合成数据生成器和评估器!


项目描述

synthcity
生成和评估合成表格数据的库。











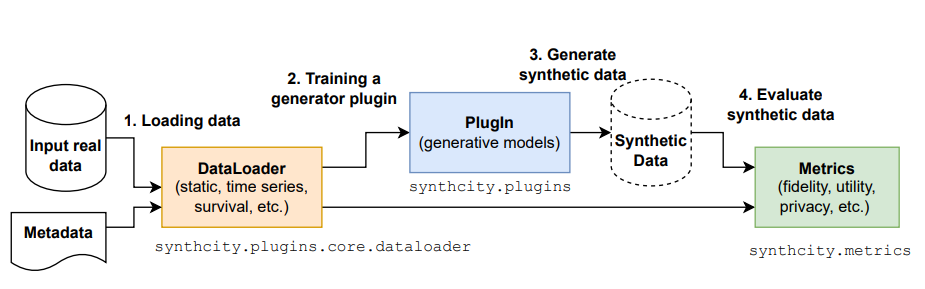
功能
- :key: 易于扩展的可插拔架构。
- :cyclone: 正确性和隐私的几个评估指标。
- :fire: 按类型划分的几个参考模型
- 通用:基于GAN(AdsGAN、CTGAN、PATEGAN、DP-GAN)、基于VAE(TVAE、RTVAE)、正态化流、贝叶斯网络(PrivBayes、BN)、随机森林(arfpy)、基于LLM(GReaT)。
- 时间序列和时间序列生存生成器:TimeGAN、FourierFlows、TimeVAE。
- 静态生存分析:SurvivalGAN、SurVAE。
- 关注隐私:DECAF、DP-GAN、AdsGAN、PATEGAN、PrivBayes。
- 域适应:RadialGAN。
- 图像:Image ConditionalGAN、Image AdsGAN。
- :book: 查看文档!
- :airplane: 查看教程!
请注意:synthcity不处理缺失数据,因此这些值必须首先填充。可以使用HyperImpute来完成此操作。
:rocket: 安装
可以使用以下命令从PyPI安装此库
$ pip install synthcity
或从源代码,使用
$ pip install .
其他库扩展
- 安装带有单元测试支持的库
pip install synthcity[testing]
- 安装带有GOGGLE支持的库
pip install synthcity[goggle]
- 安装带有所有扩展的库
pip install synthcity[all]
:boom: 示例用法
通用数据
- 列出可用的通用生成器
from synthcity.plugins import Plugins
Plugins(categories=["generic", "privacy"]).list()
- 加载并训练一个表格生成器
from sklearn.datasets import load_diabetes
from synthcity.plugins import Plugins
X, y = load_diabetes(return_X_y=True, as_frame=True)
X["target"] = y
syn_model = Plugins().get("adsgan")
syn_model.fit(X)
- 生成新的合成表格数据
syn_model.generate(count = 10)
- 基准测试插件质量
# third party
from sklearn.datasets import load_diabetes
# synthcity absolute
from synthcity.benchmark import Benchmarks
from synthcity.plugins.core.constraints import Constraints
from synthcity.plugins.core.dataloader import GenericDataLoader
X, y = load_diabetes(return_X_y=True, as_frame=True)
X["target"] = y
loader = GenericDataLoader(X, target_column="target", sensitive_columns=["sex"])
score = Benchmarks.evaluate(
[
(f"example_{model}", model, {}) # testname, plugin name, plugin args
for model in ["adsgan", "ctgan", "tvae"]
],
loader,
synthetic_size=1000,
metrics={"performance": ["linear_model"]},
repeats=3,
)
Benchmarks.print(score)
静态生存分析
- 列出针对生存分析的可用的生成器
from synthcity.plugins import Plugins
Plugins(categories=["generic", "privacy", "survival_analysis"]).list()
- 生成新数据
from lifelines.datasets import load_rossi
from synthcity.plugins.core.dataloader import SurvivalAnalysisDataLoader
from synthcity.plugins import Plugins
X = load_rossi()
data = SurvivalAnalysisDataLoader(
