随机投影森林,用于近似最近邻搜索。




项目描述
rpforest


rpforest是一个Python库,用于近似最近邻搜索:以快速但近似的方式查找高维空间中与给定查询点最近的点。
rpforest 与如annoy等替代性人工神经网络(ANN)包不同,因为它不需要存储模型中索引的所有向量。以这种方式使用,rpforest 用于生成候选的 ANNs 列表,供存储点向量的后续服务使用(例如,关系数据库)。
工作原理
它通过构建 N 个二进制随机投影树来工作。
在每个树中,训练点集递归地划分为越来越小的子集,直到达到最多 M 个点的叶节点。每个分区基于点与随机抽取的超平面的夹角的余弦值:角度小于中位数的点落在左分区,其余点落在右分区。
生成的树具有可预测的叶大小(不超过 M),并且由于中位数的分割而近似平衡,从而导致一致的树遍历时间。
查询模型是通过遍历每个树到查询点的叶节点来检索该树的 ANN 候选者,然后合并它们并按距离查询点排序来完成的。
安装
- 首先安装 numpy。
- 使用 pip 安装 rpforest:
pip install rpforest
用法
拟合
模型拟合很简单
from rpforest import RPForest
model = RPForest(leaf_size=50, no_trees=10)
model.fit(X)
速度-精度权衡由 leaf_size 和 no_trees 参数控制。增加 leaf_size 会导致模型生成较浅的树,具有较大的叶节点;增加 no_trees 会拟合更多的树。
内存查询
如果整个点集可以保留在内存中,rpforest 支持内存中的 ANN 查询。在拟合后,可以通过调用
nns = model.query(x_query, 10)
通过首先从 x 的叶节点检索候选近邻,然后合并它们并按与 x 的余弦相似度排序来返回向量 x 的最近邻。最多可以返回 no_trees * leaf_size 个 NN。
候选查询
rpforest 可以支持对大于可用内存的数据集进行索引和候选 ANN 查询。这是通过首先对数据集的子集进行模型拟合,然后对更大的数据集进行索引到拟合的模型来实现的。
from rpforest import RPForest
model = RPForest(leaf_size=50, no_trees=10)
model.fit(X_train)
model.clear() # Deletes X_train vectors
for point_id, x in get_x_vectors():
model.index(point_id, x)
nns = model.get_candidates(x_query, 10)
模型持久性
通过序列化和反序列化简单地实现模型持久性。
model = pickle.loads(pickle.dumps(model))
性能
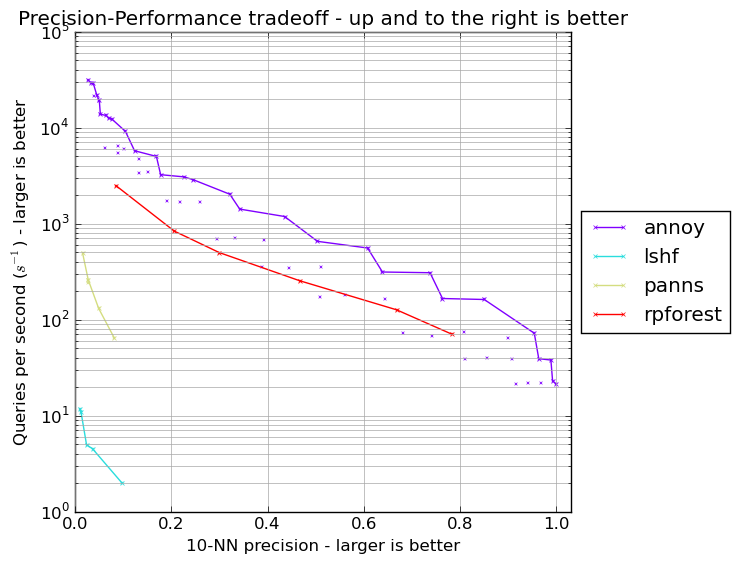
Erik Bernhardsson,annoy 的作者,维护了一个 ANN 性能竞赛 仓库,比较了多个 Python ANN 包。
在 GloVe 余弦距离基准测试中,rpforest 不如高度优化的 C 和 C++ 包如 FLANN 和 annoy 快。然而,它远优于 scikit-learn 的 LSHForest 和 panns。
开发
欢迎拉取请求。要安装用于开发
- 克隆 rpforest 仓库:
git clone git@github.com:lyst/rpforest.git - 使用 pip 开发安装它:
cd rpforest && pip install -e . - 您可以通过运行
python setupy.py test来运行测试。
当修改 .pyx 扩展文件时,您需要在运行 pip install -e . 之前运行 python setup.py cythonize 以生成扩展 .cpp 文件。


rpforest-1.6.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 4267d6728c9e7b6e01d9e196536facf2602388b2d0545dd849ab5ee33eff516e |
|
| MD5 | 5f7aacfbb32f4216a8f442818bbda80f |
|
| BLAKE2b-256 | 2c6ce481dbc2db5729aaca7d981f77d9387c6dfe9d66cbe76a085405496aaff7 |