上下文关键词向量


项目描述

sense2vec: 上下文关键词向量
sense2vec (Trask et. al, 2015) 是对 word2vec 的一个很好的改进,允许您学习更有趣和更详细的词向量。此库是一个简单的Python实现,用于加载、查询和训练sense2vec模型。更多详情请参阅 我们的博客文章。要探索2015年和2019年所有Reddit评论之间的语义相似性,请查看 交互式演示。
🦆 版本 2.0 (针对 spaCy v3) 现已发布! 在此处查看发行说明。




✨ 功能

- 基于词性标签和实体标签查询 多词短语 的向量。
- spaCy 管道组件 和 扩展属性。
- 完全可序列化,因此您可以轻松地将 sense2vec 矢量与 spaCy 模型包一起分发。
- 可选的最近邻缓存,用于超级快速的“最相似”查询。
- 使用预训练的 spaCy 模型、原始文本和 GloVe 或通过 fastText(详细信息)训练自己的矢量。
- Prodigy 标注食谱,用于评估模型、创建相似的多词短语列表并将其转换为匹配模式,例如用于基于规则的 NER 或启动 NER 标注(详细信息 & 示例)。
🚀 快速入门
独立使用
from sense2vec import Sense2Vec
s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v[query]
freq = s2v.get_freq(query)
most_similar = s2v.most_similar(query, n=3)
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
作为 spaCy 管道组件使用
⚠️ 注意,此示例描述的是与 spaCy v3 的使用。对于与 spaCy v2 的使用,请下载
sense2vec==1.0.3并查看此存储库的v1.x分支。
import spacy
nlp = spacy.load("en_core_web_sm")
s2v = nlp.add_pipe("sense2vec")
s2v.from_disk("/path/to/s2v_reddit_2015_md")
doc = nlp("A sentence about natural language processing.")
assert doc[3:6].text == "natural language processing"
freq = doc[3:6]._.s2v_freq
vector = doc[3:6]._.s2v_vec
most_similar = doc[3:6]._.s2v_most_similar(3)
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]
交互式演示
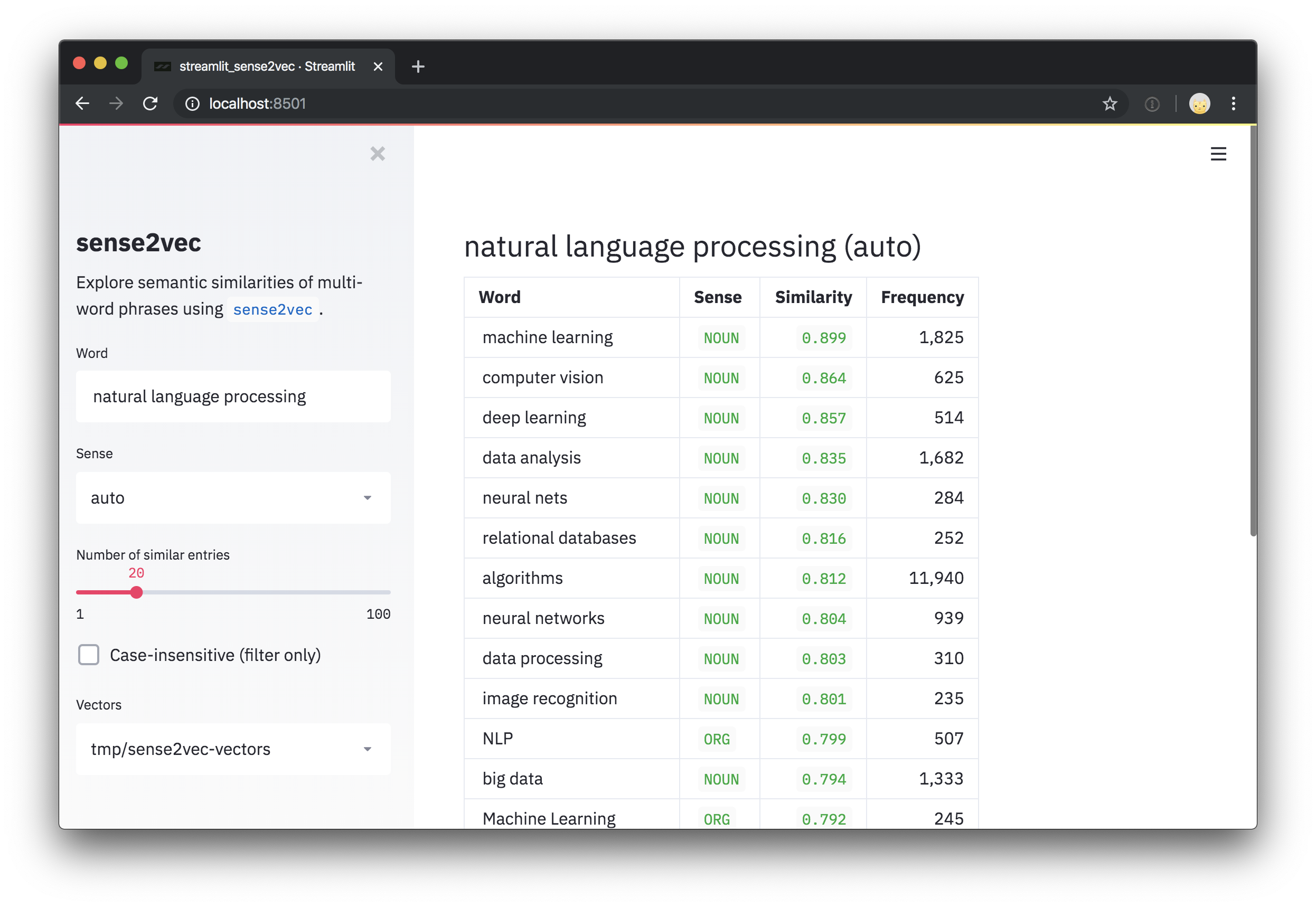
要尝试使用 Reddit 评论训练的预训练矢量,请查看 交互式 sense2vec 演示。
此存储库还包括一个 Streamlit 演示脚本,用于探索矢量和最相似短语。安装 streamlit 后,您可以使用 streamlit run 运行脚本,并将预训练矢量的一个或多个路径作为 位置参数 传递到命令行。例如
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors
预训练矢量
要使用这些矢量,请下载存档,并将提取的目录传递给 Sense2Vec.from_disk 或 Sense2VecComponent.from_disk。矢量文件已附加到 GitHub 发布中。大型文件已分成多个部分下载。
| 矢量 | 大小 | 描述 | 📥 下载(压缩包) |
|---|---|---|---|
s2v_reddit_2019_lg |
4 GB | Reddit 评论 2019(01-07) | 部分 1、部分 2、部分 3 |
s2v_reddit_2015_md |
573 MB | Reddit 评论 2015 | 部分 1 |
要合并多部分存档,您可以运行以下命令
cat s2v_reddit_2019_lg.tar.gz.* > s2v_reddit_2019_lg.tar.gz
⏳ 安装 & 设置
sense2vec 发布可在 pip 上找到
pip install sense2vec
要使用预训练矢量,请下载 矢量软件包之一,解压缩 .tar.gz 存档,并将 from_disk 指向提取的数据目录
from sense2vec import Sense2Vec
s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
👩💻 使用
与 spaCy v3 的使用
使用库和矢量的最简单方法是将其插入到您的 spaCy 管道中。`sense2vec` 软件包公开了一个 `Sense2VecComponent`,可以与其共享词汇初始化,并将其作为 自定义管道组件 添加到您的 spaCy 管道中。默认情况下,组件被添加到管道的 末尾,这是该组件的推荐位置,因为它需要访问依存句法和(如果有的话)命名实体。
