使用Sentence Transformers的高效少样本学习


项目描述
🤗 模型 | 📊 数据集 | 📕 文档 | 📖 博客 | 📃 论文
SetFit - 使用Sentence Transformers进行高效的少样本学习
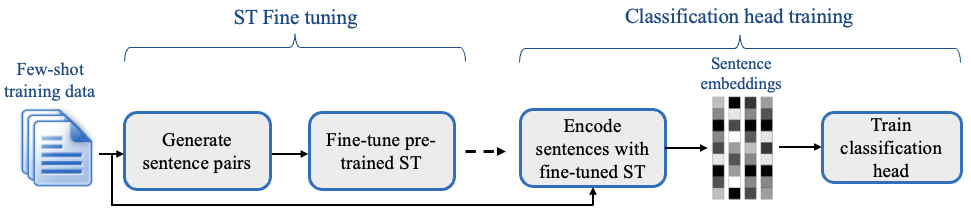
SetFit 是一个高效且无需提示的框架,用于少量样本微调 句子转换器。它在少量标记数据的情况下实现了高精度 - 例如,在客户评论情感数据集上,每个类只有8个标记示例,SetFit 的性能可以与在3k个示例的全训练集上微调 RoBERTa Large 相媲美 🤯!
与其他少量样本学习方法相比,SetFit 具有几个独特的功能
- 🗣 无需提示或口头表达:当前的技术在少量样本微调中需要手工制作的提示或口头表达者将示例转换为适合底层语言模型的格式。SetFit 通过直接从文本示例生成丰富的嵌入来完全摒弃提示。
- 🏎 训练速度快:SetFit 不需要像 T0 或 GPT-3 这样的大型模型来实现高精度。因此,它通常比训练和运行推理快一个数量级(或更多)。
- 🌎 多语言支持:SetFit 可以与 Hub 上的任何 句子转换器一起使用,这意味着您可以通过简单地微调一个多语言检查点来对多种语言的文本进行分类。
有关更多信息,请查看 SetFit 文档!
安装
通过运行以下命令下载并安装 setfit
pip install setfit
如果您想安装最新版本,可以通过运行以下命令从源代码安装
pip install git+https://github.com/huggingface/setfit.git
用法
快速入门教程是了解如何使用 SetFit 模型进行训练、保存、加载和推理的好地方。
有关更多示例,请查看 notebooks 目录、教程 或 如何指南。
训练 SetFit 模型
setfit 与 Hugging Face Hub 集成,并提供两个主要类
SetFitModel:一个包装器,它结合了来自sentence_transformers的预训练主体和来自scikit-learn或SetFitHead(建立在PyTorch之上的可微头部,具有与sentence_transformers相似的 API)的分类头部。Trainer:一个包装器类,用于包装 SetFit 的微调过程。
以下是一个使用来自 scikit-learn 的默认分类头部的简单端到端训练示例
from datasets import load_dataset
from setfit import SetFitModel, Trainer, TrainingArguments, sample_dataset
# Load a dataset from the Hugging Face Hub
dataset = load_dataset("sst2")
# Simulate the few-shot regime by sampling 8 examples per class
train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8)
eval_dataset = dataset["validation"].select(range(100))
test_dataset = dataset["validation"].select(range(100, len(dataset["validation"])))
# Load a SetFit model from Hub
model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-mpnet-base-v2",
labels=["negative", "positive"],
)
args = TrainingArguments(
batch_size=16,
num_epochs=4,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
metric="accuracy",
column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer
)
# Train and evaluate
trainer.train()
metrics = trainer.evaluate(test_dataset)
print(metrics)
# {'accuracy': 0.8691709844559585}
# Push model to the Hub
trainer.push_to_hub("tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2")
# Download from Hub
model = SetFitModel.from_pretrained("tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2")
# Run inference
preds = model.predict(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
print(preds)
# ["positive", "negative"]
重现论文中的结果
我们提供了用于重现论文中第2表所展示的 SetFit 和各种基线结果的脚本。请在 scripts/ 目录中查看设置和训练说明。
开发者安装
要运行此项目中的代码,首先使用例如 Conda 创建 Python 虚拟环境
conda create -n setfit python=3.9 && conda activate setfit
然后使用以下命令安装基本需求
pip install -e '.[dev]'
这将安装 SetFit 的强制包,如 datasets,以及我们用于确保代码格式一致的 black 和 isort 等开发包。
格式化您的代码
我们使用 black 和 isort 确保代码格式一致。在完成安装步骤后,您可以通过运行以下命令在本地检查您的代码
make style && make quality
项目结构
├── LICENSE
├── Makefile <- Makefile with commands like `make style` or `make tests`
├── README.md <- The top-level README for developers using this project.
├── docs <- Documentation source
├── notebooks <- Jupyter notebooks.
├── final_results <- Model predictions from the paper
├── scripts <- Scripts for training and inference
├── setup.cfg <- Configuration file to define package metadata
├── setup.py <- Make this project pip installable with `pip install -e`
├── src <- Source code for SetFit
└── tests <- Unit tests
相关工作
- https://github.com/pmbaumgartner/setfit - SetFit 的 scikit-learn API 版本。
- jxpress/setfit-pytorch-lightning - SetFit 的 PyTorch Lightning 实现。
- davidberenstein1957/spacy-setfit - 一种简单直观的方法,可以与 spaCy 结合使用 SetFit。
引用
@misc{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}


下载文件
下载适用于您的平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。
源代码分发
setfit-1.1.0.tar.gz (84.1 kB 查看哈希值)
构建分发
setfit-1.1.0-py3-none-any.whl (75.2 kB 查看哈希值)