X,
target_column="arrest",
time_to_event_column="week",
)
syn_model = Plugins().get("survival_gan")
syn_model.fit(data)
syn_model.generate(count=10)
时间序列
- 列出可用的生成器
from synthcity.plugins import Plugins
Plugins(categories=["generic", "privacy", "time_series"]).list()
- 生成新数据
# synthcity absolute
from synthcity.plugins import Plugins
from synthcity.plugins.core.dataloader import TimeSeriesDataLoader
from synthcity.utils.datasets.time_series.google_stocks import GoogleStocksDataloader
static_data, temporal_data, horizons, outcome = GoogleStocksDataloader().load()
data = TimeSeriesDataLoader(
temporal_data=temporal_data,
observation_times=horizons,
static_data=static_data,
outcome=outcome,
)
syn_model = Plugins().get("timegan")
syn_model.fit(data)
syn_model.generate(count=10)
图像
注意:用于生成器的架构不是最先进的。对于其他架构,请考虑扩展convnet.py模块中的suggest_image_generator_discriminator_arch方法。
- 列出可用的生成器
from synthcity.plugins import Plugins
Plugins(categories=["images"]).list()
- 生成新数据
from synthcity.plugins import Plugins
from synthcity.plugins.core.dataloader import ImageDataLoader
from torchvision import datasets
dataset = datasets.MNIST(".", download=True)
loader = ImageDataLoader(dataset).sample(100)
syn_model = Plugins().get("image_cgan")
syn_model.fit(loader)
syn_img, syn_labels = syn_model.generate(count=10).unpack().numpy()
print(syn_img.shape)
序列化
- 使用保存/加载方法
from synthcity.utils.serialization import save, load
from synthcity.plugins import Plugins
syn_model = Plugins().get("adsgan")
buff = save(syn_model)
reloaded = load(buff)
assert syn_model.name() == reloaded.name()
- 从磁盘保存和加载模型
from sklearn.datasets import load_diabetes
from synthcity.utils.serialization import save_to_file, load_from_file
from synthcity.plugins import Plugins
X, y = load_diabetes(return_X_y=True, as_frame=True)
X["target"] = y
syn_model = Plugins().get("adsgan", n_iter=10)
syn_model.fit(X)
save_to_file('./adsgan_10_epochs.pkl', syn_model)
reloaded = load_from_file('./adsgan_10_epochs.pkl')
assert syn_model.name() == reloaded.name()
- 使用可序列化接口
from synthcity.plugins import Plugins
syn_model = Plugins().get("adsgan")
buff = syn_model.save()
