强大的Python调试工具

项目描述
snoop


snoop是一套强大的Python调试工具。它主要是作为 更丰富、更精致的 PySnooper 版本。它还包括自己的 icecream 版本和一些其他实用功能。
您正在试图找出为什么您的Python代码没有按照您的预期运行。您很希望使用一个带有断点和监视器的完整调试器,但现在您不想费心去设置。
您想知道哪些行正在运行,哪些没有运行,以及局部变量的值。
大多数人会使用在战略位置的 print 行,其中一些会显示变量的值。
snoop 允许您做到这一点,但与精心构建正确的 print 行不同,您只需在您感兴趣的功能中添加一行装饰器即可。您将获得您功能的逐字记录,包括哪些行在何时运行,以及局部变量何时被更改。
安装就像 pip install snoop 一样简单。
您可以在 futurecoder 上立即尝试:在左侧的编辑器中输入您的代码,然后点击 snoop 按钮。无需导入或装饰器。
基本snoop用法
我们正在编写一个将数字转换为二进制的函数,通过返回一个位列表。让我们通过添加 @snoop 装饰器来窥探它。
import snoop
@snoop
def number_to_bits(number):
if number:
bits = []
while number:
number, remainder = divmod(number, 2)
bits.insert(0, remainder)
return bits
else:
return [0]
number_to_bits(6)
注意这有多简单:只需 import snoop 和 @snoop。如果你不喜欢这种魔术导入,snoop.snoop 和 from snoop import snoop 仍然可以工作。或者,如果你根本不想在你的项目中导入,只需在某个地方调用一次 install() 即可。
错误输出看起来像这样
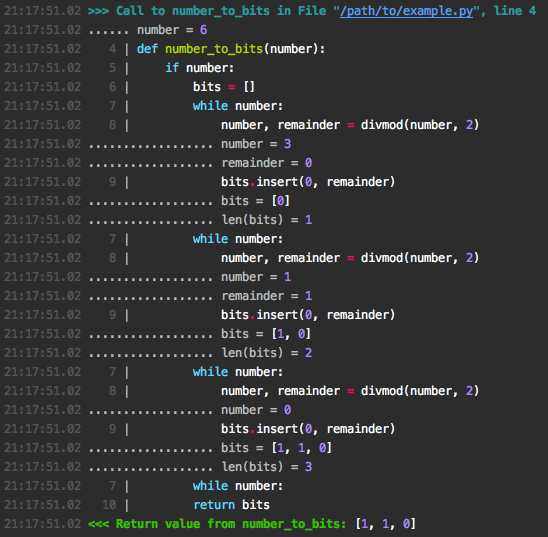
让我们尝试一个更复杂的例子。我们正在编写一个记忆化装饰器:它将函数参数和返回值存储在缓存中,以避免重新计算。
import snoop
def cache(func):
d = {}
def wrapper(*args):
try:
return d[args]
except KeyError:
result = d[args] = func(*args)
return result
return wrapper
@snoop(depth=2)
@cache
def add(x, y):
return x + y
add(1, 2)
add(1, 2)
这里我们指定 depth=2 表示我们应深入一步到内部函数调用。然后我们调用该函数两次,以查看缓存的效果。这里是输出
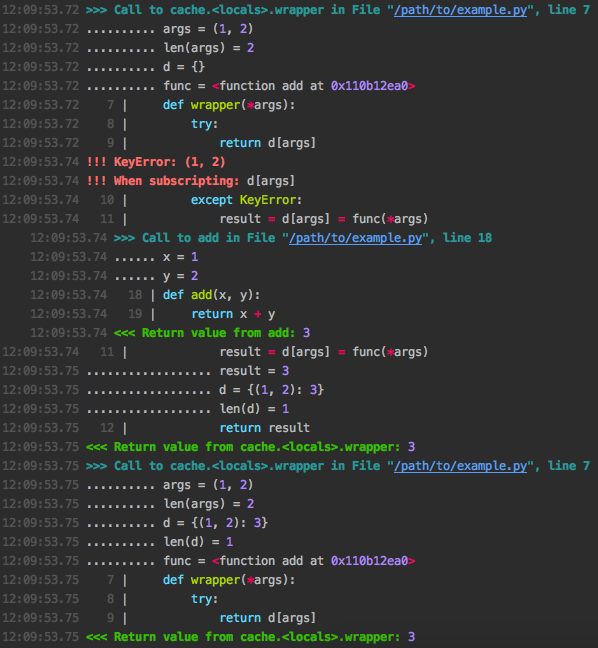
从直观上看,我们可以看到第一次调用时缓存查找失败并出现 KeyError,因此调用了原始的 add 函数,而在第二次调用时立即返回了之前缓存的值。
如果您不希望跟踪整个函数,可以将相关部分包装在一个 with 块中
import snoop
import random
def foo():
lst = []
for i in range(10):
lst.append(random.randrange(1, 1000))
with snoop:
lower = min(lst)
upper = max(lst)
mid = (lower + upper) / 2
return lower, mid, upper
foo()
输出如下
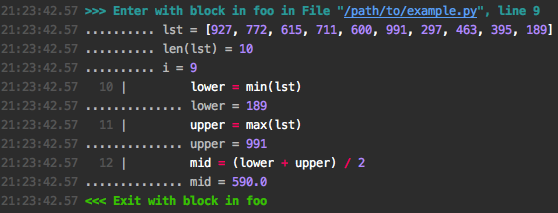
常用参数
depth:如上所示,snoops 更深层调用的函数/块。默认值为 1,表示没有内部调用,因此请传递更大的值。watch:通过指定字符串显示任意表达式的值,例如
@snoop(watch=('foo.bar', 'self.x["whatever"]'))
watch_explode:展开变量或表达式,以查看所有属性或列表/字典的项
@snoop(watch_explode=['foo', 'self'])
这将输出类似以下内容的行
........ foo[2] = 'whatever'
