SimplEx - 使用示例语料库解释潜在表示


项目描述
SimplEx - 使用示例语料库解释潜在表示



代码作者:Jonathan Crabbé (jc2133@cam.ac.uk)
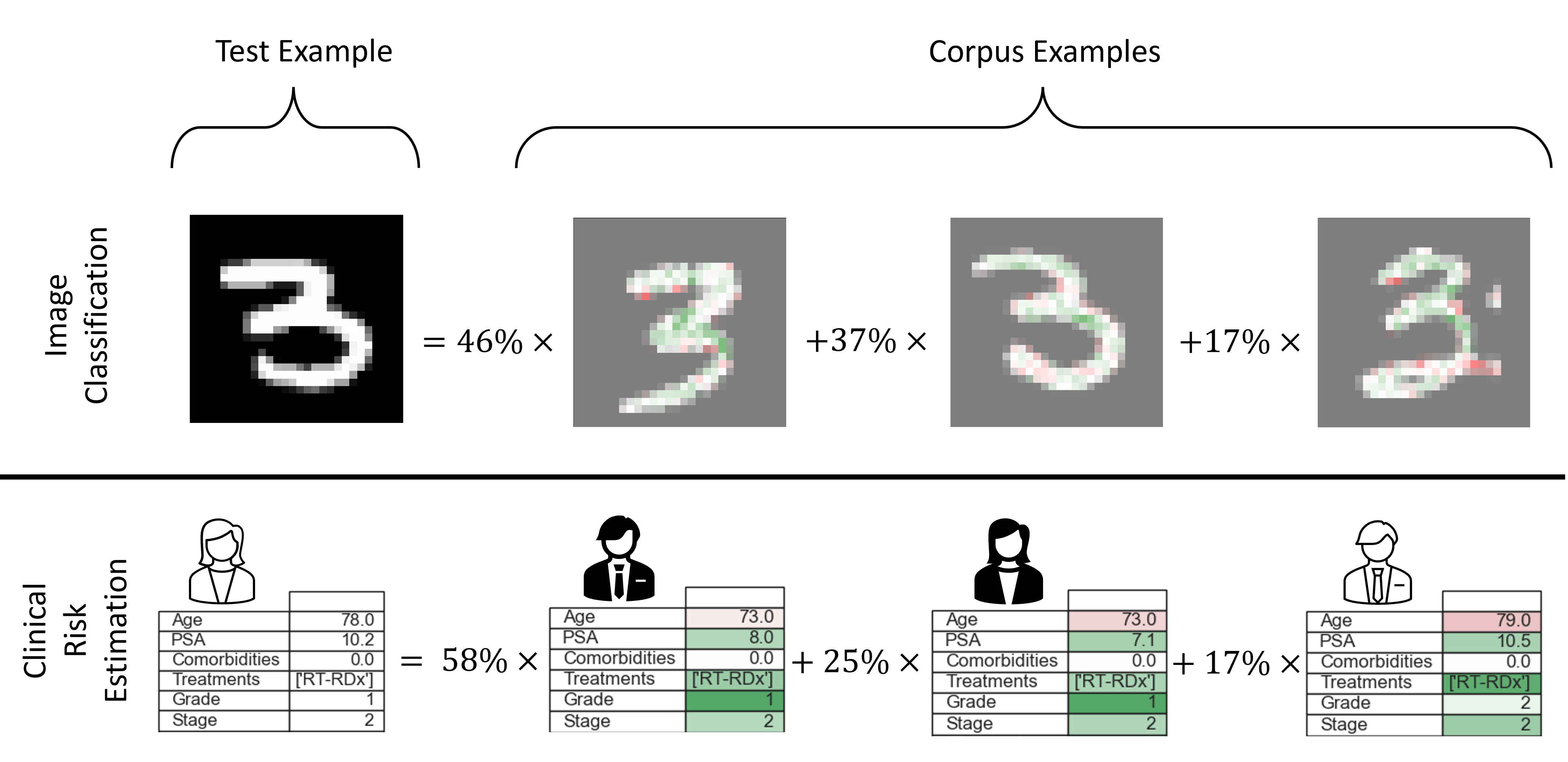
此存储库包含SimplEx的实现,这是一种利用示例语料库解释黑盒模型潜在表示的方法。有关更多详细信息,请阅读我们的NeurIPS 2021论文:“使用示例语料库解释潜在表示”。
:rocket: 安装
可以使用以下方法从PyPI安装此库:
$ pip install simplexai
或者从源安装,使用
$ pip install .
玩具示例
以下是一个玩具演示,其中我们进行测试示例表示的语料库分解。所有相关代码都可以在文件simplex中找到。
from simplexai.explainers.simplex import Simplex
from simplexai.models.image_recognition import MnistClassifier
from simplexai.experiments.mnist import load_mnist
# Get a model
model = MnistClassifier() # Model should have the BlackBox interface
# Load corpus and test inputs
corpus_loader = load_mnist(subset_size=100, train=True, batch_size=100) # MNIST train loader
test_loader = load_mnist(subset_size=10, train=True, batch_size=10) # MNIST test loader
corpus_inputs, _ = next(iter(corpus_loader)) # A tensor of corpus inputs
test_inputs, _ = next(iter(test_loader)) # A set of inputs to explain
# Compute the corpus and test latent representations
corpus_latents = model.latent_representation(corpus_inputs).detach()
test_latents = model.latent_representation(test_inputs).detach()
# Initialize SimplEX, fit it on test examples
simplex = Simplex(corpus_examples=corpus_inputs,
corpus_latent_reps=corpus_latents)
simplex.fit(test_examples=test_inputs,
test_latent_reps=test_latents,
reg_factor=0)
# Get the weights of each corpus decomposition
weights = simplex.weights
我们得到一个张量权重,可以解释如下:weights[i,c] = 例子i分解中语料库示例c的权重。
我们可以通过以下方式获得每个语料库特征对给定示例i分解的重要性
import torch
# Compute the Integrated Jacobian for a particular example
i = 4
input_baseline = torch.zeros(corpus_inputs.shape) # Baseline tensor of the same shape as corpus_inputs
simplex.jacobian_projection(test_id=i, model=model, input_baseline=input_baseline)
result = simplex.decompose(i)
我们得到一个名为 result 的列表,其中每个元素对应于一个语料库示例。此列表按语料库分解的重要性递减顺序排序。列表中的每个元素都是一个结构如下所示的元组
w_c, x_c, proj_jacobian_c = result[c]
其中 w_c 对应于权重 weights[i,c],x_c 对应于 corpus_inputs[c],而 proj_jacobian 是一个张量,使得 proj_jacobian_c[k] 是来自语料库示例 c 的特征 k 的投影雅可比
重现论文结果
重现 MNIST 近似质量实验
- 运行以下脚本来获取不同 CV 值的结果(论文中的结果是通过获取 0 到 9 之间所有整数的 CV 得到的)
python -m simplexai.experiments.mnist -experiment "approximation_quality" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.mnist.quality.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表和数据保存在 此处。
重现前列腺癌近似质量实验
此实验需要访问论文中描述的私有数据集 CUTRACT 和 SEER。
- 将文件
cutract_internal_all.csv和seer_external_imputed_new.csv复制到文件夹data/Prostate Cancer中 - 运行以下脚本来获取不同 CV 值的结果(论文中的结果是通过获取 0 到 9 之间所有整数的 CV 得到的)
python -m simplexai.experiments.prostate_cancer -experiment "approximation_quality" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.prostate.quality.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表保存在 此处。
重现前列腺癌异常值实验
此实验需要访问论文中描述的私有数据集 CUTRACT 和 SEER。
- 确保文件