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy.load("en_core_web_sm")
s2v = nlp.add_pipe("sense2vec")
s2v.from_disk("/path/to/s2v_reddit_2015_md")
该组件将为 spaCy 的 Token 和 Span 对象添加几个 扩展属性和方法,让您可以检索矢量和频率,以及最相似术语。
doc = nlp("A sentence about natural language processing.")
assert doc[3:6].text == "natural language processing"
freq = doc[3:6]._.s2v_freq
vector = doc[3:6]._.s2v_vec
most_similar = doc[3:6]._.s2v_most_similar(3)
对于实体,使用实体标签作为“概念”(而不是标记的词性标签)
doc = nlp("A sentence about Facebook and Google.")
for ent in doc.ents:
assert ent._.in_s2v
most_similar = ent._.s2v_most_similar(3)
可用属性
以下扩展属性通过 Doc 对象的 ._ 属性公开
| 名称 | 属性类型 | 类型 | 描述 |
|---|---|---|---|
s2v_phrases |
属性 | 列表 | 给定 Doc 中的所有 sense2vec 兼容短语(名词短语、命名实体)。 |
以下属性可通过 Token 和 Span 对象的 ._ 属性获取 - 例如 token._.in_s2v
| 名称 | 属性类型 | 返回类型 | 描述 |
|---|---|---|---|
in_s2v |
属性 | bool | 键是否存在于向量映射中。 |
s2v_key |
属性 | unicode | 给定对象的 sense2vec 键,例如 `"duck` |
s2v_vec |
属性 | ndarray[float32] |
给定键的向量。 |
s2v_freq |
属性 | int | 给定键的频率。 |
s2v_other_senses |
属性 | 列表 | 可用的其他意义,例如 `"duck` |
s2v_most_similar |
方法 | 列表 | 获取前 n 个最相似项。返回一个包含 ((word, sense), score) 元组的列表。 |
s2v_similarity |
方法 | float | 获取与另一个 Token 或 Span 的相似度。 |
⚠️ 关于 span 属性的说明: 在内部,
doc.ents中的实体是Span对象。这也是为什么管道组件也为 span 添加属性和方法,而不仅仅是 token。然而,不建议在任意文档片段上使用 sense2vec 属性,因为模型可能没有相应文本的键。此外,Span对象也没有词性标签,如果没有实体标签,则“意义”默认为根的词性标签。
将 sense2vec 添加到训练好的管道
如果您正在训练和打包 spaCy 管道,并希望在其中包含 sense2vec 组件,您可以通过训练配置的 [initialize] 块 加载数据。
[initialize.components]
[initialize.components.sense2vec]
data_path = "/path/to/s2v_reddit_2015_md"
独立使用
您还可以直接使用底层的 Sense2Vec 类,并使用 from_disk 方法加载数据。下面列出了可用的 API 方法。
from sense2vec import Sense2Vec
s2v = Sense2Vec().from_disk("/path/to/reddit_vectors-1.1.0")
most_similar = s2v.most_similar("natural_language_processing|NOUN", n=10)
⚠️ 重要说明: 要在向量表中查找条目,键需要遵循
phrase_text|SENSE方案(注意_替换了空格,且在标签或标签之前有|) - 例如,machine_learning|NOUN。另外,请注意底层向量表是区分大小写的。
🎛 API
class Sense2Vec
包含向量、字符串和频率的独立 Sense2Vec 对象。
method Sense2Vec.__init__
初始化 Sense2Vec 对象。
| 参数 | 类型 | 描述 |
|---|---|---|
shape |
tuple | 向量形状。默认为 (1000, 128)。 |
strings |
spacy.strings.StringStore |
可选字符串存储。如果不存在,则创建。 |
senses |
列表 | 可选的可用意义列表。用于生成最佳意义或其他意义的方法。 |
vectors_name |
unicode | 可选名称,用于分配给 Vectors 表,以防止冲突。默认为 "sense2vec"。 |