........ self.baz = 8
有关此参数的更高级用法,请参阅 控制 watch_explode。
要显示任何值(局部变量、监视表达式或展开项)的附加信息,请参阅 watch_extras。
pp - 精美的打印调试
尽管 snoop 的目的是让您免于编写 print 调用,但有时这正是您需要的事情。pp 力求成为这种功能的最佳版本。它可以单独使用,也可以与 snoop 结合使用。
pp(x) 将输出 x = <pp(x) 的漂亮打印值>,即它将显示其参数的源代码,以便您知道正在打印的内容,并使用 pprint.pformat 格式化值,以便您可以轻松地查看复杂数据结构的布局。如果已安装 prettyprinter 或 pprintpp,则将使用它们的 pformat 而不是 pprint.pformat。
pp 将直接返回其参数,这样您就可以轻松地将其插入代码中而无需重新排列。如果提供了多个参数,它将返回一个元组,因此您可以将 foo(x, y) 替换为 foo(*pp(x, y)) 以保持代码的行为不变。
以下是一个示例
from snoop import pp
x = 1
y = 2
pp(pp(x + 1) + max(*pp(y + 2, y + 3)))
输出
12:34:56.78 LOG:
12:34:56.78 .... x + 1 = 2
12:34:56.78 LOG:
12:34:56.78 .... y + 2 = 4
12:34:56.78 .... y + 3 = 5
12:34:56.78 LOG:
12:34:56.78 .... pp(x + 1) + max(*pp(y + 2, y + 3)) = 7
如果您已经 import snoop,您还可以使用 snoop.pp。但理想情况下,您应该使用 install() 以避免导入。
在以下几种情况下,pp 无法找到其参数的源代码,在这种情况下,它将显示一个占位符
- 当无法找到源文件时,通常是因为它不存在,例如,如果您在 Python shell 中。源代码从
linecache中获取。 - 在 Python 3.4 和 PyPy 中。
- 在底层存在魔法,可以转换源代码,例如
pytest或birdseye(因此还有@spy装饰器)。 - 当在第一次调用
pp或snoop之前已经修改了源文件。
在底层,pp 使用库 executing 来定位函数调用的 AST 节点——如果您想编写一些自己的酷炫工具,可以查看它。
pp 受 icecream 的启发,提供了相同的打印基本 API,但 pp 与 snoop 集成无缝,并提供了独特的 pp.deep。
pp 代表 'pretty-print',绝对肯定没有任何其他含义。它也非常容易和快速输入。
pp.deep 用于跟踪子表达式
如果您有 pp(<complicated expression>) 并想看到该表达式内部发生了什么,而不仅仅是最终值,请将其替换为 pp.deep(lambda: <complicated expression>)。这将记录每个中间子表达式,以正确的顺序,没有额外的副作用,并返回最终值。重复之前的示例
pp.deep(lambda: x + 1 + max(y + 2, y + 3))
输出
12:34:56.78 LOG:
12:34:56.78 ............ x = 1
12:34:56.78 ........ x + 1 = 2
12:34:56.78 ................ y = 2
12:34:56.78 ............ y + 2 = 4
12:34:56.78 ................ y = 2
12:34:56.78 ............ y + 3 = 5
12:34:56.78 ........ max(y + 2, y + 3) = 5
12:34:56.78 .... x + 1 + max(y + 2, y + 3) = 7
(字面量和内置函数的值被省略,因为它们是微不足道的)
如果抛出异常,它会显示哪个子表达式负责,看起来像这样
12:34:56.78 ................ y = 2
12:34:56.78 ............ y + 3 = 5