reloaded = Plugins().load(buff)
assert syn_model.name() == reloaded.name()
📓 教程
🔑 方法
贝叶斯方法
| 方法 | 描述 | 参考文献 |
|---|---|---|
| bayesian_network | 该方法通过有向无环图(DAG)表示一组随机变量及其条件依赖性,并使用它来采样新的数据点 | pgmpy |
| privbayes | 一种用于发布高维数据的差分隐私方法。 | PrivBayes:通过贝叶斯网络进行私有数据发布 |
生成对抗网络(GANs)
| 方法 | 描述 | 参考文献 |
|---|---|---|
| adsgan | 一个条件GAN框架,在生成合成数据的同时最小化基于所有数据组合的患者可识别性,该可识别性基于给定任何单个患者的所有数据重新识别的概率 | 使用生成对抗网络(ADS-GAN)通过数据合成进行匿名化 |
| pategan | 该方法使用私有聚合的教师集成(PATE)框架,并将其应用于GANs,允许紧密绑定任何单个样本对模型的影响,从而实现紧密的差分隐私保证,因此比具有相同保证的模型性能更好。 | PATE-GAN:具有差分隐私保证的合成数据生成 |
| ctgan | 一个条件生成对抗网络,可以处理表格数据。 | 使用条件GAN对表格数据进行建模 |
Variational autoencoders(VAE)
| 方法 | 描述 | 参考文献 |
|---|---|---|
| tvae | 一个可以处理表格数据的条件VAE网络。 | 使用条件GAN对表格数据进行建模 |
| rtvae | 具有β散度的鲁棒变分自编码器(RTVAE),用于具有混合分类和连续特征的表格数据。 | 具有β散度的表格数据鲁棒变分自编码器 |
正态化流
| 方法 | 描述 | 参考文献 |
|---|---|---|
| nflow | 正态化流是生成模型,可以产生可处理的分布,其中采样和密度评估都可以高效且精确。 | 神经样条流 |
图神经网络
| 方法 | 描述 | 参考文献 |
|---|---|---|
| goggle | GOGGLE:通过学习关系结构对表格数据进行生成建模 | 论文 |
扩散模型
| 方法 | 描述 | 参考文献 |
|---|---|---|
| ddpm | TabDDPM:使用扩散模型对表格数据进行建模。 | 论文 |
随机森林模型
| 方法 | 描述 | 参考文献 |
|---|---|---|
| arfpy | 用于密度估计和生成建模的对抗性随机森林 | 论文 |
基于LLM的模型
| 方法 | 描述 | 参考文献 |
|---|---|---|
| GReaT | 语言模型是现实表格数据生成器 | 论文 |
静态生存分析方法
| 方法 | 描述 | 参考文献 |
|---|---|---|
| survival_gan | SurvivalGAN是一种生成模型,可以通过解决删失和时间段的不平衡,使用从输入和生存函数中近似时间到事件/删失的专用机制来处理生存数据。 | --- |
| survival_ctgan | 使用CTGAN的SurvivalGAN版本 | --- |
| survae | 使用VAE的SurvivalGAN版本 | --- |
| survival_nflow | 使用正态化流的SurvivalGAN版本 | --- |
时间序列和时间序列生存分析方法
| 方法 | 描述 | 参考文献 |
|---|---|---|
| timegan | TimeGAN是一种生成真实时间序列数据的框架,它结合了无监督范式的灵活性以及监督训练提供的控制。通过与监督和对抗目标共同学习的嵌入空间,网络在采样过程中遵循训练数据的动态。 | 时间序列生成对抗网络 |
| fflows | FFlows是一种基于新颖的正态化流类的显式似然模型,它将时间序列数据视为频域而不是时域。该方法使用离散傅里叶变换(DFT)将任意采样周期的可变长度时间序列转换为固定长度的频谱表示,然后对频率变换后的时间序列应用(数据相关的)频谱滤波器。 | 使用傅里叶流进行时间序列生成建模 |
隐私 & 公平
| 方法 | 描述 | 参考文献 |
|---|---|---|
| decaf | 机器学习模型因在训练数据中反映不公平的偏见而受到批评。DEACF并非直接通过引入公平学习算法来解决这个问题,而是专注于生成公平的合成数据,以确保任何下游学习者都是公平的。从不公平的数据中生成公平的合成数据——同时保持对底层数据生成过程(DGP)的真实性——并非易事。DECAF是一个基于GAN的表格数据公平合成数据生成器。使用DECAF,我们将DGP明确地嵌入到生成器的输入层中,作为结构化因果模型,允许每个变量根据其因果父变量进行重建。这一过程使得推理时间去偏成为可能,其中可以通过战略性地移除有偏的边来满足用户定义的公平性要求。 | DECAF:使用因果感知生成网络生成公平的合成数据 |
