Druid的Python连接器。






项目描述
pydruid
pydruid提供了一个简单的API来创建、执行和分析Druid查询。pydruid可以将查询结果解析成Pandas DataFrame对象,以便进行后续数据分析——这为Druid、SciPy堆栈(用于科学计算)和scikit-learn(用于机器学习)提供了紧密集成。pydruid可以将查询结果导出到TSV或JSON,以便使用您喜欢的工具进一步处理,例如R、Julia、Matlab、Excel。它提供同步和异步客户端。
此外,pydruid实现了Python DB API 2.0、一个SQLAlchemy方言,并提供了一个命令行界面与Druid交互。
安装
pip install pydruid
# or, if you intend to use asynchronous client
pip install pydruid[async]
# or, if you intend to export query results into pandas
pip install pydruid[pandas]
# or, if you intend to do both
pip install pydruid[async, pandas]
# or, if you want to use the SQLAlchemy engine
pip install pydruid[sqlalchemy]
# or, if you want to use the CLI
pip install pydruid[cli]
文档:https://pythonhosted.org/pydruid/。
示例
以下示例展示了如何执行和分析三种类型查询的结果:时间序列、topN和groupby。我们将使用这些查询来对twitter的公共数据集提出简单问题。
时间序列
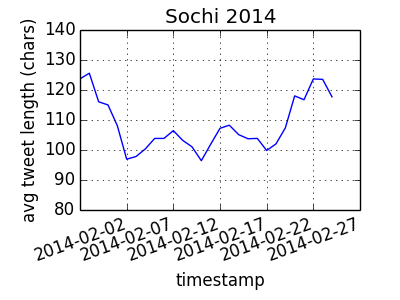
围绕2014年索契奥运会的平均推文长度每天是多少?
from pydruid.client import *
from pylab import plt
query = PyDruid(druid_url_goes_here, 'druid/v2')
ts = query.timeseries(
datasource='twitterstream',
granularity='day',
intervals='2014-02-02/p4w',
aggregations={'length': doublesum('tweet_length'), 'count': doublesum('count')},
post_aggregations={'avg_tweet_length': (Field('length') / Field('count'))},
filter=Dimension('first_hashtag') == 'sochi2014'
)
df = query.export_pandas()
df['timestamp'] = df['timestamp'].map(lambda x: x.split('T')[0])
df.plot(x='timestamp', y='avg_tweet_length', ylim=(80, 140), rot=20,
title='Sochi 2014')
plt.ylabel('avg tweet length (chars)')
plt.show()
topN
在2014年奥斯卡期间,哪些是前十位被提及的用户(@user_name)?
top = query.topn(
datasource='twitterstream',
granularity='all',
intervals='2014-03-03/p1d', # utc time of 2014 oscars
aggregations={'count': doublesum('count')},
dimension='user_mention_name',
filter=(Dimension('user_lang') == 'en') & (Dimension('first_hashtag') == 'oscars') &
(Dimension('user_time_zone') == 'Pacific Time (US & Canada)') &
~(Dimension('user_mention_name') == 'No Mention'),
metric='count',
threshold=10
)
df = query.export_pandas()
print df
count timestamp user_mention_name
0 1303 2014-03-03T00:00:00.000Z TheEllenShow
1 44 2014-03-03T00:00:00.000Z TheAcademy
2 21 2014-03-03T00:00:00.000Z MTV
3 21 2014-03-03T00:00:00.000Z peoplemag
4 17 2014-03-03T00:00:00.000Z THR
5 16 2014-03-03T00:00:00.000Z ItsQueenElsa
6 16 2014-03-03T00:00:00.000Z eonline
7 15 2014-03-03T00:00:00.000Z PerezHilton
8 14 2014-03-03T00:00:00.000Z realjohngreen
9 12 2014-03-03T00:00:00.000Z KevinSpacey
groupby
用户回复其他用户的社交网络是什么样的?
from igraph import *
from cairo import *
from pandas import concat
group = query.groupby(
datasource='twitterstream',
granularity='hour',
intervals='2013-10-04/pt12h',
dimensions=["user_name", "reply_to_name"],
filter=(~(Dimension("reply_to_name") == "Not A Reply")) &
(Dimension("user_location") == "California"),
aggregations={"count": doublesum("count")}
)
df = query.export_pandas()
# map names to categorical variables with a lookup table
names = concat([df['user_name'], df['reply_to_name']]).unique()
nameLookup = dict([pair[::-1] for pair in enumerate(names)])
df['user_name_lookup'] = df['user_name'].map(nameLookup.get)
df['reply_to_name_lookup'] = df['reply_to_name'].map(nameLookup.get)
# create the graph with igraph
g = Graph(len(names), directed=False)
vertices = zip(df['user_name_lookup'], df['reply_to_name_lookup'])
g.vs["name"] = names
g.add_edges(vertices)
layout = g.layout_fruchterman_reingold()
plot(g, "tweets.png", layout=layout, vertex_size=2, bbox=(400, 400), margin=25, edge_width=1, vertex_color="blue")