overrides |
dict | 可选的自定义函数,映射到通过注册表注册的名称,例如 {"make_key": "custom_make_key"}。 |
| 返回值 | Sense2Vec |
新构建的对象。 |
s2v = Sense2Vec(shape=(300, 128), senses=["VERB", "NOUN"])
method Sense2Vec.__len__
向量表中的行数。
| 参数 | 类型 | 描述 |
|---|---|---|
| 返回值 | int | 向量表中的行数。 |
s2v = Sense2Vec(shape=(300, 128))
assert len(s2v) == 300
method Sense2Vec.__contains__
检查键是否在向量表中。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 要查找的键。 |
| 返回值 | bool | 键是否在表中。 |
s2v = Sense2Vec(shape=(10, 4))
s2v.add("avocado|NOUN", numpy.asarray([4, 2, 2, 2], dtype=numpy.float32))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v
method Sense2Vec.__getitem__
检索给定键的向量。如果键不在表中,则返回 None。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 要查找的键。 |
| 返回值 | numpy.ndarray |
向量或 None。 |
vec = s2v["avocado|NOUN"]
method Sense2Vec.__setitem__
为给定键设置向量。如果键不存在,将引发错误。要添加新条目,请使用 Sense2Vec.add。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 键。 |
vector |
numpy.ndarray |
要设置的向量。 |
vec = s2v["avocado|NOUN"]
s2v["avacado|NOUN"] = vec
method Sense2Vec.add
向表中添加新向量。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 要添加的键。 |
vector |
numpy.ndarray |
要添加的向量。 |
freq |
int | 可选频率计数。用于找到最佳匹配的意义。 |
vec = s2v["avocado|NOUN"]
s2v.add("🥑|NOUN", vec, 1234)
method Sense2Vec.get_freq
获取给定键的频率计数。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 要查找的键。 |
default |
- | 未找到频率时返回的默认值。 |
| 返回值 | int | 频率计数。 |
vec = s2v["avocado|NOUN"]
s2v.add("🥑|NOUN", vec, 1234)
assert s2v.get_freq("🥑|NOUN") == 1234
方法 Sense2Vec.set_freq
为给定的键设置频率计数。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 要设置计数的键。 |
freq |
int | 频率计数。 |
s2v.set_freq("avocado|NOUN", 104294)
方法 Sense2Vec.__iter__, Sense2Vec.items
遍历向量表中的条目。
| 参数 | 类型 | 描述 |
|---|---|---|
| 产生 | tuple | 表中的字符串键和向量对。 |
for key, vec in s2v:
print(key, vec)
for key, vec in s2v.items():
print(key, vec)
方法 Sense2Vec.keys
遍历表中的键。
| 参数 | 类型 | 描述 |
|---|---|---|
| 产生 | unicode | 表中的字符串键。 |
all_keys = list(s2v.keys())
方法 Sense2Vec.values
遍历表中的向量。
| 参数 | 类型 | 描述 |
|---|---|---|
| 产生 | numpy.ndarray |
表中的向量。 |
all_vecs = list(s2v.values())
属性 Sense2Vec.senses
表中的可用词义,例如 "NOUN" 或 "VERB" (在初始化时添加)。
| 参数 | 类型 | 描述 |
|---|---|---|
| 返回值 | 列表 | 可用的词义。 |
s2v = Sense2Vec(senses=["VERB", "NOUN"])
assert "VERB" in s2v.senses