12:34:56.78 ........ (y + 3) / 0 = !!! ZeroDivisionError!
12:34:56.78 !!! ZeroDivisionError: division by zero
如果您喜欢这个,您可能也会喜欢 @spy。
@spy
@spy 装饰器允许您将 @snoop 与强大的调试器 birdseye 结合使用。代码
from snoop import spy # not required if you use install()
@spy
def foo():
大致相当于
import snoop
from birdseye import eye
@snoop
@eye
def foo():
为了减少 snoop 的依赖,您需要单独安装 birdseye:pip install birdseye。
@spy 的唯一大缺点是它会显著降低性能,所以对于有多个循环迭代的函数应避免使用。否则,您基本上总是可以使用它来代替 @snoop。然后,如果您需要的日志中没有所需的信息,您可以在不修改或重新运行代码的情况下打开 birdseye UI 来查看更多细节。非常适合您感到懒惰且不确定哪个工具最好的时候。
spy 将其参数传递给 snoop,因此例如 @spy(depth=2, watch='x.y') 是有效的。
(spy 被这样命名是因为它是装饰器名称 'snoop' 和 'eye' 的组合)
install()
为了使定期调试您的项目更加方便,请尽早运行此代码
import snoop
snoop.install()
然后 snoop、pp 和 spy 将在每个文件中可用,无需导入。
您可以通过传递关键字参数 <original name>=<new name> 选择不同的名称,例如
snoop.install(snoop="ss")
将允许您使用 @ss 装饰函数。
如果您不喜欢这个功能,并希望正常导入,但您想使用 install() 进行其他配置,请传递 builtins=False。
作为替代方案,在 Python 3.7+ 中,如果您设置环境变量 PYTHONBREAKPOINT=snoop.snoop,您可以使用新的 breakpoint 函数来代替 snoop。
禁用
如果您想在代码库中留下 snoop 和其他函数,但禁用它们的效果,请传递 enabled=False。例如,如果您正在使用 Django,请将 snoop.install(enabled=DEBUG) 放入 settings.py 以在生产环境中自动禁用它。当禁用时,性能影响最小化,且任何地方都没有输出。
您还可以通过再次调用 snoop.install(enabled=True) 在任何位置动态重新启用函数,例如在特殊的视图或信号处理程序中。
输出配置
install 有几个关键字参数用于控制 snoop 和 pp 的输出
-
out:确定输出目标。默认情况下这是 stderr。您也可以传递- 一个字符串或一个
Path对象,以将文件写入该位置。默认情况下,它始终会附加到文件中。传递overwrite=True以初始化时清除文件。 - 任何具有
write方法的对象,例如sys.stdout或文件对象。 - 任何只有一个字符串参数的可调用对象,例如
logger.info。
- 一个字符串或一个
-
color:确定输出是否包含用于在控制台显示彩色文本的转义字符。如果您在输出中看到奇怪的字符,则您的控制台不支持颜色,因此请传递color=False。 -
prefix:传递一个字符串以在所有 snoop 行前加上该字符串,这样您就可以轻松地使用 grep 查找它们。 -
columns:这指定了每行输出的起始列。您可以传递一个字符串,其中包含以空格或逗号分隔的内置列名。这些是可用的列time:当前时间。这是默认的唯一列。thread:当前线程的名称。thread_ident:当前线程的 标识符,以防线程名称不唯一。file:当前函数的文件名(不是完整路径)。full_file:文件的完整路径(当调用函数时也会显示)。function:当前函数的名称。function_qualname:当前函数的限定名称。
-
watch_extras和replace_watch_extras:在 高级用法 中了解这些。如果您想要自定义列,请提出一个问题,告诉我您感兴趣的内容!同时,您可以通过传递一个列表来传递,其中元素是字符串或可调用对象。可调用对象应接受一个参数,该参数将是一个