异步客户端
pydruid.async_client.AsyncPyDruid实现了一个异步客户端。为此,它利用了来自Tornado框架的异步HTTP客户端。异步客户端适用于与Tornado等异步框架一起使用,并提供了在规模上更好的性能。它允许您同时处理多个请求,而不会在Druid执行您的查询时阻塞。
示例
from tornado import gen
from pydruid.async_client import AsyncPyDruid
from pydruid.utils.aggregators import longsum
from pydruid.utils.filters import Dimension
client = AsyncPyDruid(url_to_druid_broker, 'druid/v2')
@gen.coroutine
def your_asynchronous_method_serving_top10_mentions_for_day(day
top_mentions = yield client.topn(
datasource='twitterstream',
granularity='all',
intervals="%s/p1d" % (day, ),
aggregations={'count': doublesum('count')},
dimension='user_mention_name',
filter=(Dimension('user_lang') == 'en') & (Dimension('first_hashtag') == 'oscars') &
(Dimension('user_time_zone') == 'Pacific Time (US & Canada)') &
~(Dimension('user_mention_name') == 'No Mention'),
metric='count',
threshold=10)
# asynchronously return results
# can be simply ```return top_mentions``` in python 3.x
raise gen.Return(top_mentions)
thetaSketches
Theta sketch后聚合器与正常的Post Aggregators构建略有不同,因为它们有不同的运算符。注意:您必须将druid-datasketches扩展加载到您的Druid集群中,才能使用这些功能。有关详细信息,请参阅Druid datasketches文档。
from pydruid.client import *
from pydruid.utils import aggregators
from pydruid.utils import filters
from pydruid.utils import postaggregator
query = PyDruid(url_to_druid_broker, 'druid/v2')
ts = query.groupby(
datasource='test_datasource',
granularity='all',
intervals='2016-09-01/P1M',
filter = ( filters.Dimension('product').in_(['product_A', 'product_B'])),
aggregations={
'product_A_users': aggregators.filtered(
filters.Dimension('product') == 'product_A',
aggregators.thetasketch('user_id')
),
'product_B_users': aggregators.filtered(
filters.Dimension('product') == 'product_B',
aggregators.thetasketch('user_id')
)
},
post_aggregations={
'both_A_and_B': postaggregator.ThetaSketchEstimate(
postaggregator.ThetaSketch('product_A_users') & postaggregator.ThetaSketch('product_B_users')
)
}
)
DB API
from pydruid.db import connect
conn = connect(host='localhost', port=8082, path='/druid/v2/sql/', scheme='http')
curs = conn.cursor()
curs.execute("""
SELECT place,
CAST(REGEXP_EXTRACT(place, '(.*),', 1) AS FLOAT) AS lat,
CAST(REGEXP_EXTRACT(place, ',(.*)', 1) AS FLOAT) AS lon
FROM places
LIMIT 10
""")
for row in curs:
print(row)
SQLAlchemy
from sqlalchemy import *
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import *
engine = create_engine('druid://:8082/druid/v2/sql/') # uses HTTP by default :(
# engine = create_engine('druid+https://:8082/druid/v2/sql/')
# engine = create_engine('druid+https://:8082/druid/v2/sql/')
places = Table('places', MetaData(bind=engine), autoload=True)
print(select([func.count('*')], from_obj=places).scalar())
列标题
在版本0.13.0中,Druid SQL添加了对包含列名在响应中的支持,这可以通过请求中的"header"字段来请求。这有助于确保光标描述已定义(这是SQLAlchemy查询语句的要求),无论结果集是否包含任何行。历史上,这对于不包含任何行的结果集是问题,因为无法推断出预期的列名。
可以通过使用查询参数通过SQLAlchemy URI来配置启用标题,即
engine = create_engine('druid://:8082/druid/v2/sql?header=true')
请注意,当前默认值为false以确保向后兼容,但对于Druid版本&大于;= 0.13.0,应将其设置为true。
命令行
$ pydruid https://:8082/druid/v2/sql/
> SELECT COUNT(*) AS cnt FROM places
cnt
-----
12345
> SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES;
TABLE_NAME
----------
test_table
COLUMNS
SCHEMATA
TABLES
> BYE;
GoodBye!
贡献
当然欢迎贡献。我们喜欢使用black和flake8。
pip install -r requirements-dev.txt # installs useful dev deps
pre-commit install # installs useful commit hooks


pydruid-0.6.9.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 63c41b33ab47fbb71cc25d3f3316cad78f18bfe947fa108862dd841d1f44fe49 |
|
| MD5 | b3929bea4d4871eb1db5e3bb00f0369f |
|
| BLAKE2b-256 | e9452f64d8c14b487274e825d793dc634f9f1040537aa6cb93d1ea8fc4498d65 |