用于自然语言处理应用的文本增强库。

项目描述
TextAugment:通过全局增强方法改进短文本分类








您已找到TextAugment。
TextAugment是一个用于自然语言处理应用的Python 3库,它站在NLTK、Gensim v3.x和TextBlob的巨人肩膀上,并与它们很好地协作。
目录
特性
- 生成用于改进模型性能的合成数据,无需人工努力
- 简单、轻量级、易于使用的库。
- 即可插入任何机器学习框架(例如PyTorch、TensorFlow、Scikit-learn)
- 支持文本数据
引用论文
要求
- Python 3
以下软件包是依赖项,将自动安装。
$ pip install numpy nltk gensim==3.8.3 textblob googletrans
以下代码下载了wordnet的NLTK语料库。
nltk.download('wordnet')
以下代码下载NLTK分词器。这个分词器通过使用无监督算法建立缩写词、搭配词和句子开头词的模型来将文本分割成句子列表。
nltk.download('punkt')
以下代码下载默认的NLTK词性标注模型。词性标注器处理一系列词语,并为每个词语添加词性标签。
nltk.download('averaged_perceptron_tagger')
使用gensim加载预训练的word2vec模型。例如,从谷歌新闻加载。
import gensim
model = gensim.models.KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin', binary=True)
您还可以使用gensim加载Facebook的Fasttext英语和多语言模型
import gensim
model = gensim.models.fasttext.load_facebook_model('./cc.en.300.bin.gz')
或者使用您自己的数据或以下公共数据集从头开始训练
安装
从pip安装[推荐]
$ pip install textaugment
or install latest release
$ pip install git+git@github.com:dsfsi/textaugment.git
从源代码安装
$ git clone git@github.com:dsfsi/textaugment.git
$ cd textaugment
$ python setup.py install
如何使用
可以使用三种类型的增强
- word2vec
from textaugment import Word2vec
- fasttext
from textaugment import Fasttext
- wordnet
from textaugment import Wordnet
- 翻译(这将需要互联网访问)
from textaugment import Translate
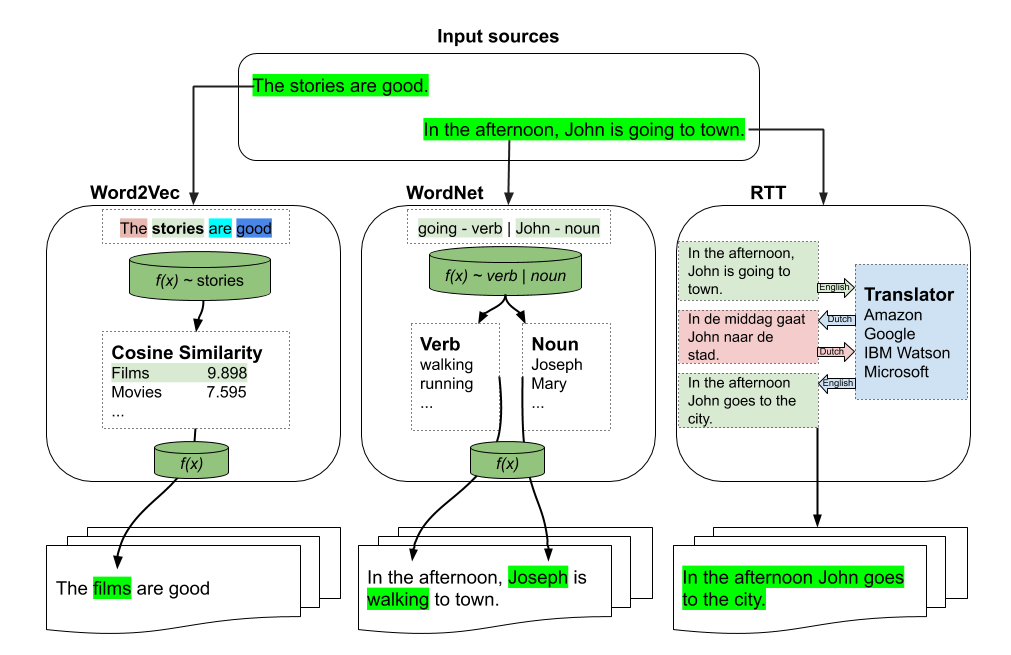
基于Fasttext/Word2vec的增强
基本示例
>>> from textaugment import Word2vec, Fasttext
>>> t = Word2vec(model='path/to/gensim/model'or 'gensim model itself')
>>> t.augment('The stories are good')
The films are good
>>> t = Fasttext(model='path/to/gensim/model'or 'gensim model itself')
>>> t.augment('The stories are good')
The films are good
高级示例
>>> runs = 1 # By default.
>>> v = False # verbose mode to replace all the words. If enabled runs is not effective. Used in this paper (https://www.cs.cmu.edu/~diyiy/docs/emnlp_wang_2015.pdf)
>>> p = 0.5 # The probability of success of an individual trial. (0.1<p<1.0), default is 0.5. Used by Geometric distribution to selects words from a sentence.
>>> word = Word2vec(model='path/to/gensim/model'or'gensim model itself', runs=5, v=False, p=0.5)
>>> word.augment('The stories are good', top_n=10)
The movies are excellent
>>> fast = Fasttext(model='path/to/gensim/model'or'gensim model itself', runs=5, v=False, p=0.5)
>>> fast.augment('The stories are good', top_n=10)
The movies are excellent
基于WordNet的增强
基本示例
>>> import nltk
>>> nltk.download('punkt')
>>> nltk.download('wordnet')
>>> from textaugment import Wordnet
>>> t = Wordnet()