Event对象。它具有在sys.settrace()中指定的frame、event和arg属性,以及其他可能更改的属性。 -
pformat:设置pp使用的格式化函数。默认情况下,使用可以导入的第一个prettyprinter.pformat、pprintpp.pformat和pprint.pformat。
与 PySnooper 的 API 差异
如果您熟悉 PySnooper 并想使用 snoop,您应该注意一些不同之处
- 将
prefix和overwrite传递给install(),而不是snoop()。 pysnooper.snoop的第一个参数(称为output)应使用关键字out传递给install。- 而不是写
snoop(thread_info=True),写install(columns='time thread thread_ident')。 - 而不是使用环境变量
PYSNOOPER_DISABLED,使用install(enabled=False)。 - 而不是使用
custom_repr,请参阅watch_extras和 自定义变量显示。
如果您不确定是否使用 snoop 而不是 PySnooper 值得,请在此处阅读比较。
IPython/Jupyter 集成
snoop 附带一个 IPython 扩展,您可以在外壳或笔记本中使用它。
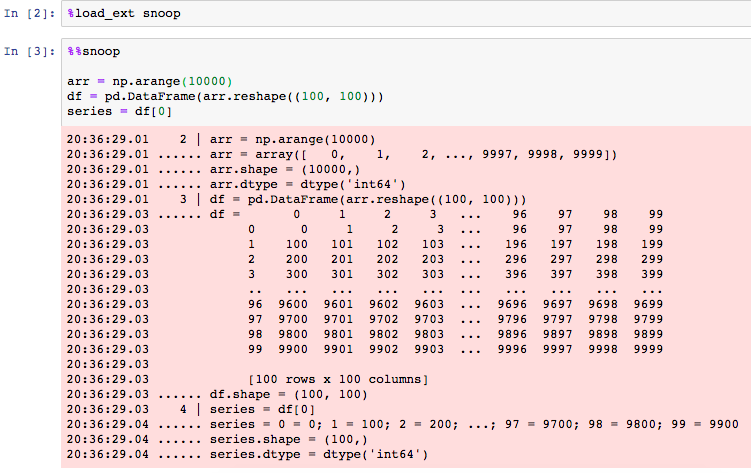
首先您需要 加载扩展,在笔记本单元中,使用 %load_ext snoop 或通过在您的 IPython 配置文件中将 'snoop' 添加到 c.InteractiveShellApp.extensions 列表来加载,例如 ~/.ipython/profile_default/ipython_config.py。
然后使用笔记本单元顶部的单元格魔法 %%snoop 来跟踪该单元。
高级用法
watch_extras
install还有一个名为watch_extras的参数。你可以传递一个函数列表,以便自动显示任何值的额外信息:局部变量、监视的表达式和展开的项目。例如,假设你想要查看每个变量的类型。你可以定义一个像这样的函数
def type_watch(source, value):
return 'type({})'.format(source), type(value)
然后你可以这样写install(watch_extras=[type_watch])。结果输出如下
12:34:56.78 9 | x = 1
12:34:56.78 .......... type(x) = <class 'int'>
12:34:56.78 10 | y = [x]
12:34:56.78 .......... y = [1]
12:34:56.78 .......... type(y) = <class 'list'>
你编写的函数应该接受两个参数source和value - 通常这些将是变量的名称和其实际值。它们应该返回一个表示返回信息“来源”的元组(仅用于显示,不必是有效的Python),以及实际信息。如果你不想为这个特定的值显示任何内容,返回None。任何抛出的异常都将被捕获并静默处理。
已经有两个这样的函数默认启用:一个显示值的len()或.shape属性(由numpy、pandas、tensorflow等使用),另一个显示.dtype属性。
watch_extras添加到这两个默认函数中,这样你就不需要再次指定它们。如果你不想包含它们,请使用replace_watch_extras来指定确切的列表。原始函数可以在以下位置找到
from snoop.configuration import len_shape_watch, dtype_watch
控制watch_explode
watch_explode将根据其类自动猜测如何展开传递给它的表达式。你可以使用以下类中的任何一个来更加具体
@snoop(watch=(
snoop.Attrs('x'), # Attributes (specifically from __dict__ or __slots__)
snoop.Keys('y'), # Mapping (e.g. dict) items, based on .keys()