| privbayes | 一种用于发布高维数据的差分隐私方法。 | PrivBayes:通过贝叶斯网络进行私有数据发布 |
| dpgan | 差分隐私GAN | 差分隐私生成对抗网络 |
| adsgan | 一个条件GAN框架,在生成合成数据的同时最小化基于所有数据组合的患者可识别性,该可识别性基于给定任何单个患者的所有数据重新识别的概率 | 使用生成对抗网络(ADS-GAN)通过数据合成进行匿名化 |
| pategan | 该方法使用私有聚合的教师集成(PATE)框架,并将其应用于GANs,允许紧密绑定任何单个样本对模型的影响,从而实现紧密的差分隐私保证,因此比具有相同保证的模型性能更好。 | PATE-GAN:具有差分隐私保证的合成数据生成 |
领域自适应
| 方法 | 描述 | 参考文献 |
|---|---|---|
| radialgan | 训练用于预测的复杂机器学习模型通常需要大量数据,而这些数据并不总是容易获得。因此,利用来自相关但不同来源的外部数据集是一项基本任务,如果要在数据稀缺的环境中部署良好的预测模型,就必须这样做。RadialGAN是解决这个问题的一种方法,它使用多个GAN架构来学习从一个数据集转换到另一个数据集,从而有效地增强目标数据集,并学习比仅目标数据集更好的预测模型。 | RadialGAN:使用生成对抗网络利用多个数据集改进特定领域预测模型 |
图像
| 方法 | 描述 | 参考文献 |
|---|---|---|
| image_cgan | 用于生成图像的条件GAN | --- |
| image_adsgan | 适用于图像生成的AdsGAN方法 | --- |
调试方法
| 方法 | 描述 | 参考文献 |
|---|---|---|
| marginal_distributions | 一种从训练集边缘分布中采样的差分隐私方法 | --- |
| uniform_sampler | 一种从每列的[min, max]范围中均匀采样的差分隐私方法 | --- |
| dummy_sampler | 从训练集中重新采样数据点 | --- |
:zap: 评估指标
以下表格包含可用的评估指标
- 合理性检查
| 指标 | 描述 | 值 |
|---|---|---|
| data_mismatch | 真实数据与合成数据之间在数据类型(对象、实数、整数)不匹配的列的平均数 | 0:没有数据类型不匹配。 1:数据集之间完全数据类型不匹配。 |
| common_rows_proportion | 真实数据集中泄漏到合成数据集中的行比例 | 0:真实和合成数据集之间没有公共行。 1:真实数据集中的所有行都泄漏到合成数据集中。 |
| nearest_syn_neighbor_distance | 从真实数据到合成数据中最近邻的平均距离 | 0:所有真实行都泄漏到合成数据集中。 1:所有合成行都远离真实数据集。 |
| close_values_probability | 真实和合成数据之间相似值的概率 | 0:没有机会有合成行类似于真实。 1表示所有合成行都类似于某些真实行。 |
| distant_values_probability | 从真实数据到合成数据中最近邻的平均距离 | 0:没有机会在合成数据集中有行远离真实数据。 1:所有合成数据点都远离真实数据。 |
- 统计测试
| 指标 | 描述 | 值 |
|---|---|---|
| inverse_kl_divergence | Kullback–Leibler散度的平均倒数 | 0:数据集来自不同的分布。 1:数据集来自相同的分布。 |
| ks_test | Kolmogorov-Smirnov测试 | 0:分布完全不同。 1:分布完全相同。 |
| chi_squared_test | p值。较小的值表示我们可以拒绝零假设,并且分布是不同的。 | 0:分布不同 1:分布完全相同。 |
| max_mean_discrepancy | 经验最大均值差异。 | 0:分布相同。 1:分布完全不同。 |
| jensenshannon_dist | Jensen-Shannon距离(度量)是两个概率数组之间的距离。这是Jensen-Shannon散度的平方根。 | 0:分布相同。 1:分布完全不同。 |
| wasserstein_dist | Wasserstein距离是衡量两个概率分布之间距离的度量。 | 0:分布相同。 |
| prdc | 根据两个流形计算精度、召回率、密度和覆盖率。 | --- |
| alpha_precision | 评估alpha-精度、beta-召回率和真实性分数。 | --- |
| survival_km_distance | 两个Kaplan-Meier图(生存分析)之间的距离。 | --- |
| fid | Frechet Inception Distance(FID)计算两个图像分布之间的距离。 | --- |
- 合成数据质量
| 指标 | 描述 | 值 |
|---|---|---|