属性 Sense2vec.frequencies
表中的键的频率,按降序排列。
| 参数 | 类型 | 描述 |
|---|---|---|
| 返回值 | 列表 | 按频率降序排列的 (key, freq) 元组。 |
most_frequent = s2v.frequencies[:10]
key, score = s2v.frequencies[0]
方法 Sense2vec.similarity
对两个键或两套键进行语义相似度估计。默认估计是使用向量平均值的余弦相似度。
| 参数 | 类型 | 描述 |
|---|---|---|
keys_a |
unicode / int / 可迭代对象 | 字符串或整数键。 |
keys_b |
unicode / int / 可迭代对象 | 其他字符串或整数键。 |
| 返回值 | float | 相似度得分。 |
keys_a = ["machine_learning|NOUN", "natural_language_processing|NOUN"]
keys_b = ["computer_vision|NOUN", "object_detection|NOUN"]
print(s2v.similarity(keys_a, keys_b))
assert s2v.similarity("machine_learning|NOUN", "machine_learning|NOUN") == 1.0
方法 Sense2Vec.most_similar
获取表中最相似的条目。如果提供了多个键,则使用向量的平均值。要使此方法更快,请参阅预计算最近邻缓存的脚本。
| 参数 | 类型 | 描述 |
|---|---|---|
keys |
unicode / int / 可迭代对象 | 要比较的字符串或整数键。 |
n |
int | 要返回的相似键的数量。默认为 10。 |
batch_size |
int | 要使用的批量大小。默认为 16。 |
| 返回值 | 列表 | 最相似向量的 (key, score) 元组。 |
most_similar = s2v.most_similar("natural_language_processing|NOUN", n=3)
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
方法 Sense2Vec.get_other_senses
找到具有不同词义的同义词的其他条目,例如 "duck|VERB" 对 "duck|NOUN"。
| 参数 | 类型 | 描述 |
|---|---|---|
key |
unicode / int | 要检查的键。 |
ignore_case |
bool | 检查大写、小写和首字母大写。默认为 True。 |
| 返回值 | 列表 | 具有不同词义的其他条目的字符串键。 |
other_senses = s2v.get_other_senses("duck|NOUN")
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ']
方法 Sense2Vec.get_best_sense
根据可用的词义和频率计数,找到给定单词的最佳匹配词义。如果没有找到匹配项,则返回 None。
| 参数 | 类型 | 描述 |
|---|---|---|
word |
unicode | 要检查的单词。 |
senses |
列表 | 可选的词义列表,用于限制搜索。如果没有设置/为空,则使用向量中的所有词义。 |
ignore_case |
bool | 检查大写、小写和首字母大写。默认为 True。 |
| 返回值 | unicode | 最佳匹配键或 None。 |
assert s2v.get_best_sense("duck") == "duck|NOUN"
assert s2v.get_best_sense("duck", ["VERB", "ADJ"]) == "duck|VERB"
方法 Sense2Vec.to_bytes
将 Sense2Vec 对象序列化为字节串。
| 参数 | 类型 | 描述 |
|---|---|---|
exclude |
列表 | 要排除的序列化字段名称。 |
| 返回值 | bytes | 序列化的 Sense2Vec 对象。 |
s2v_bytes = s2v.to_bytes()
方法 Sense2Vec.from_bytes
从字节串加载 Sense2Vec 对象。
| 参数 | 类型 | 描述 |
|---|---|---|
bytes_data |
bytes | 要加载的数据。 |
exclude |
列表 | 要排除的序列化字段名称。 |
| 返回值 | Sense2Vec |
加载的对象。 |
s2v_bytes = s2v.to_bytes()
new_s2v = Sense2Vec().from_bytes(s2v_bytes)
方法 Sense2Vec.to_disk
将 Sense2Vec 对象序列化到目录中。
| 参数 | 类型 | 描述 |
|---|---|---|
path |
