17.438 -8.259 0.000 -178.202 -109.846
color_type[T.proto] -24.133 11.299 -2.136 0.033 -46.278 -1.987
set_size 49.979 2.906 17.200 0.000 44.284 55.675
set_size:color_type[T.proto] 10.176 4.120 2.470 0.014 2.101 18.251
subject_nr Var 7217.423 9.882
=============================================================================
模型摘要显示,假设α水平为.05,颜色类型(z = -2.136,p = .033)、设置大小(z = 17.2,p < .001)和颜色类型与设置大小的交互作用(z = 2.47,p = .014)具有显著的主效应。然而,我们选择性地分析了已知的数据样本范围,基于对数据的视觉检查,以显示这些效应。这意味着我们的分析是循环的:我们查看数据以决定在哪里查看!find()函数通过将数据分为训练集和测试集来改善这一点,如关于中所述,从而打破了循环性。
results = tst.find(dm, 'pupil ~ set_size * color_type',
groups='subject_nr', winlen=5)
find()的返回值是一个dict,其中键是效应标签,值是以下命名的元组
model:由mixedlm().fit()返回的模型samples:一个包含使用样本索引的setp:模型的p值z:模型的z值
summarize()函数是一种方便的方法,可以以人类可读的格式获取结果。
print(tst.summarize(results))
输出
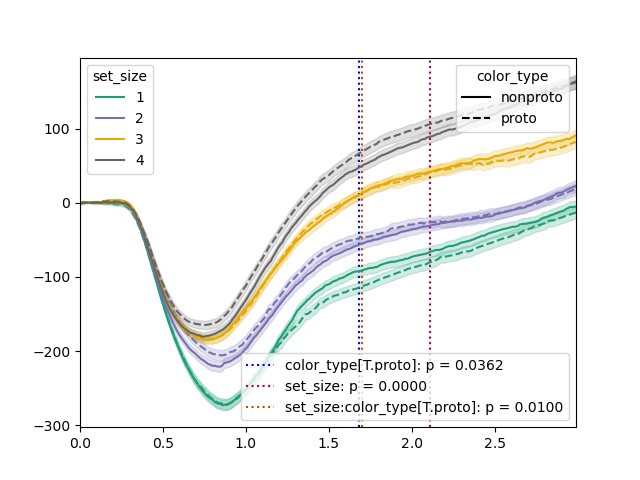
Intercept was tested at samples {95} → z = -13.1098, p = 2.892e-39, converged = yes
color_type[T.proto] was tested at samples {160, 170, 175} → z = -2.0949, p = 0.03618, converged = yes
set_size was tested at samples {185, 210, 195, 255} → z = 16.2437, p = 2.475e-59, converged = yes
set_size:color_type[T.proto] was tested at samples {165, 175} → z = 2.5767, p = 0.009974, converged = yes
我们可以将results传递给plot()来可视化结果
plt.clf()
tst.plot(dm, dv='pupil', hue_factor='set_size', linestyle_factor='color_type',
results=results, sampling_freq=100)
plt.savefig('img/signal-plot-2.png')
函数参考
time_series_test.lmer_crossvalidation_test(dm, formula, groups, re_formula=None, winlen=1, split=4, split_method='interleaved', samples_fe=True, samples_re=True, localizer_re=False, fit_method=None, suppress_convergence_warnings=False, fit_kwargs=None, **kwargs)
对时间序列执行单个线性混合效应模型,通过交叉验证确定要测试的样本。
此函数使用来自statsmodels包的mixedlm()。有关参数的更详细说明,请参阅statsmodels文档。
参数
-
dm: 数据矩阵
数据集
-
formula: str
描述因变量的公式,应在
dm中是系列列的名称,以及固定效应,应在dm中是常规(非系列)列。 -
groups: str或None或str列表
随机效应的组,应在
dm中是常规(非系列)列。如果指定了None,则所有分析都基于常规多重线性回归(而不是线性混合效应模型)。 -
re_formula: str或None
描述随机效应的公式,应在
dm中是常规(非系列)列。 -
winlen: int,可选
应一起分析样本的数量,即下采样窗口以加快分析速度。
-
split: int,可选
分析应基于的分割数。
-
split_method: str,可选
如果为'interleaved',则按常规交错方式分割数据,即第一行进入第一个子集,第二行进入第二个子集等。如果为'random',则随机分割成子集。交错分割是确定性的(即每次结果都相同),但随机分割不是。
-
samples_fe: bool,可选
指示是否将样本索引包括为固定效应公式中的加性因子。如果所有分割都产生了相同的样本索引,则忽略此选项。
-
samples_re: bool,可选
指示是否将样本索引包括为随机效应公式中的加性因子。如果所有分割都产生了相同的样本索引,则忽略此选项。
-
localizer_re: bool,可选
指示是否应使用使用
re_formula关键字指定的随机效应结构来为局部化模型,或仅用于最终模型。 -
fit_kwargs: dict或None,可选
一个用作
mixedlm.fit()关键字参数的dict。例如,要指定nm为拟合方法,指定fit_kwargs={'fit': 'nm'}。 -
fit_method: str,str列表或None,可选
已弃用。请使用
fit_kwargs代替。 -
suppress_convergence_warnings: bool,可选
