统计工具和实用程序


项目描述
scikit-stats: 统计工具和实用程序







安装
像安装其他Python包一样安装scikit-stats
pip install scikit-stats
或类似(如果您希望,请使用--user,virtualenv等)。
入门指南
scikit-stats模块包括建模和假设检验子模块。这是每个子模块的快速用户指南。通过binder示例也是入门的好方法。
建模
建模子模块包括贝叶斯块算法,该算法可用于改进直方图的分组。视觉改善可能非常显著,更重要的是,此算法生成的直方图可以准确表示底层分布,同时对统计波动具有鲁棒性。以下是算法在拉普拉斯采样数据上的一个简单示例,与该样本细分直方图进行了比较。
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> from skstats.modeling import bayesian_blocks
>>> data = np.random.laplace(size=10000)
>>> blocks = bayesian_blocks(data)
>>> plt.hist(data, bins=1000, label='Fine Binning', density=True, alpha=0.6)
>>> plt.hist(data, bins=blocks, label='Bayesian Blocks', histtype='step', density=True, linewidth=2)
>>> plt.legend(loc=2)
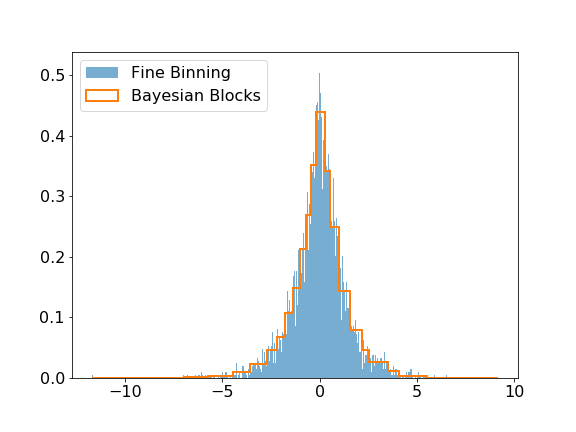
假设检验
此子模块提供进行假设检验的工具,例如发现检验和计算上限或置信区间。scikit-stats需要一个拟合后端来执行zfit的计算。如果它们的API与scikit-stats兼容,则可以使用任何拟合库(参见API检查)。
这里提供了一个简单的发现检验示例,使用zfit作为后端,在已知均值和标准差的高斯信号上,相对于指数背景。
>>> import zfit
>>> from zfit.loss import ExtendedUnbinnedNLL
>>> from zfit.minimize import Minuit
>>> bounds = (0.1, 3.0)
>>> obs = zfit.Space('x', limits=bounds)
>>> bkg = np.random.exponential(0.5, 300)
>>> peak = np.random.normal(1.2, 0.1, 25)
>>> data = np.concatenate((bkg, peak))
>>> data = data[(data > bounds[0]) & (data < bounds[1])]
>>> N = data.size
>>> data = zfit.Data.from_numpy(obs=obs, array=data)
>>> lambda_ = zfit.Parameter("lambda", -2.0, -4.0, -1.0)
>>> Nsig = zfit.Parameter("Ns", 20., -20., N)
>>> Nbkg = zfit.Parameter("Nbkg", N, 0., N*1.1)
>>> signal = Nsig * zfit.pdf.Gauss(obs=obs, mu=1.2, sigma=0.1)
>>> background = Nbkg * zfit.pdf.Exponential(obs=obs, lambda_=lambda_)
>>> loss = ExtendedUnbinnedNLL(model=signal + background, data=data)
>>> from skstats.hypotests.calculators import AsymptoticCalculator
>>> from skstats.hypotests import Discovery
>>> from skstats.hypotests.parameters import POI
>>> calculator = AsymptoticCalculator(loss, Minuit())
>>> poinull = POI(Nsig, 0)
>>> discovery_test = Discovery(calculator, [poinull])
>>> discovery_test.result()
p_value for the Null hypothesis = 0.0007571045424956679
Significance (in units of sigma) = 3.1719464825102244
发现检验会打印出p值和需要拒绝的零假设的显著性。


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源分布
scikit-stats-0.1.2.tar.gz (16.7 kB 查看哈希)
构建分布
scikit_stats-0.1.2-py2.py3-none-any.whl (24.6 kB 查看哈希)
关闭
scikit-stats-0.1.2.tar.gz的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | e38ca051873bcebfec88f7b329eb546862469ca08088ea4380a316d5cec6d25e |
|
| MD5 | e4528bd3c29a1d83b828ad37986dfa40 |
|
| BLAKE2b-256 | 4d22e4d823bfd16b44e6c4f7a42dde478d50c34d5c0507e1d185411a633c2d90 |
关闭
scikit_stats-0.1.2-py2.py3-none-any.whl的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | d31e1bf9f2f1f22054004be8e680a56695554ec732a51c056d4cc6513b2f7eed |
|
| MD5 | 4c2b3d8f04dfc506ca0aca400aa6e495 |
|
| BLAKE2b-256 | bed758aab05cec63439787c3e6b1cc458197382e83b7b709ac5baddb7d103c17 |