cutract_internal_all.csv和seer_external_imputed_new.csv位于文件夹data/Prostate Cancer中 - 运行以下脚本来获取不同 CV 值的结果(论文中的结果是通过获取 0 到 9 之间所有整数的 CV 得到的)
python -m simplexai.experiments.prostate_cancer -experiment "outlier_detection" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.prostate.outlier.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表保存在 此处。
重现 MNIST 雅可比投影显著性实验
- 运行以下脚本
python -m simplexai.experiments.mnist -experiment "jacobian_corruption"
2. 生成的图表和数据保存在 此处。
重现 MNIST 异常检测实验
- 运行以下脚本来获取不同 CV 值的结果(论文中的结果是通过获取 0 到 9 之间所有整数的 CV 得到的)
python -m simplexai.experiments.mnist -experiment "outlier_detection" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.mnist.outlier.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表和数据保存在 此处。
重现 MNIST 影响函数实验
- 对于不同的 CV 值运行以下脚本(论文中的结果是通过获取 0 到 4 之间所有整数的 CV 得到的)
python -m simplexai.experiments.mnist -experiment "influence" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.mnist.influence.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表和数据保存在 此处。
注意:与包 Pytorch Influence Functions 有关可能会出现一些问题。如果是这种情况,请按以下方式更改 calc_influence_function.py
343: influences.append(tmp_influence) ==> influences.append(tmp_influence.cpu())
438: influences_meta['test_sample_index_list'] = sample_list ==> #influences_meta['test_sample_index_list'] = sample_list
重现 AR 近似质量实验
- 对于不同的 CV 值运行以下脚本(论文中的结果是通过获取 0 到 4 之间所有整数的 CV 得到的)
python -m simplexai.experiments.time_series -experiment "approximation_quality" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.ar.quality.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表和数据保存在 此处。
重现 AR 异常检测实验
- 对于不同的 CV 值运行以下脚本(论文中的结果是通过获取 0 到 4 之间所有整数的 CV 得到的)
python -m simplexai.experiments.time_series -experiment "outlier_detection" -cv CV
- 通过添加上一步中 CV 的所有值来运行以下脚本
python -m simplexai.experiments.results.ar.outlier.plot_results -cv_list CV1 CV2 CV3 ...
- 生成的图表和数据保存在 此处。
:hammer: 测试
使用以下命令安装测试依赖项
pip install .[testing]
可以使用以下命令执行测试
pytest -vsx
引用
如果您使用此代码,请引用相关的论文
@inproceedings{Crabbe2021Simplex,
author = {Crabbe, Jonathan and Qian, Zhaozhi and Imrie, Fergus and van der Schaar, Mihaela},
booktitle = {Advances in Neural Information Processing Systems},
editor = {M. Ranzato and A. Beygelzimer and Y. Dauphin and P.S. Liang and J. Wortman Vaughan},
pages = {12154--12166},
publisher = {Curran Associates, Inc.},
title = {Explaining Latent Representations with a Corpus of Examples},
url = {https://proceedings.neurips.cc/paper/2021/file/65658fde58ab3c2b6e5132a39fae7cb9-Paper.pdf},
volume = {34},
year = {2021}
}


下载文件
下载适合您平台文件的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。
源代码分发
构建分发
散列 为 simplexai-0.0.3-py3-none-macosx_10_14_x86_64.whl
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | f1276f6c70bf30347a38e8894d686b2a998e74a941973eecaa9c271a7befb585 |
|
| MD5 | 4e199580947a698ba65aadbab8b0353e |
|
| BLAKE2b-256 | 31b5cb3de02db70c321f6813e2ebff9a88ac0d31193b0319d1f698ea06af7c0f |