Python Gellermann系列生成器

项目描述




PyGellerman:Python Gellermann系列生成器
这是Gellermann系列随机生成器的一个Python实现,适用于人类和非人类动物行为实验[^Gellermann1933]。它包括图形用户界面(GUI)以及简单的Python API。
Gellermann系列旨在通过排除与简单心理或行为模式相匹配的随机序列,避免夸大参与者的实验表现。更具体地说,Gellermann系列是一个满足五个标准的随机序列;长度为n的每个序列
- 必须包含相同数量的A和B(= n/2);
- 必须最多有3个A或B连续出现;
- 必须在第一个和最后一个半段中至少包含20%(= n/5)的A和B;
- 必须最多有n/2个反转(A-B或B-A转换);
- 当响应作为简单交替(ABAB...)或双重交替(AABBAA...和ABBAAB...)提供时,必须提供接近50%的正确响应率。
安装
PyGellermann可在PyPI上使用,可以使用pip安装
pip install pygellermann
有关如何使用pip的详细信息,请参阅Python打包用户指南或pip用户指南。
或者,您可以从发行页面下载GUI作为Linux、macOS和Windows的独立可执行文件。
注意:在 macOS 上,首次打开 PyGellermann 应用程序包可能会被阻止,因为它未签名或未通过 App Store 分发。要覆盖此限制并打开应用程序,请右键单击应用程序包,然后在上下文菜单中选择 打开。这将弹出一个对话框,要求您确认您要打开应用程序。之后,您可以通过双击它来打开应用程序。有关更多详细信息,请参阅 macOS 用户指南。
使用方法
图形用户界面
安装后,您可以通过在终端中输入 pygellermann-gui 或运行独立可执行文件(PyGellermann、PyGellermann.app 或 PyGellermann.exe)来运行 GUI。
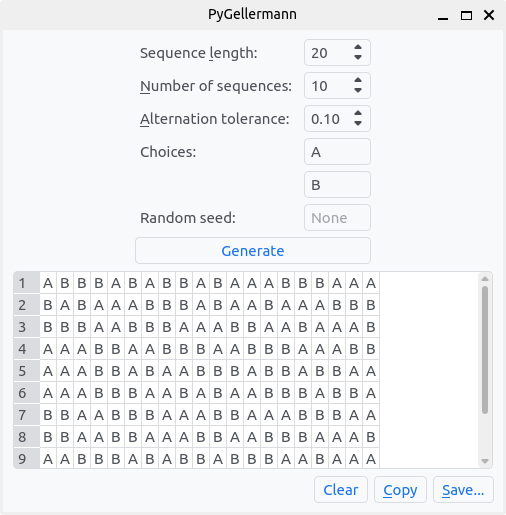
可以设置以下四个参数来自定义生成的 Gellermann 序列
- 序列长度:每个生成的序列的长度。
- 序列数量:要生成的序列数量。
- 交替容差:与单次或双次交替相比,序列需要达到多少接近 50% 的概率水平。
- 选择:序列中每个刺激的两个可能选择。
- 随机种子:随机数生成器的种子,允许确定性生成相同的序列。
然后,生成按钮将生成所需数量的序列,并在下方的表中显示它们。
最后,生成的 Gellermann 序列可以复制到剪贴板(复制)或保存到 CSV 文件(保存...)。
Python API
Python API 由 4 个简单函数组成
-
is_gellermann_series(s, alternation_tolerance=DEFAULT_ALTERNATION_TOLERANCE)检查一个二进制序列是否为 Gellermann 序列。
参数
-
s:Sequence[Any]一个偶数长度的二进制序列(即包含两个不同元素)。
-
alternation_tolerance:float,可选与单次或双次交替相比,围绕 50% 概率水平的容差值,一个介于 0 和 0.5 之间的值(默认:0.1)。
返回
-
bool如果给定的序列是 Gellermann 序列,则为 True,否则为 False。
引发
-
ValueError如果序列长度不是偶数,或者序列包含超过两个不同元素,或者交替容差不在 0 和 0.5 之间。
示例
>>> is_gellermann_series(['B', 'B', 'A', 'B', 'A', 'B', 'B', 'A', 'A', 'A']) True >>> is_gellermann_series('1112212122122211', alternation_tolerance=0.2) True >>> is_gellermann_series('1112212122122211', alternation_tolerance=0.0) False
-
-
generate_gellermann_series(n, m, choices=('A', 'B'), rng=None, **kwargs)生成 m 个长度为 n 的随机 Gellermann 序列。
参数
-
n:int系列的长度。
-
m:int要生成的系列数量。
-
choices:Tuple[Any, Any],可选系列的两个元素(默认:('A', 'B'))。
-
rng:np.random.Generator,可选一个 NumPy 随机数生成器(默认:
None,使用默认的 NumPy 随机数生成器)。 -
max_iterations:int,可选尝试生成所有 Gellermann 序列的最大迭代次数(默认:
None,无限尝试)。 -
kwargs传递给
is_gellermann_series的额外关键字参数。
产出
-
Iterator[Sequence[Any]]一个包含 m 个长度为 n 的 Gellermann 序列的生成器对象。
-
-
generate_all_gellermann_series(n, choices, **kwargs)按字典序生成长度为 n 的所有 Gellermann 序列。参数
-
n:int系列的长度。
-
choices:Tuple[Any, Any],可选系列的两个元素(默认:('A', 'B'))。
-
kwargs传递给
is_gellermann_series的额外关键字参数。
产出
-
Iterator[Sequence[Any]]一个包含长度为 n 的所有 Gellermann 序列的生成器对象。
-
-
generate_gellermann_series_table(n, m, long_format: bool = False, **kwargs)生成一个 Pandas DataFrame,其中包含 m 个长度为 n 的随机 Gellermann 序列。
在宽格式中,DataFrame有列'series_i','element_0','element_1',...,'element_{n-1}',并且每行包含一个完整的系列。在长格式中,DataFrame有列'series_i','element_i','element',并且每行包含一个系列的单一元素。
参数
-
n:int系列的长度。
-
m:int要生成的系列数量。
-
long_format:bool,可选如果为True,则DataFrame为长格式(默认:False)。
-
kwargs传递给
generate_gellermann_series的额外关键字参数。
返回
-
pd.DataFrame一个包含m个长度为n的随机Gellermann系列的Pandas DataFrame。
-
许可协议
PyGellermann在GNU通用公共许可证v3或更高版本下发布。有关详细信息,请参阅LICENSE文件。
PyGellermann是在荷兰尼姆egen的比较生物声学组的马克斯·普朗克心理语言学研究所开发的。
参考文献
[^Gellermann1933]: Gellermann, L. W. (1933). 视觉辨别实验中交替刺激的随机顺序。 遗传心理学杂志,42,206-208。

下载文件
下载您平台上的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源分发
构建分发
pygellermann-0.1.0.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 19b2e1562a617bde69fe13608bed2d83aa10c53909edca533833e4a5e63608f5 |
|
| MD5 | 12f7b83d04bb90e01fa088401e1eddd9 |
|
| BLAKE2b-256 | 4de3c23a6b691f1ec7a84831c95babebb4e38892781ebf5c92cfa8f3f8d00014 |
pygellermann-0.1.0-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | ff2dde10fb86d137f1eb2ade9125e5abb846fce159291ea7f92b01943e1233a9 |
|
| MD5 | b256e4cc7ee978fa1abca3800f210f9f |
|
| BLAKE2b-256 | 6c8e6006f26053569e1a7c7ec568a50a347b158d3b8d1a5e5d4662b5766e2e1a |