使用streamlit可视化spaCy


项目描述

spacy-streamlit: spaCy构建块,用于Streamlit应用程序
此软件包包含用于可视化spaCy模型和构建交互式spaCy应用程序的实用程序。它包括各种构建块,您可以在自己的Streamlit应用程序中使用,例如用于视觉化的构建块,如句法依存关系、命名实体、文本分类、通过词向量进行的语义相似性、标记属性等。


🚀 快速入门
您可以从pip安装spacy-streamlit
pip install spacy-streamlit
该软件包包括调用Streamlit并为您设置所有必需元素的构建块。您可以直接使用单个组件并将它们与您的应用程序中的其他元素结合,或者调用visualize函数来嵌入整个可视化器。
下载spaCy的英文模型以开始。
python -m spacy download en_core_web_sm
然后将以下示例代码放入文件中。
# streamlit_app.py
import spacy_streamlit
models = ["en_core_web_sm", "en_core_web_md"]
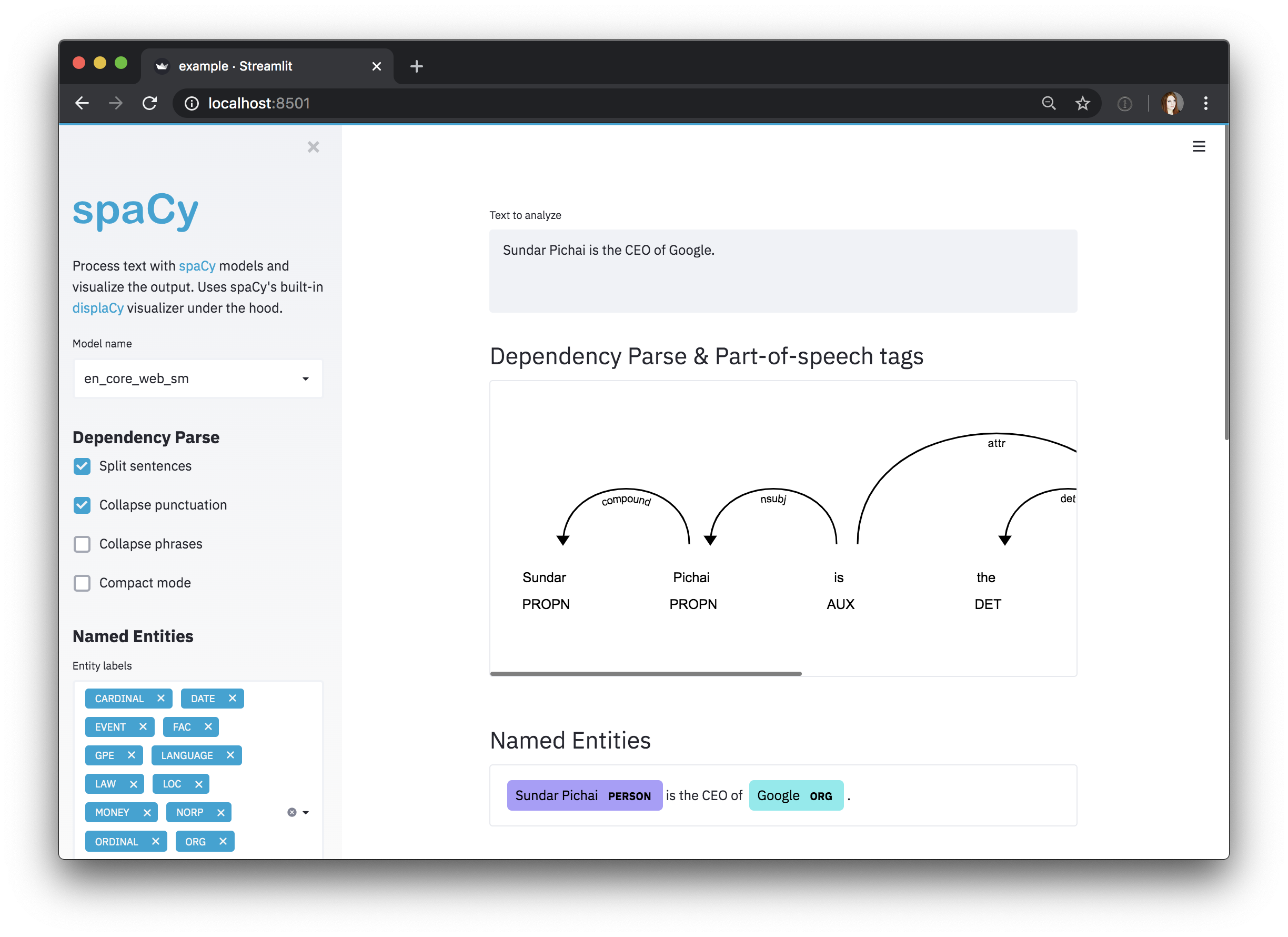
default_text = "Sundar Pichai is the CEO of Google."