unicode / Path |
路径。 |
exclude |
列表 | 要排除的序列化字段名称。 |
s2v.to_disk("/path/to/sense2vec")
方法 Sense2Vec.from_disk
从目录中加载 Sense2Vec 对象。
| 参数 | 类型 | 描述 |
|---|---|---|
path |
unicode / Path |
要加载的路径 |
exclude |
列表 | 要排除的序列化字段名称。 |
| 返回值 | Sense2Vec |
加载的对象。 |
s2v.to_disk("/path/to/sense2vec")
new_s2v = Sense2Vec().from_disk("/path/to/sense2vec")
类 Sense2VecComponent
将 sense2vec 添加到 spaCy 管道中的管道组件。
方法 Sense2VecComponent.__init__
初始化管道组件。
| 参数 | 类型 | 描述 |
|---|---|---|
vocab |
Vocab |
共享的 Vocab。主要用于共享的 StringStore。 |
shape |
tuple | 向量形状。 |
merge_phrases |
bool | 是否将sense2vec短语合并为一个标记。默认为False。 |
词形还原 |
bool | 如果向量中有可用词形,则始终查找词形,否则默认为原始单词。默认为False。 |
overrides |
可选的自定义函数,映射到通过注册表注册的名称,例如{"make_key": "custom_make_key"}。 |
|
| 返回值 | Sense2VecComponent |
新构建的对象。 |
s2v = Sense2VecComponent(nlp.vocab)
classmethod Sense2VecComponent.from_nlp
从nlp对象初始化组件。主要用于入口点的组件工厂(参见setup.cfg)以及通过@spacy.component装饰器自动注册。
| 参数 | 类型 | 描述 |
|---|---|---|
nlp |
语言 |
nlp对象。 |
**cfg |
- | 可选配置参数。 |
| 返回值 | Sense2VecComponent |
新构建的对象。 |
s2v = Sense2VecComponent.from_nlp(nlp)
method Sense2VecComponent.__call__
使用组件处理Doc对象。通常仅在spaCy管道中作为部分调用,而不是直接调用。
| 参数 | 类型 | 描述 |
|---|---|---|
doc |
Doc |
要处理的文档。 |
| 返回值 | Doc |
处理后的文档。 |
method Sense2Vec.init_component
在此处注册特定于组件的扩展属性,并且仅在将组件添加到管道并使用时才这样做 - 否则,即使组件仅创建而没有添加,标记仍会获取属性。
method Sense2VecComponent.to_bytes
将组件序列化为字节串。当将组件添加到管道并运行nlp.to_bytes时也会调用。
| 参数 | 类型 | 描述 |
|---|---|---|
| 返回值 | bytes | 序列化的组件。 |
method Sense2VecComponent.from_bytes
从字节串加载组件。当您运行nlp.from_bytes时也会调用。
| 参数 | 类型 | 描述 |
|---|---|---|
bytes_data |
bytes | 要加载的数据。 |
| 返回值 | Sense2VecComponent |
加载的对象。 |
method Sense2VecComponent.to_disk
将组件序列化到目录中。当将组件添加到管道并运行nlp.to_disk时也会调用。
| 参数 | 类型 | 描述 |
|---|---|---|
path |
unicode / Path |
路径。 |
method Sense2VecComponent.from_disk
从目录加载Sense2Vec对象。当您运行nlp.from_disk时也会调用。
| 参数 | 类型 | 描述 |
|---|---|---|
path |
unicode / Path |
要加载的路径 |
| 返回值 | Sense2VecComponent |
加载的对象。 |
class registry
函数注册表(由catalogue提供动力),可轻松自定义用于生成键和短语的函数。允许您装饰和命名自定义函数,替换它们并在保存模型时序列化自定义名称。以下注册表选项可用
| 名称 | 描述 |
|---|---|
registry.make_key |
给定一个word和一个sense,返回键的字符串,例如"word |
registry.split_key |
给定一个字符串键,返回一个(word, sense)元组。 |
registry.make_spacy_key |
给定一个spaCy对象(Token或Span)和一个布尔关键字参数prefer_ents(是否更喜欢单个标记的实体标签),返回一个(word, sense)元组。用于扩展属性以生成标记和短语的键。 |