>>> t.augment('In the afternoon, John is going to town')
In the afternoon, John is walking to town
高级示例
>>> v = True # enable verbs augmentation. By default is True.
>>> n = False # enable nouns augmentation. By default is False.
>>> runs = 1 # number of times to augment a sentence. By default is 1.
>>> p = 0.5 # The probability of success of an individual trial. (0.1<p<1.0), default is 0.5. Used by Geometric distribution to selects words from a sentence.
>>> t = Wordnet(v=False ,n=True, p=0.5)
>>> t.augment('In the afternoon, John is going to town', top_n=10)
In the afternoon, Joseph is going to town.
基于RTT的增强
示例
>>> src = "en" # source language of the sentence
>>> to = "fr" # target language
>>> from textaugment import Translate
>>> t = Translate(src="en", to="fr")
>>> t.augment('In the afternoon, John is going to town')
In the afternoon John goes to town
EDA:提升文本分类任务性能的简单数据增强技术
这是Jason Wei和Kai Zou实现的EDA实现。
https://www.aclweb.org/anthology/D19-1670.pdf
同义词替换
随机选择句子中不是停用词的n个词语。随机将这些词语中的一个同义词替换。
基本示例
>>> from textaugment import EDA
>>> t = EDA()
>>> t.synonym_replacement("John is going to town", top_n=10)
John is give out to town
随机删除
以概率p随机删除句子中的每个词语。
基本示例
>>> from textaugment import EDA
>>> t = EDA()
>>> t.random_deletion("John is going to town", p=0.2)
is going to town
随机交换
随机选择句子中的两个词语并交换它们的位置。重复此操作n次。
基本示例
>>> from textaugment import EDA
>>> t = EDA()
>>> t.random_swap("John is going to town")
John town going to is
随机插入
找到句子中非停用词的随机同义词。将这个同义词插入句子中的随机位置。重复此操作n次。
基本示例
>>> from textaugment import EDA
>>> t = EDA()
>>> t.random_insertion("John is going to town")
John is going to make up town
AEDA:文本分类的简单数据增强技术
这是Karimi等人实现的AEDA实现,是EDA的变体。它基于随机插入标点符号。
https://aclanthology.org/2021.findings-emnlp.234.pdf
实现
随机插入标点符号
基本示例
>>> from textaugment import AEDA
>>> t = AEDA()
>>> t.punct_insertion("John is going to town")
! John is going to town
Mixup增强
这是由Hongyi Zhang, Moustapha Cisse, Yann Dauphin, David Lopez-Paz实现的mixup增强,适用于NLP。
在Augmenting Data with Mixup for Sentence Classification: An Empirical Study中使用。
Mixup是一种通用且简单直接的数据增强原理。本质上,mixup通过训练神经网络对成对的示例及其标签的凸组合进行训练。通过这样做,mixup将神经网络正则化,以在训练示例之间偏好简单的线性行为。
实现
由❤在
作者
致谢
@inproceedings{marivate2020improving,
title={Improving short text classification through global augmentation methods},
author={Marivate, Vukosi and Sefara, Tshephisho},
booktitle={International Cross-Domain Conference for Machine Learning and Knowledge Extraction},
pages={385--399},
year={2020},
organization={Springer}
}
许可证
MIT许可。有关更多详细信息,请参阅捆绑的LICENCE文件。


下载文件
下载适用于您的平台的文件。如果您不确定选择哪一个,请了解更多关于安装包的信息。