安装一个警告过滤器来抑制收敛(和其他)警告。
-
**kwargs: dict,可选
传递给
mixedlm()的可选关键字。
返回
-
dict
一个字典,其中键是效应标签,值是包含
model、samples、p和z的命名元组的元组。
time_series_test.lmer_permutation_test(dm, formula, groups, re_formula=None, winlen=1, suppress_convergence_warnings=False, fit_kwargs={}, iterations=1000, cluster_p_threshold=0.05, test_intercept=False, **kwargs)
执行基于样本样本的线性混合效应分析的聚类置换检验。置换检验根据p值阈值识别聚类,并使用聚类中z值的总和的绝对值作为检验统计量。
如果没有任何聚类达到阈值,则立即跳过测试。默认情况下,忽略截距对此标准,因为截距通常具有我们不感兴趣的显著聚类。但是,您可以使用test_intercept关键字来更改此设置。
警告:这通常是一个非常耗时的分析,因为它需要运行数千个lmer。
有关参数的解释,请参阅lmer_crossvalidation()。
参数
-
dm: 数据矩阵
-
formula: str
-
groups: str
-
re_formula: str或None,可选
-
winlen: int,可选
-
suppress_convergence_warnings: bool,可选
-
fit_kwargs: dict,可选
-
iterations: int,可选
要运行的置换数。
-
cluster_p_threshold: float或None,可选
一个样本的最大p值,以被认为是聚类的一部分。
-
test_intercept: bool,可选
指示在考虑是否存在聚类时是否应包括截距,如上所述。
-
**kwargs: dict,可选
返回
-
dict
一个字典,其中效应作为键,由(开始,结束,z值总和,命中比例)元组定义的聚类列表。
time_series_test.lmer_series(dm, formula, winlen=1, fit_kwargs={}, **kwargs)
执行样本样本的线性混合效应分析。有关参数的解释,请参阅lmer_crossvalidation()。
参数
-
dm: 数据矩阵
-
formula: str
-
winlen: int,可选
-
fit_kwargs: dict,可选
-
**kwargs: dict,可选
返回
-
DataMatrix
一个DataMatrix,每行一个效应,包括截距,有三个与公式中指定的因变量的依赖度相同的系列列。
est:斜率p:p值z:z值se:标准误差
time_series_test.plot(dm, dv, hue_factor, results=None, linestyle_factor=None, hues=None, linestyles=None, alpha_level=0.05, annotate_intercept=False, annotation_hues=None, annotation_linestyle=':', legend_kwargs=None, annotation_legend_kwargs=None, x0=0, sampling_freq=1)
可视化时间序列,其中信号作为样本编号的函数绘制在x轴上。一个固定效应由线的色调(颜色)表示。可选的第二个固定效应由线型表示。如果使用results参数,则在图中注释显著效应。
参数
-
dm: 数据矩阵
数据集
-
dv: str
因变量的名称,它应该是
dm中的系列列。 -
hue_factor: str
dm中的常规(非系列)列的名称,它指定线的色调(颜色)。 -
results: dict,可选
由
lmer_crossvalidation()返回的results字典。 -
linestyle_factor: str,可选
dm中的常规(非系列)列的名称,它指定双因素图的线型。 -
hues: str,列表或None,可选
matplotlib色彩映射的名称或用于色调因子的色调列表。
-
linestyles: 列表或None,可选
用于第二个因子的线型列表。
-
alpha_level: float,可选
用于注释图中效应的alpha水平(最大p值)。
-
annotate_intercept: bool,可选
指定是否应将截距与固定效应一起注释。
-
annotation_hues: str,list 或 None,可选
matplotlib 色彩映射或用于注释的色调列表的名称,如果提供了
results。 -
annotation_linestyle: str,可选
注释的线型。
-
legend_kwargs: None 或 dict,可选
传递给
plt.legend()的可选关键字,用于因子图例。 -
annotation_legend_kwargs: None 或 dict,可选
传递给
plt.legend()的可选关键字,用于注释图例。 -
x0: int,float
坐标轴上的起始值。
-
sampling_freq: int,float
采样频率。
time_series_test.summarize(results, detailed=False)
生成一个字符串,其中包含由 lmer_crossvalidation() 返回的结果 dict 的人类可读摘要。
参数
-
results: dict
由
lmer_crossvalidation()返回的results字典。 -
detailed: bool,可选
指示是否应在摘要中包含模型详细信息。
返回
- str
许可协议
time_series_test 根据 GNU 通用公共许可证 v3 许可。


下载文件
下载适合您平台的文件。如果您不确定要选择哪一个,请了解有关 安装软件包 的更多信息。