spacy_streamlit.visualize(models, default_text)
您可以使用streamlit run streamlit_app.py运行您的应用程序。应用程序应在您的网页浏览器中弹出。😀
📦 示例: 01_out-of-the-box.py
使用内置的可视化器,带有自定义设置。
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/01_out-of-the-box.py
👑 示例: 02_custom.py
在您的现有应用程序中使用单个组件。
streamlit run https://raw.githubusercontent.com/explosion/spacy-streamlit/master/examples/02_custom.py
🎛 API
可视化器组件
这些函数可以在您的Streamlit应用程序中使用。它们在底层调用streamlit并设置所需元素。
函数 visualize
嵌入带有选定组件的全视觉器。
import spacy_streamlit
models = ["en_core_web_sm", "/path/to/model"]
default_text = "Sundar Pichai is the CEO of Google."
visualizers = ["ner", "textcat"]
spacy_streamlit.visualize(models, default_text, visualizers)
| 参数 | 类型 | 描述 |
|---|---|---|
models |
List[str] / Dict[str, str] | 可加载的spaCy模型的名称(路径或包名)。这些模型可通过下拉菜单进行选择。可以是名称列表,也可以是名称映射到显示在下拉菜单中的描述。 |
default_text |
str | 加载时要分析的默认文本。默认为""。 |
default_model |
Optional[str] | 可选的默认模型名称。如果未设置,则使用models列表中的第一个模型。 |
visualizers |
List[str] | 要显示的视觉器名称。默认为["parser", "ner", "textcat", "similarity", "tokens"]。 |
ner_labels |
Optional[List[str]] | 要包含的NER标签。如果未设置,则使用"ner"管道组件中存在的所有标签。 |
ner_attrs |
List[str] | 在命名实体表中显示的命名实体属性。请参阅visualizer.py以获取默认值。 |
token_attrs |
List[str] | 在标记视觉器中显示的标记属性。请参阅visualizer.py以获取默认值。 |
similarity_texts |
Tuple[str, str] | 在相似性视觉器中比较的默认文本。默认为("apple", "orange")。 |
show_json_doc |
bool | 显示按钮以切换Doc的JSON表示。默认为True。 |
show_meta |
bool | 显示按钮以切换当前管道的meta.json。默认为True。 |
show_config |
bool | 显示按钮以切换当前管道的config.cfg。默认为True。 |
show_visualizer_select |
bool | 显示侧边栏下拉菜单以选择要显示的视觉器(基于启用的视觉器)。默认为False。 |
sidebar_title |
Optional[str] | 侧边栏中显示的标题。默认为None。 |
sidebar_description |
Optional[str] | 侧边栏中显示的描述。接受Markdown格式化文本。 |
show_logo |
bool | 在侧边栏中显示spaCy标志。默认为True。 |
color |
Optional[str] | 实验性:用于某些主要UI元素的基色(None以禁用hack)。默认为"#09A3D5"。 |
