Pipeline Profiler工具。使Jupyter Notebooks能够探索D3M流水线


项目描述
PipelineProfiler
兼容Jupyter Notebooks的AutoML流水线探索工具。支持auto-sklearn和D3M流水线格式。

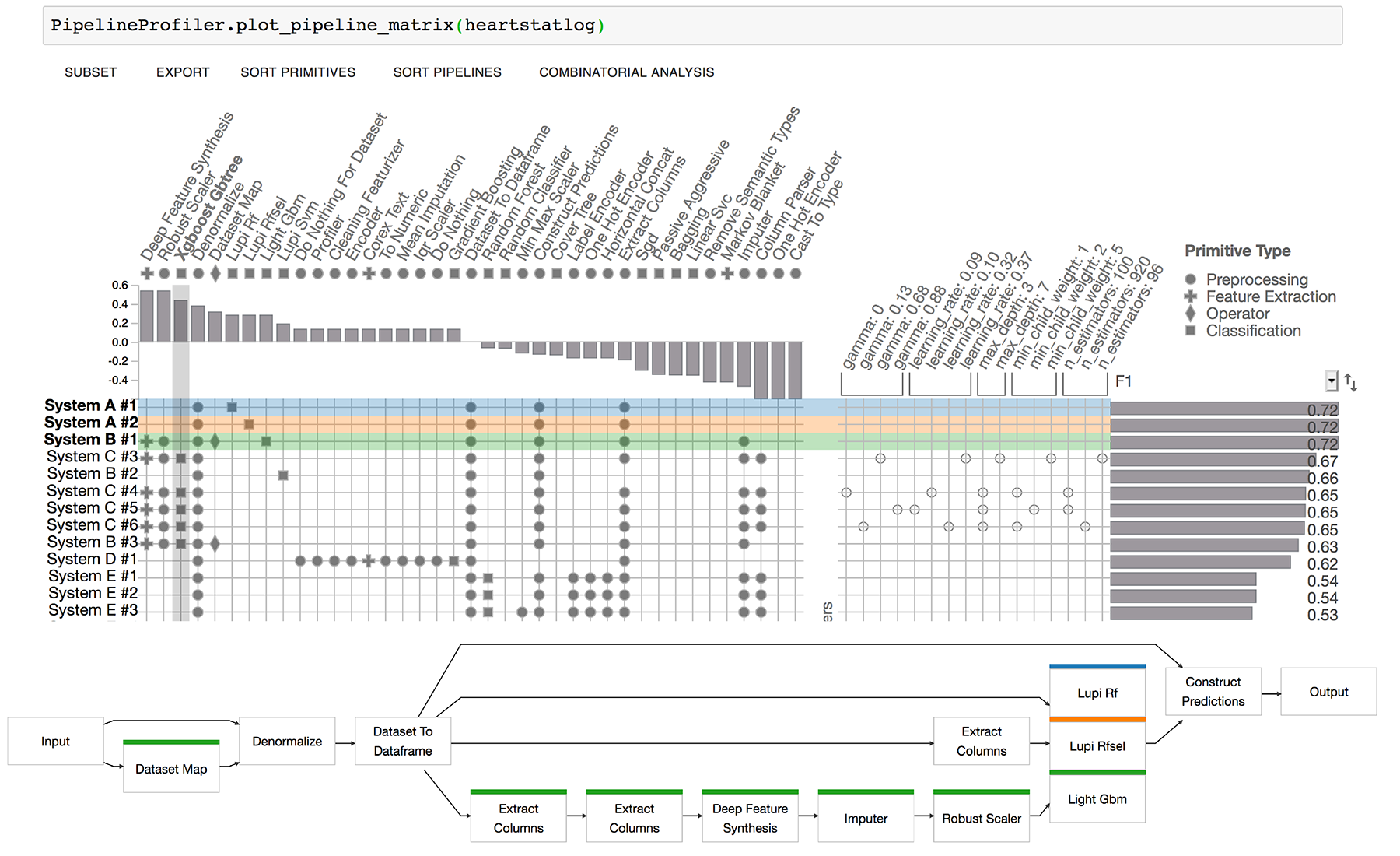
(按住Shift键单击以选择多个流水线)
论文: https://arxiv.org/abs/2005.00160
视频: https://youtu.be/2WSYoaxLLJ8
博客: Medium帖子
演示
实时演示(Google Colab)
在Jupyter Notebook中
import PipelineProfiler
data = PipelineProfiler.get_heartstatlog_data()
PipelineProfiler.plot_pipeline_matrix(data)
安装
选项1:通过pip安装
pip install pipelineprofiler
选项2:运行docker镜像
docker build -t pipelineprofiler .
docker run -p 9999:8888 pipelineprofiler
然后复制访问令牌并在浏览器URL中登录jupyter
localhost:9999
数据预处理
PipelineProfiler从D3M元学习数据库读取数据。您可以从以下位置下载此数据: https://metalearning.datadrivendiscovery.org/dumps/2020/03/04/metalearningdb_dump_20200304.tar.gz
您需要合并两个文件以探索流水线:pipelines.json和pipeline_runs.json。为此,请运行
python -m PipelineProfiler.pipeline_merge [-n NUMBER_PIPELINES] pipeline_runs_file pipelines_file output_file
流水线探索
import PipelineProfiler
import json
在Jupyter Notebook中,加载output_file
with open("output_file.json", "r") as f:
pipelines = json.load(f)
然后使用
PipelineProfiler.plot_pipeline_matrix(pipelines[:10])
数据后处理
您可能希望按问题类型分组管道,并从每个团队中选择前k个管道。为此,请使用以下代码:
def get_top_k_pipelines_team(pipelines, k):
team_pipelines = defaultdict(list)
for pipeline in pipelines:
source = pipeline['pipeline_source']['name']
team_pipelines[source].append(pipeline)
for team in team_pipelines.keys():
team_pipelines[team] = sorted(team_pipelines[team], key=lambda x: x['scores'][0]['normalized'], reverse=True)
team_pipelines[team] = team_pipelines[team][:k]
new_pipelines = []
for team in team_pipelines.keys():
new_pipelines.extend(team_pipelines[team])
return new_pipelines
def sort_pipeline_scores(pipelines):
return sorted(pipelines, key=lambda x: x['scores'][0]['value'], reverse=True)
pipelines_problem = {}
for pipeline in pipelines:
problem_id = pipeline['problem']['id']
if problem_id not in pipelines_problem:
pipelines_problem[problem_id] = []
pipelines_problem[problem_id].append(pipeline)
for problem in pipelines_problem.keys():
pipelines_problem[problem] = sort_pipeline_scores(get_top_k_pipelines_team(pipelines_problem[problem], k=100))


下载文件
下载您平台上的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源分布
pipelineprofiler-0.1.18.tar.gz (871.9 kB 查看哈希值)
构建分布
pipelineprofiler-0.1.18-py3-none-any.whl (881.1 kB 查看哈希值)







