提供用于构建scrapy查询的UI工具的包

项目描述
需要Python 3.6+
Scrapy GUI
一个简单、由Qt-Webengine支持的浏览器,内置了测试scrapy蜘蛛代码的功能。
还包括一个插件,可以为scrapy shell启用GUI。
目录
安装
您可以使用以下命令从PyPi导入包:
pip install scrapy_gui
然后您可以使用 import scrapy_gui 将其导入到shell中。
独立UI
您可以使用从Python shell中的 scrapy_gui.open_browser() 打开独立UI。这包括一个网络浏览器和一些用于分析其内容的工具。
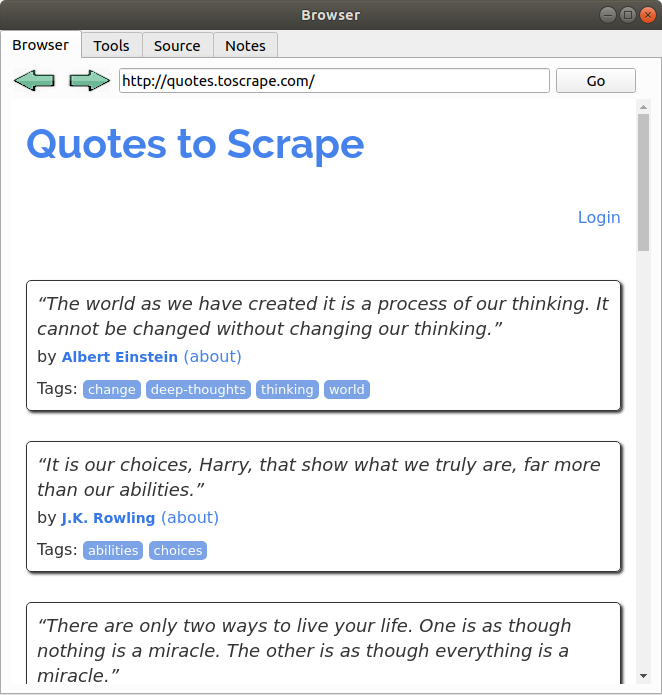
浏览器标签
在搜索栏中输入任何URL并按回车键或按Go按钮。当加载动画完成后,它将在工具标签中准备好解析。
工具标签
工具标签包含用于解析页面内容的各个部分。该标签的目的是使测试用于scrapy蜘蛛的查询和代码变得容易。
注意: 这将使用 初始 HTML响应。如果后续的请求、JavaScript等更改了页面,则不会考虑这些更改。
它将使用 requests 包发送附加请求来加载初始HTML。在运行查询时,它将使用 parsel 包中的 Selection 创建一个选择器对象。
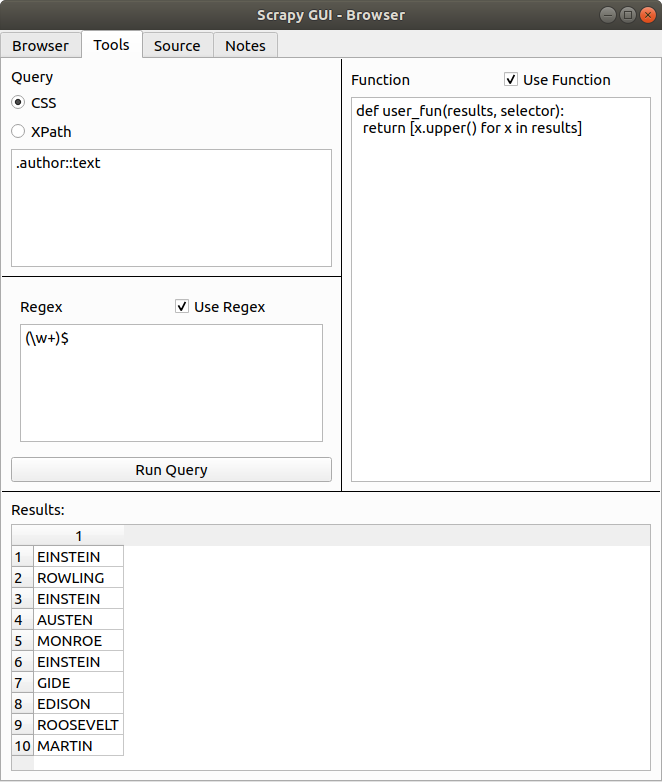
查询框
查询框允许您使用与parsel兼容的CSS和XPath查询从页面中提取数据。
它返回的结果就像调用了selection.css/xpath('YOUR QUERY').getall()。
如果没有结果或查询中存在错误,将弹出对话框通知您问题。
正则表达式框
此框允许您添加一个正则表达式模式,作为之前CSS查询的补充使用。
它返回的结果就像调用了selection.css/xpath('YOUR QUERY').re(r'YOUR REGEX')。这意味着如果您使用分组,它将只返回括号内的内容。
函数框
此框允许您定义可以运行在查询和正则表达式结果上的附加Python代码。代码可以像您想要的那么长和复杂,包括添加额外的函数、类、导入等。
唯一的要求是您必须包含一个名为user_fun(results, selector)的函数,该函数返回一个list。
结果框
此表将列出所有结果,如果已定义,将通过正则表达式和函数传递。
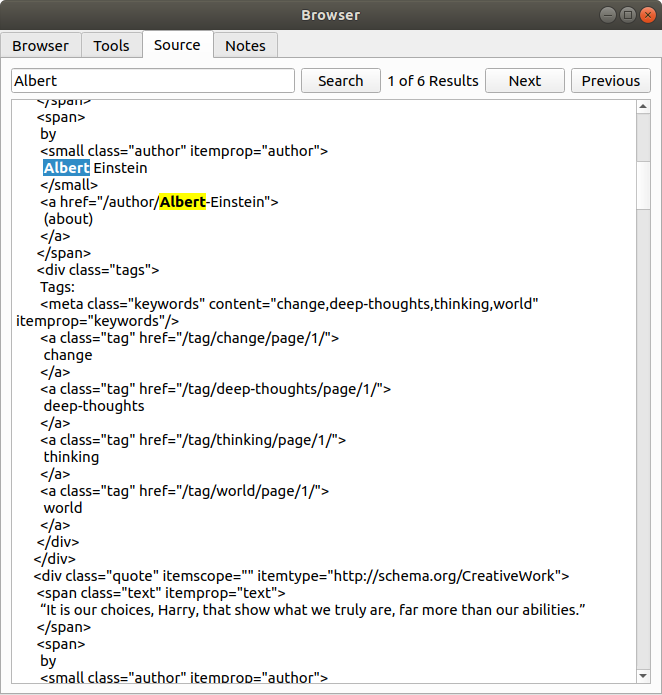
源标签
此选项卡包含用于工具选项卡的HTML源代码。您可以使用文本框搜索特定内容。所有搜索都不区分大小写。
笔记标签
这只是一个普通的文本框。退出应用时,其中的内容不会被保存。
与Scrapy Shell集成
可以将此工具与scrapy shell集成。这将允许您在通过中间件传递的响应上使用它,访问更复杂的请求和更具体的选择器。
激活
要在shell中使用它,请使用以下方式导入load_selector方法:
from scrapy_gui import load_selector
然后您可以编写load_selector(YOUR_SELECTOR)以打开一个包含加载了您的选择器的窗口。
例如,
load_selector(response)将您的响应加载到UI中。
当您运行代码时,将打开一个名为Scrapy GUI的窗口,其中包含上述独立窗口中的工具、源和笔记选项卡。


下载文件
下载您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。