get_default_text |
Callable[[Language], str] | 可选的可调用对象,它接受当前加载的nlp对象并返回默认文本。可用于提供特定语言的默认文本。如果函数返回None,则使用(如果可用)default_text的值。默认为None。 |
函数 visualize_parser
使用spaCy的displacy visualizer可视化依赖解析和词性标签。
import spacy
from spacy_streamlit import visualize_parser
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a text")
visualize_parser(doc)
| 参数 | 类型 | 描述 |
|---|---|---|
doc |
Doc |
要可视化的spaCy Doc对象。 |
| keyword-only | ||
title |
Optional[str] | 视觉器块的标题。 |
key |
Optional[str] | 用于流式传输组件选择标签的键。 |
manual |
bool | 标志,表示doc参数是Doc对象还是包含解析信息的Dict列表。 |
displacy_optoins |
Optional[Dict] | 要传递给displacy渲染方法的选项字典,用于生成要渲染的HTML。请参阅:[https://spacy.io/api/top-level#options-dep](https://spacy.io/api/top-level#options-dep) |
函数 visualize_ner
使用spaCy的displacy visualizer在Doc中可视化命名实体。
import spacy
from spacy_streamlit import visualize_ner
nlp = spacy.load("en_core_web_sm")
doc = nlp("Sundar Pichai is the CEO of Google.")
visualize_ner(doc, labels=nlp.get_pipe("ner").labels)
| 参数 | 类型 | 描述 |
|---|---|---|
doc |
Doc |
要可视化的spaCy Doc对象。 |
| keyword-only | ||
labels |
Sequence[str] | 在标签下拉菜单中显示的标签。 |
attrs |
List[str] | 在实体表中显示的span属性。 |
show_table |
bool | 是否显示实体及其属性的表格。默认为 True。 |
title |
Optional[str] | 视觉器块的标题。 |
颜色 |
Dict[str,str] | 用于可视化的实体跨度颜色字典,键为标签,对应的颜色为值。此参数将很快被弃用。在将来,需要将颜色参数传递给带有“colors”键的 displacy_options 参数。 |
key |
Optional[str] | 用于流式传输组件选择标签的键。 |
manual |
bool | 标志,表示 doc 参数是 Doc 对象还是包含实体跨度信息的 Dicts 列表。 |
| 信息。 | ||
displacy_options |
Optional[Dict] | 传递给 displacy 渲染方法以生成要渲染的 HTML 的选项字典。请参阅 https://spacy.io/api/top-level#displacy_options-ent。 |
函数 visualize_spans
使用 spaCy 的 displacy 可视化器 在 Doc 中可视化跨度。
import spacy
from spacy_streamlit import visualize_spans
nlp = spacy.load("en_core_web_sm")
doc = nlp("Sundar Pichai is the CEO of Google.")