registry.get_phrases |
给定一个spaCy Doc,返回用于sense2vec短语的Span对象列表(通常是名词短语和命名实体)。 |
registry.merge_phrases |
给定一个spaCy Doc,获取所有sense2vec短语并将它们合并为单个标记。 |
每个注册表都有一个register方法,可以用作函数装饰器,并接受一个参数,即自定义函数的名称。
from sense2vec import registry
@registry.make_key.register("custom")
def custom_make_key(word, sense):
return f"{word}###{sense}"
@registry.split_key.register("custom")
def custom_split_key(key):
word, sense = key.split("###")
return word, sense
在初始化Sense2Vec对象时,您现在可以传递一个包含您的自定义注册函数名称的重写字典。
overrides = {"make_key": "custom", "split_key": "custom"}
s2v = Sense2Vec(overrides=overrides)
这使得轻松尝试不同的策略并将策略作为普通字符串序列化(而不是必须传递和/或pickle函数本身)变得容易。
🚂 训练自己的sense2vec向量
/scripts目录包含用于预处理文本和训练自己的向量的命令行实用工具。
要求
要训练自己的sense2vec向量,您需要以下内容
- 一个非常大的原始文本来源(理想情况下应超过您用于word2vec的文本量,因为词义会使词汇表更加稀疏)。我们建议至少有10亿个单词。
- 一个预训练的spaCy模型,用于分配词性标签、依存关系和命名实体,并填充
doc.noun_chunks。如果您需要的语言没有提供内置的名词短语的语法迭代器,您需要编写自己的。 (doc.noun_chunks和doc.ents是sense2vec用于确定什么是短语的内容。) - 已安装和构建GloVe或fastText。您应该能够克隆存储库并在相应的目录中运行
make。
逐步过程
训练过程分为几个步骤,以便您可以在任何给定点恢复。处理脚本旨在对单个文件进行操作,这使得并行化工作变得容易。此存储库中的脚本需要Glove或fastText,您需要克隆并运行相应的make。
对于Fasttext,脚本将需要创建的二进制文件的路径。如果您在Windows上工作,可以使用cmake构建,或者使用此非官方存储库中的.exe文件,该存储库包含Windows上FastText的二进制构建:https://github.com/xiamx/fastText/releases。
| 脚本 | 描述 | |
|---|---|---|
| 1. | 01_parse.py |
使用spaCy解析原始文本,并输出二进制的Doc对象集合(参见DocBin)。 |
| 2. | 02_preprocess.py |
加载前一步产生的解析Doc对象集合,并以sense2vec格式输出文本文件(每行一个句子,合并短语和词义)。 |
| 3. | 03_glove_build_counts.py |
使用GloVe构建词汇和计数。如果您使用FastText进行Word2Vec,则可跳过此步骤。 |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py |
使用GloVe或FastText训练向量。 |
| 5. | 05_export.py |
加载向量和频率,并输出一个可以通过Sense2Vec.from_disk加载的sense2vec组件。 |
| 6. | 06_precompute_cache.py |
(可选):为词汇表中的每个条目预计算最近邻查询,以便使Sense2Vec.most_similar更快。 |
有关脚本的更多详细文档,请查看源代码或使用--help运行它们。例如,python scripts/01_parse.py --help。
🍳 Prodigy配方
此软件包还与Prodigy注释工具无缝集成,并公开使用sense2vec向量生成多词短语列表和引导NER注释的配方。要使用配方,需要在与Prodigy相同的环境中安装sense2vec。要查看实际用例的示例,请查看此NER项目,其中包含可下载的数据集。
以下配方可用 – 请参阅下面的详细文档。
| 配方 | 描述 |
|---|---|
sense2vec.teach |
使用sense2vec引导术语列表。 |
sense2vec.to-patterns |
将短语数据集转换为基于标记的模式。 |
sense2vec.eval |
通过询问短语三元组来评估sense2vec模型。 |
sense2vec.eval-most-similar |
通过纠正最相似条目来评估sense2vec模型。 |
sense2vec.eval-ab |