| performance.xgb | 在真实数据(gt)和合成数据(syn)上训练XGBoost分类器/回归器/生存模型,并在测试集上评估性能。 | 1表示理想性能,0表示最差性能 |
| performance.linear | 在真实数据(gt)和合成数据上训练线性分类器/回归器/生存模型,并在测试数据上评估性能。 | 1表示理想性能,0表示最差性能 |
| performance.mlp | 在真实数据和合成数据上训练神经网络分类器/回归器/生存模型,并在测试数据上评估性能。 | 1表示理想性能,0表示最差性能 |
| performance.feat_rank_distance | 在合成数据上训练一个模型,在真实数据上训练一个模型。计算模型在相同测试数据上的特征重要性,并计算重要性排名距离(kendalltau或spearman)。 | 1:特征重要性排名相似。0:特征重要性不相关 |
| detection_gmm | 训练一个高斯混合模型来区分合成数据和真实数据。 | 0:数据集不可区分。 1:数据集完全可区分。 |
| detection_xgb | 训练一个XGBoost模型来区分合成数据和真实数据。 | 0:数据集不可区分。 1:数据集完全可区分。 |
| detection_mlp | 训练一个神经网络来区分合成数据和真实数据。 | 0:数据集不可区分。 1:数据集完全可区分。 |
| detection_linear | 训练一个线性模型来区分合成数据和真实数据。 | 0:数据集不可区分。 1:数据集完全可区分。 |
- 隐私度量
准标识符:不是本身唯一标识符的信息片段,但与实体高度相关,可以与其他准标识符结合以创建唯一标识符。
| 指标 | 描述 | 值 |
|---|---|---|
| k_anonymization | 满足k-匿名性规则的最小值k:每个记录在可能标识变量上至少与其他k-1个记录相似。 | 在真实和合成数据上均进行报告。 |
| l_diversity | 满足l-多样性规则的最小值l:每个广义块必须至少包含l个不同的敏感值。 | 在真实和合成数据上均进行报告。 |
| kmap | 满足k-map规则的最小值k:准标识符的每个值组合在重新识别(合成)数据集中至少出现k次。 | 在真实和合成数据上均进行报告。 |
| delta_presence | 从合成数据集到真实数据集的最大重新识别风险。 | 0表示无风险。 |
| identifiability_score | 从合成数据集到真实数据集的重新识别分数。 | --- ] |
| sensitive_data_reidentification_xgb | 使用XGBoost从准标识符预测敏感数据。 | 0表示无风险。 |
| sensitive_data_reidentification_mlp | 使用神经网络从准标识符预测敏感数据。 | 0表示无风险。 |
:mag: 合成数据在保真度和隐私之外的用例
以下表格包含已完成的研究项目和论文,它们使用了Synthcity。请自由探索并从中获得灵感,以便在您自己的研究项目中使用Synthcity!
| 项目 | 描述 | 代码 | 论文 |
|---|---|---|---|
| 合成数据捕获真实数据的细微差别 | 确保合成数据反映现实世界数据的复杂细微差别是一项具有挑战性的任务。本文通过探索整合数据中心的AI技术,这些技术对数据进行配置以指导合成数据生成过程,来解决这个问题。 | 代码 | NeurIPS 2023论文 |
| 模型评估/测试 | 本文旨在通过合成测试数据改进模型评估。 | 代码 | NeurIPS 2023论文 |
| 生成不确定性 | 本文探讨了生成过程如何影响下游机器学习任务。 | 代码 | ICML 2023 论文 |
| 对 Synthcity 进行基准测试 | 本文采用 Synthcity 的基准测试管道来比较多个开放机器学习数据集上的不同 SOTA 方法。本文旨在向更广泛的机器学习社区介绍 Synthcity。 | 代码 | NeurIPS 2023论文 |
:hammer: 测试
使用以下命令安装测试依赖项
pip install .[testing]
可以使用以下命令执行测试
pytest -vsx
为 Synthcity 做贡献
我们希望使为 Synthcity 做贡献尽可能简单和透明。我们希望与尽可能多的人合作。
开发安装
首先创建一个新环境。建议您使用 conda。这可以通过以下步骤完成
conda create -n your-synthcity-env python=3.9
conda activate your-synthcity-env
Python 版本 3.7、3.8、3.9 和 3.10 都是兼容的,但最好使用您能获得的最新版本,因为某些模型可能不支持较旧的 Python 版本。
要获取带有所有必要依赖项的开发安装,包括代码检查、测试、自动格式化和 pre-commit 等,请运行以下命令