span = doc[4:7] # CEO of Google
span.label_ = "CEO"
doc.spans["job_role"] = [span]
visualize_spans(doc, spans_key="job_role", displacy_options={"colors": {"CEO": "#09a3d5"}})
| 参数 | 类型 | 描述 |
|---|---|---|
doc |
Doc |
要可视化的spaCy Doc对象。 |
| keyword-only | ||
spans_key |
Sequence[str] | 从哪个跨度键渲染跨度。默认为 "sc"。 |
attrs |
List[str] | 要标记的实体跨度属性。仅当 show_table 参数为 True 时显示属性。 |
show_table |
bool | 是否显示跨度及其属性的表格。默认为 True。 |
title |
Optional[str] | 视觉器块的标题。 |
manual |
bool | 标志,表示 doc 参数是 Doc 对象还是包含实体跨度信息的 Dicts 列表。 |
displacy_options |
Optional[Dict] | 传递给 displacy 渲染方法以生成要渲染的 HTML 的选项字典。请参阅 https://spacy.io/api/top-level#displacy_options-span。 |
函数 visualize_textcat
可视化由训练文本分类器预测的文本类别。
import spacy
from spacy_streamlit import visualize_textcat
nlp = spacy.load("./my_textcat_model")
doc = nlp("This is a text about a topic")
visualize_textcat(doc)
| 参数 | 类型 | 描述 |
|---|---|---|
doc |
Doc |
要可视化的spaCy Doc对象。 |
| keyword-only | ||
title |
Optional[str] | 视觉器块的标题。 |
visualize_similarity
使用模型词向量可视化语义相似度。如果没有模型中存在向量,将显示警告。
import spacy
from spacy_streamlit import visualize_similarity
nlp = spacy.load("en_core_web_lg")
visualize_similarity(nlp, ("pizza", "fries"))
| 参数 | 类型 | 描述 |
|---|---|---|
nlp |
语言 |
包含向量的加载 nlp 对象。 |
default_texts |
Tuple[str, str] | 加载时要比较的默认文本。默认为 ("apple", "orange")。 |
| keyword-only | ||
threshold |
float | 判断“相似”的阈值。如果相似度得分大于阈值,则显示结果为相似。默认为 0.5。 |
title |
Optional[str] | 视觉器块的标题。 |
函数 visualize_tokens
可视化 Doc 中的标记及其属性。
import spacy
from spacy_streamlit import visualize_tokens
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a text")
visualize_tokens(doc, attrs=["text", "pos_", "dep_", "ent_type_"])
| 参数 | 类型 | 描述 |
|---|---|---|
doc |
Doc |
要可视化的spaCy Doc对象。 |
| keyword-only | ||
attrs |
List[str] | 要使用的标记属性名称。请参阅 visualizer.py 以获取默认值。 |
title |
Optional[str] | 视觉器块的标题。 |
缓存助手
这些助手尝试缓存加载的模型和创建的 Doc 对象。
函数 process_text
使用给定名称的模型处理文本并创建 Doc 对象。调用 load_model 助手来加载模型。
import streamlit as st
from spacy_streamlit import process_text
spacy_model = st.sidebar.selectbox("Model name", ["en_core_web_sm", "en_core_web_md"])
text = st.text_area("Text to analyze", "This is a text")
doc = process_text(spacy_model, text)
| 参数 | 类型 | 描述 |
|---|---|---|
model_name |
str | 可加载的 spaCy 模型名称。可以是路径或包名称。 |
text |
str | 要处理的文本。 |
| 返回 | Doc |
处理后的文档。 |
函数 load_model
从路径或已安装的包加载 spaCy 模型并返回加载的 nlp 对象。
import streamlit as st
from spacy_streamlit import load_model
spacy_model = st.sidebar.selectbox("Model name", ["en_core_web_sm", "en_core_web_md"])
nlp = load_model(spacy_model)
| 参数 | 类型 | 描述 |
|---|---|---|
name |
str | 可加载的 spaCy 模型名称。可以是路径或包名称。 |
| 返回 | 语言 |
加载的 nlp 对象。 |


下载文件
下载适合您平台文件的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。
源代码分发
构建分发
spacy_streamlit-1.0.6.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 4a54df591f5d4c031e3af3540f58a84c79be741e2583beb21b9d1bd654790750 |
|
| MD5 | ccfebd9ada8c12e875e48733d56f709f |
|
| BLAKE2b-256 | 789172a4817b31db40b5346d3246464743b6e7bbe2ea75f4693a6affd3c11166 |
spacy_streamlit-1.0.6-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 00b829b25b349eec5cd012274b233ee8909301af7fdc9c128c9affd877bcb7b6 |
|
| MD5 | 16a487c03ebebed3321fdf97bed46674 |
|
| BLAKE2b-256 | 288bf762777bcfffd47a757c0684424ef390849df5f72c9325ad3458ea47cf59 |