执行两个预训练的sense2vec向量模型之间的A/B评估。 |
recipe sense2vec.teach
使用sense2vec引导术语列表。Prodigy将根据sense2vec中最相似短语建议类似术语,并且随着您注释和接受类似短语,建议将被调整。对于每个种子术语,将使用根据sense2vec向量最佳匹配的词义。
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]
| 参数 | 类型 | 描述 |
|---|---|---|
数据集 |
位置信息 | 用于保存标注的数据集。 |
向量路径 |
位置信息 | 预训练的sense2vec向量的路径。 |
--seeds, -s |
选项 | 一个或多个以逗号分隔的种子短语。 |
--threshold, -t |
选项 | 相似度阈值。默认为0.85。 |
--n-similar, -n |
选项 | 一次性获取的相似项目数量。 |
--batch-size, -b |
选项 | 提交标注的批大小。 |
--resume, -R |
标志 | 从现有的短语数据集中恢复。 |
示例
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds "natural language processing, machine learning, artificial intelligence"
recipe sense2vec.to-patterns
将使用sense2vec.teach收集的短语数据集转换为基于标记的匹配模式,这些模式可以用于与spaCy的EntityRuler或如ner.match之类的食谱。如果未指定输出文件,模式将被写入stdout。示例被标记化,以便正确表示多标记项,例如:{"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]}。
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]
| 参数 | 类型 | 描述 |
|---|---|---|
数据集 |
位置信息 | 要转换的短语数据集。 |
spacy_model |
位置信息 | 用于标记化的spaCy模型。 |
label |
位置信息 | 应用于所有模式的标签。 |
--output-file, -o |
选项 | 可选的输出文件。默认为stdout。 |
--case-sensitive, -CS |
标志 | 使模式区分大小写。 |
--dry, -D |
标志 | 执行Dry Run而不输出任何内容。 |
示例
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonl
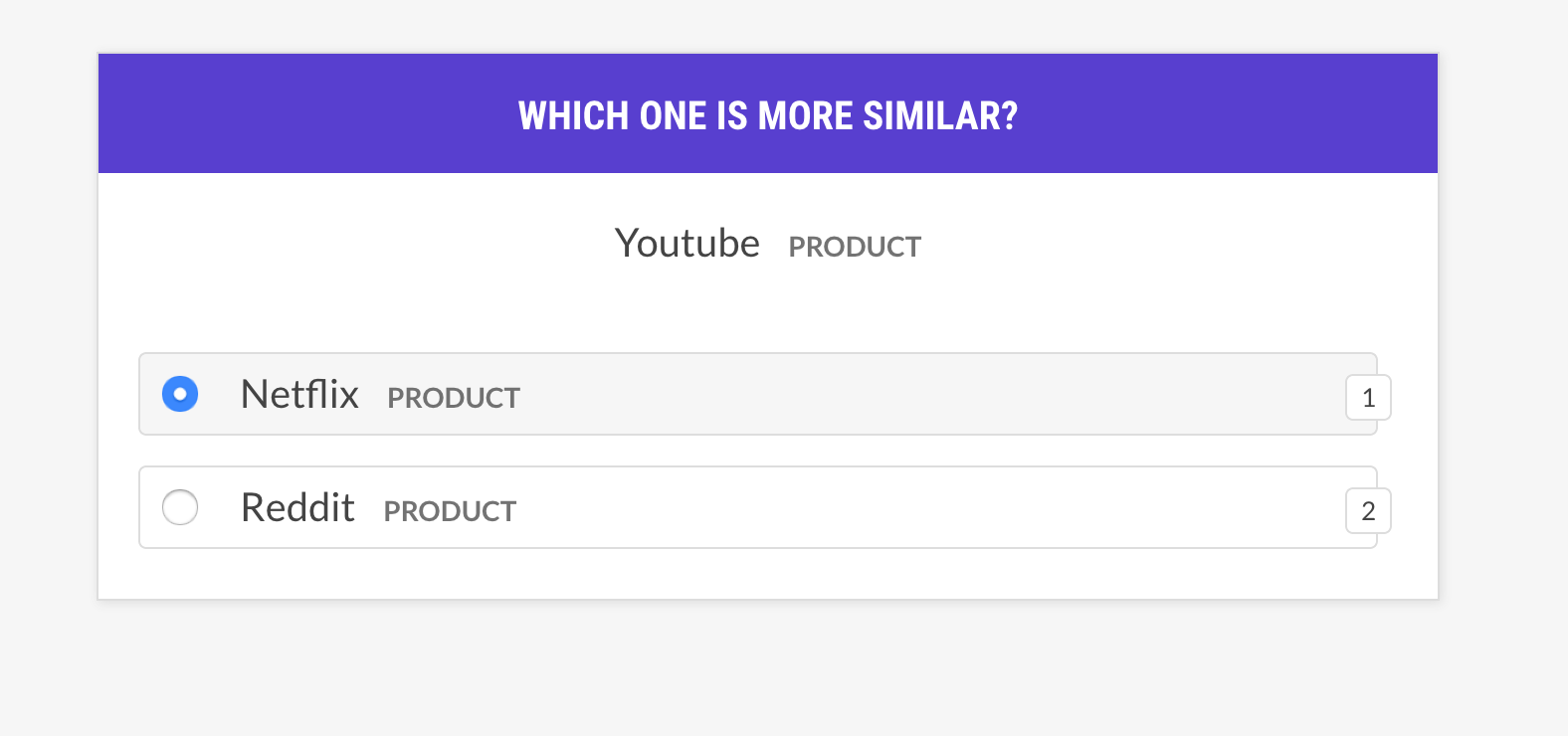
recipe sense2vec.eval
通过询问短语三元组来评估sense2vec模型:单词A与单词B更相似,还是与单词C更相似?如果人类大多同意模型的看法,则向量模型是好的。该食谱只会询问具有相同意义的向量,并支持不同的示例选择策略。
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]
| 参数 | 类型 | 描述 |
|---|---|---|
数据集 |
位置信息 | 用于保存标注的数据集。 |
向量路径 |
位置信息 | 预训练的sense2vec向量的路径。 |
--strategy, -st |
选项 | 示例选择策略。most_similar(默认)或random。 |
--senses, -s |
选项 | 以逗号分隔的感官列表,以限制选择。如果没有设置,将使用向量中的所有感官。 |
--exclude-senses, -es |
选项 | 以逗号分隔的感官列表,以排除。有关默认值,请参阅prodigy_recipes.EVAL_EXCLUDE_SENSES。 |
--n-freq, -f |
选项 | 限制到最频繁的条目数量。 |
--threshold, -t |
选项 | 考虑示例的最小相似度阈值。 |
--batch-size, -b |
选项 | 要使用的批大小。 |
--eval-whole, -E |
标志 | 评估整个数据集而不是当前会话。 |
--eval-only, -O |
标志 | 不进行标注,仅评估当前数据集。 |
--show-scores, -S |
标志 | 显示所有分数以进行调试。 |
策略
| 名称 | 描述 |
|---|---|
most_similar |
从随机感官中随机选择一个单词,并获取其相同感官的最相似条目。询问对该选择中的最后和中间条目的相似度。 |
most_least_similar |
从随机感官的相似条目中选择最不相似的条目,然后是该选择中的最后最相似的条目。 |
random |
从相同随机感官中选择3个随机单词的样本。 |
示例
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5
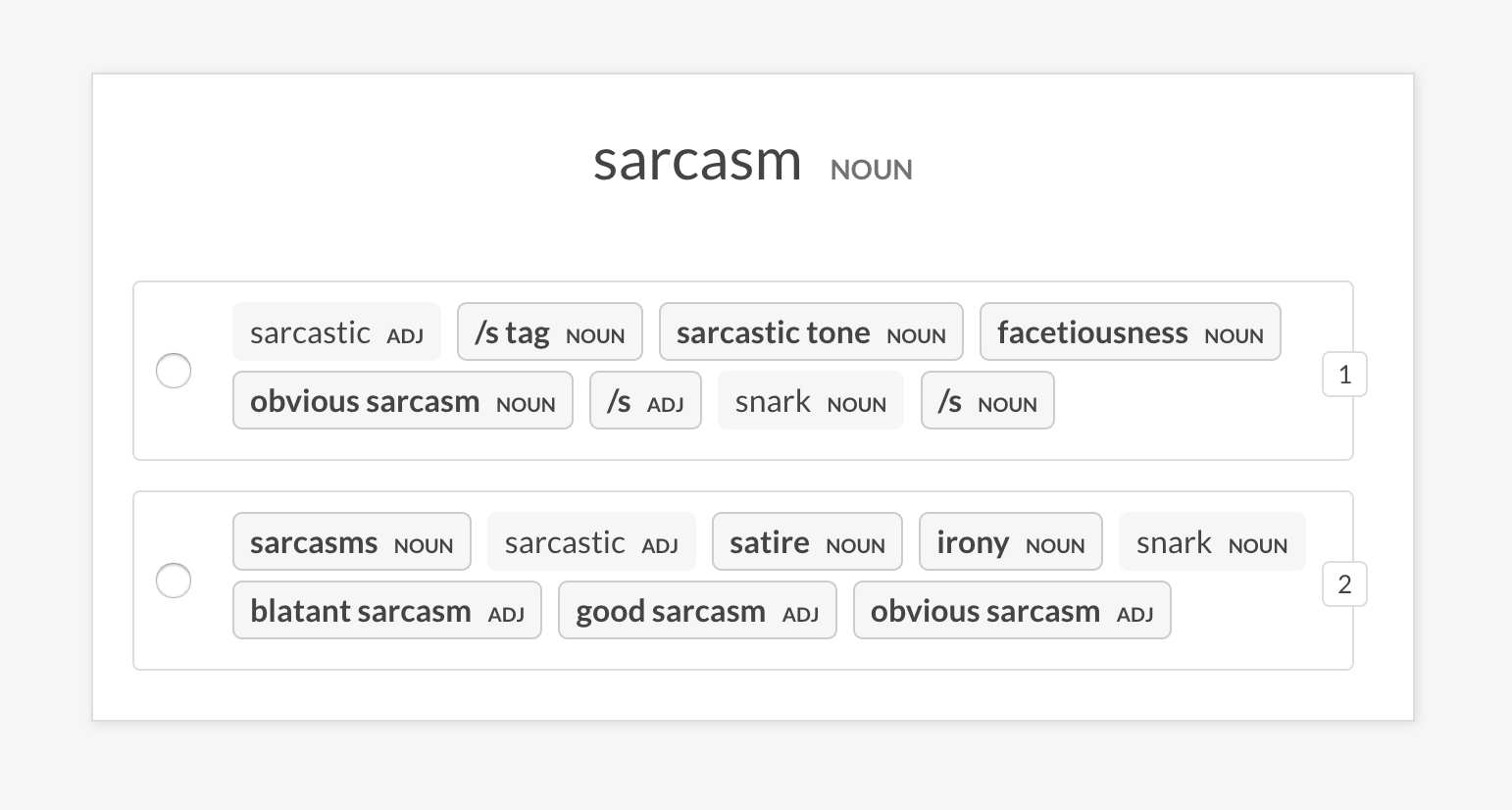