git clone https://github.com/vanderschaarlab/synthcity.git
cd synthcity
pip install -e .[testing]
请检查是否已正确安装了存储库的 pre-commit,通过运行以下命令
pre-commit run --all
这确保您已正确设置以进行贡献,这样您将匹配项目中其余部分的代码风格。这将在下文进行更详细的说明。
我们的开发流程
代码风格
我们相信保持一致的代码风格至关重要。因此,Synthcity 对贡献的代码施加某些规则,如果不符合这些规则,自动化测试将不会通过。贡献被合并的要求之一就是通过这些测试。然而,我们将遵守这种代码风格的方式尽可能简化。首先,在设置开发环境时,在上述步骤中安装了所有必需的库,以生成与 Synthcity 代码风格兼容的代码。其次,这些库都由 pre-commit 触发,所以一旦设置完成,您就无需做任何事情。当您运行 git commit 时,任何强制执行风格的简单更改将自动运行,其他必需的更改将在 stdout 中为您说明,以便您进行检查和修复。
Synthcity 使用 black 和 flake8 代码格式化器来强制在代码库中实施统一的代码风格。无需额外配置(有关高级用法,请参阅 black 文档)。
此外,Synthcity 使用 isort 对导入进行字母排序并分开成部分。
类型提示
Synthcity 完全使用 python 3.7+ 类型提示。这通过静态类型检查器 mypy 来强制执行,它适用于贡献。
测试
要运行测试,您可以使用 pytest(再次,与测试额外一起安装)。以下测试命令非常适合检查您的代码,因为它跳过了运行时间较长的测试。
pytest -vvvsx -m "not slow" --durations=50
但是,可以使用以下命令运行完整的测试套件。
pytest -vvvs --durations=50
某些插件可能包含在库中作为额外内容,这些插件的相关测试需要单独运行,例如,可以使用以下命令测试 goggle 插件
pytest -vvvs -k goggle --durations=50
拉取请求
我们积极欢迎您的拉取请求。
- 从
main分支分叉存储库并创建您的分支。 - 如果您添加了应进行测试的代码,请以与存储库中已有的相同风格添加测试。
- 如果您更改了 API,请在 PR 中记录 API 变更。
- 确保测试套件通过。
- 确保您的代码通过 pre-commit,这是提交和推送所必需的,如果您已正确安装 pre-commit,它包含在测试额外内容中。
问题
我们使用 GitHub 问题跟踪公共错误。请确保您的描述清晰,并且有足够的说明,以便能够重现问题。
许可证
通过向Synthcity贡献,您同意您的贡献将按照此源代码树的根目录中的LICENSE文件进行许可。因此,您应确保,如果您引入了任何依赖项,它们也应受一个许可证的保护,该许可证允许代码被项目使用,并且与本项目根目录中的许可证兼容。
引用
如果您使用此代码,请引用相关的论文
@misc{https://doi.org/10.48550/arxiv.2301.07573,
doi = {10.48550/ARXIV.2301.07573},
url = {https://arxiv.org/abs/2301.07573},
author = {Qian, Zhaozhi and Cebere, Bogdan-Constantin and van der Schaar, Mihaela},
keywords = {Machine Learning (cs.LG), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Synthcity: facilitating innovative use cases of synthetic data in different data modalities},
year = {2023},
copyright = {Creative Commons Attribution 4.0 International}
}


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源代码分发
构建分发
散列 for synthcity-0.2.11-py3-none-macosx_10_14_x86_64.whl
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 254cd3cdd42accbbd5473a2d5613419d323aed75b198ada9b8c185d45c765c9d |
|
| MD5 | d4fa9267ac5ee07c44227c40d97de1f1 |
|
| BLAKE2b-256 | 9c70dbd827e38bda93916068907d03f6289274d631966123b74b5fcd4fde9fad |