snoop.Indices('z'), # Sequence (e.g. list/tuple) items, based on len()
))
使用exclude参数排除特定的键/属性/索引,例如Attrs('x', exclude=('_foo', '_bar'))。
在Indices后添加一个切片,以仅查看该切片内的值,例如Indices('z')[-3:]。
自定义变量显示
(也参见watch_extras)
使用cheap_repr库来渲染值以提高性能并避免控制台溢出。它为大多数常见类定义了特别定义的repr函数,包括来自第三方库的类。如果缺少某个类,请在该处提交一个issue。你还可以为类注册自己的repr。以下是一个示例
from cheap_repr import register_repr, cheap_repr
@register_repr(MyClass)
def repr_my_class(x, helper):
return '{}(items={})'.format(
x.__class__.__name__,
cheap_repr(x.items, helper.level - 1),
)
更多信息请参阅这里。
你也可以增加单个类的详细程度(参见文档),例如
from cheap_repr import find_repr_function
find_repr_function(list).maxparts = 100
多个独立配置
如果你比全局的install函数有更多的控制需求,例如,如果你想在单个进程中将数据写入几个不同的文件,你可以创建一个Config对象,例如:config = snoop.Config(out=filename)。然后config.snoop、config.pp和config.spy将使用该配置而不是全局配置。
参数与install()的参数相同,与输出配置和enabled相关。
贡献
反馈和讨论
我很乐意听取用户的声音!显然,如果你有,请提交一个issue,但也可以查看带有“讨论”标签的问题。还有更多的工作要做,我非常希望听到人们的意见,以便我能够正确地完成它。
你还可以通过电子邮件告诉我你对snoop的看法或不喜欢的内容。仅仅知道它在被使用就很有帮助。
开发
拉取请求总是受欢迎的!
请,编写测试并使用Tox运行它们。
Tox会自动安装所有依赖项。你只需要安装Tox本身。
$ pip install tox
如果你想要针对所有目标Python版本运行测试,请使用pyenv来安装它们。否则,你只能运行你在机器上已经安装的测试。
# run only some interpreters
$ tox -e py27,py36
或者直接以开发者模式安装项目并包含测试依赖项
$ pip install -e path/to/snoop[tests]
然后运行测试
$ pytest


下载文件
下载适用于您平台的应用程序文件。如果您不确定选择哪一个,请了解有关安装包的更多信息。
源分布
构建分布
snoop-0.4.3.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 2e0930bb19ff0dbdaa6f5933f88e89ed5984210ea9f9de0e1d8231fa5c1c1f25 |
|
| MD5 | ee293774e503db4583229bf96ac80ea4 |
|
| BLAKE2b-256 | 33c1c93715f44b16ad7ec52a7b48ae26bdc1880c0192d6075ba3a097e7b04f3e |
snoop-0.4.3-py2.py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | b7418581889ff78b29d9dc5ad4625c4c475c74755fb5cba82c693c6e32afadc0 |
|
| MD5 | 1a5e3a449ba617ccd97f11d67fd466bd |
|
| BLAKE2b-256 | 10b45eb395a7c44f382f42cc4ce2d544223c0506e06c61534f45a2188b8fdf13 |