recipe sense2vec.eval-most-similar
通过查看随机短语返回的最相似条目来评估向量模型。
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]
| 参数 | 类型 | 描述 |
|---|---|---|
数据集 |
位置信息 | 用于保存标注的数据集。 |
向量路径 |
位置信息 | 预训练的sense2vec向量的路径。 |
--senses, -s |
选项 | 以逗号分隔的感官列表,以限制选择。如果没有设置,将使用向量中的所有感官。 |
--exclude-senses, -es |
选项 | 以逗号分隔的感官列表,以排除。有关默认值,请参阅prodigy_recipes.EVAL_EXCLUDE_SENSES。 |
--n-freq, -f |
选项 | 限制到最频繁的条目数量。 |
--n-similar, -n |
选项 | 要检查的相似项目数量。默认为10。 |
--batch-size, -b |
选项 | 要使用的批大小。 |
--eval-whole, -E |
标志 | 评估整个数据集而不是当前会话。 |
--eval-only, -O |
标志 | 不进行标注,仅评估当前数据集。 |
--show-scores, -S |
标志 | 显示所有分数以进行调试。 |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT
recipe sense2vec.eval-ab
通过比较随机短语返回的最相似条目来对两个预训练的sense2vec向量模型进行A/B评估。UI显示两个随机选项,每个模型的最相似条目,并突出显示不同的短语。在标注会话结束时,将显示整体统计信息和首选模型。
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]
| 参数 | 类型 | 描述 |
|---|---|---|
数据集 |
位置信息 | 用于保存标注的数据集。 |
向量路径_a |
位置信息 | 预训练的sense2vec向量的路径。 |
向量路径_b |
位置信息 | 预训练的sense2vec向量的路径。 |
--senses, -s |
选项 | 以逗号分隔的感官列表,以限制选择。如果没有设置,将使用向量中的所有感官。 |
--exclude-senses, -es |
选项 | 以逗号分隔的感官列表,以排除。有关默认值,请参阅prodigy_recipes.EVAL_EXCLUDE_SENSES。 |
--n-freq, -f |
选项 | 限制到最频繁的条目数量。 |
--n-similar, -n |
选项 | 要检查的相似项目数量。默认为10。 |
--batch-size, -b |
选项 | 要使用的批大小。 |
--eval-whole, -E |
标志 | 评估整个数据集而不是当前会话。 |
--eval-only, -O |
标志 | 不进行标注,仅评估当前数据集。 |
--show-mapping, -S |
标志 | 在UI中显示哪些模型是选项1和选项2(用于调试)。 |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT
预训练矢量
预训练的Reddit向量支持以下“意义”,即词性标签或实体标签。有关更多详情,请参阅spaCy的标注方案概述。
| 标签 | 描述 | 示例 |
|---|---|---|
ADJ |
形容词 | 大,老,绿 |
ADP |
介词 | 在,到,在…期间 |
ADV |
副词 | 非常,明天,向下,在哪里 |
AUX |
助动词 | 是,已经(做了),将会(做) |
CONJ |
连词 | 和,或,但 |
DET |
限定词 | 一个,一个,这个 |
INTJ |
感叹词 | 嘘,哎哟,好极了,你好 |
NOUN |
名词 | 女孩,猫,树,空气,美丽 |
NUM |
数词 | 1,2017,一个,77,MMXIV |
PART |
小品词 | 's,不 |
PRON |
代词 | 我,你,他,她,我自己,某人 |
PROPN |
专有名词 | 玛丽,约翰,伦敦,北约,HBO |
PUNCT |
标点符号 | , ? ( ) |
SCONJ |
从属连词 | 如果,当…时,那 |
SYM |
符号 | $,%,=,:(,😝 |
VERB |
动词 | 跑,跑着,跑,吃,吃了,吃着 |
| 实体标签 | 描述 |
|---|---|
PERSON |
人,包括虚构人物。 |
NORP |
国籍或宗教或政治团体。 |
FACILITY |
建筑,机场,公路,桥梁等。 |
ORG |
公司,机构,机构等。 |
GPE |
国家,城市,州。 |
LOC |
非GPE地点,山脉,水体。 |
PRODUCT |
物体,车辆,食物等。(非服务。) |
EVENT |
命名飓风,战役,战争,体育赛事等。 |
WORK_OF_ART |
书籍,歌曲等的标题。 |
LANGUAGE |
任何命名语言。 |


下载文件
下载您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。