一个用于定义、管理和执行函数管道的Python库。

项目描述
PipeFunc:结构化、自动化和简化您的计算工作流程 🕸
🚫 停止微观管理执行。专注于科学。使用函数管道捕获您工作流程的本质,将计算表示为DAG 🕸️,并自动化并行扫描 🔄。










:books: 目录
- :thinking: 这是关于什么?
- :rocket: 关键功能
- :test_tube: 它是如何工作的?
- :notebook: Jupyter Notebook示例
- :computer: 安装
- :hammer_and_wrench: 开发
:thinking: 这是关于什么?

pipefunc 是一个用于创建和执行 函数管道 的 Python 库。通过简单注释函数并指定它们的输出,它可以构建一个管道,根据依赖关系自动管理执行顺序。将管道视为有向图,执行所有(或特定)输出,添加多维扫描,自动并行化管道,并获得结构化的数据。
[!注意] 管道 是一系列相互连接的函数,以 有向无环图 (DAG) 的形式组织,其中一个或多个函数的输出作为后续函数的输入。pipefunc 简化了这些管道的创建和管理,提供了强大的工具以高效地执行它们。
无论您是在处理数据处理、科学计算、机器学习(AI)工作流程,还是任何涉及相互依赖函数的其他场景,pipefunc 都可以帮助您专注于代码的逻辑,同时它处理函数的依赖关系和执行顺序的复杂性。
:rocket: 关键功能
- 🚀 函数组合和管道化:使用
@pipefunc装饰器创建管道;执行顺序自动处理。 - 📊 管道可视化:生成管道的可视化图形,以更好地理解数据流。
- 👥 多个输出:处理返回多个结果的函数,允许每个结果作为其他函数的输入。
- 🔁 Map-Reduce 支持:执行“map”操作将函数应用于数据,以及“reduce”操作聚合结果,允许多维映射。
- ➡️ 管道简化:合并复杂管道中的节点,以在单个步骤中运行多个函数。
- 👮 类型注解验证:验证函数之间的类型注解以确保类型一致性。
- 🎛️ 资源使用分析:获取有关 CPU 使用、内存消耗和执行时间的报告,以识别瓶颈并优化您的代码。
- 🔄 自动并行化:自动以并行(本地或远程)方式运行管道,具有共享内存和磁盘缓存选项。
- 🔍 参数扫描工具:生成参数组合用于参数扫描,并通过结果缓存优化扫描。
- 💡 灵活的函数参数:使用不同的参数组合调用函数,让
pipefunc根据提供的参数确定调用哪些其他函数。 - 🏗️ 利用巨人:基于 NetworkX 进行图算法,NumPy 进行多维数组,可选 Xarray 进行标记的多维数组,Zarr 存储结果在内存/磁盘/云或任何键值存储中,以及 Adaptive 进行并行扫描。
- 🤓 内行数据:>600 个测试,100% 测试覆盖率,完全类型化,仅 4 个必需依赖项,所有 Ruff 规则,所有 公共 API 已文档化。
:test_tube: 它是如何工作的?
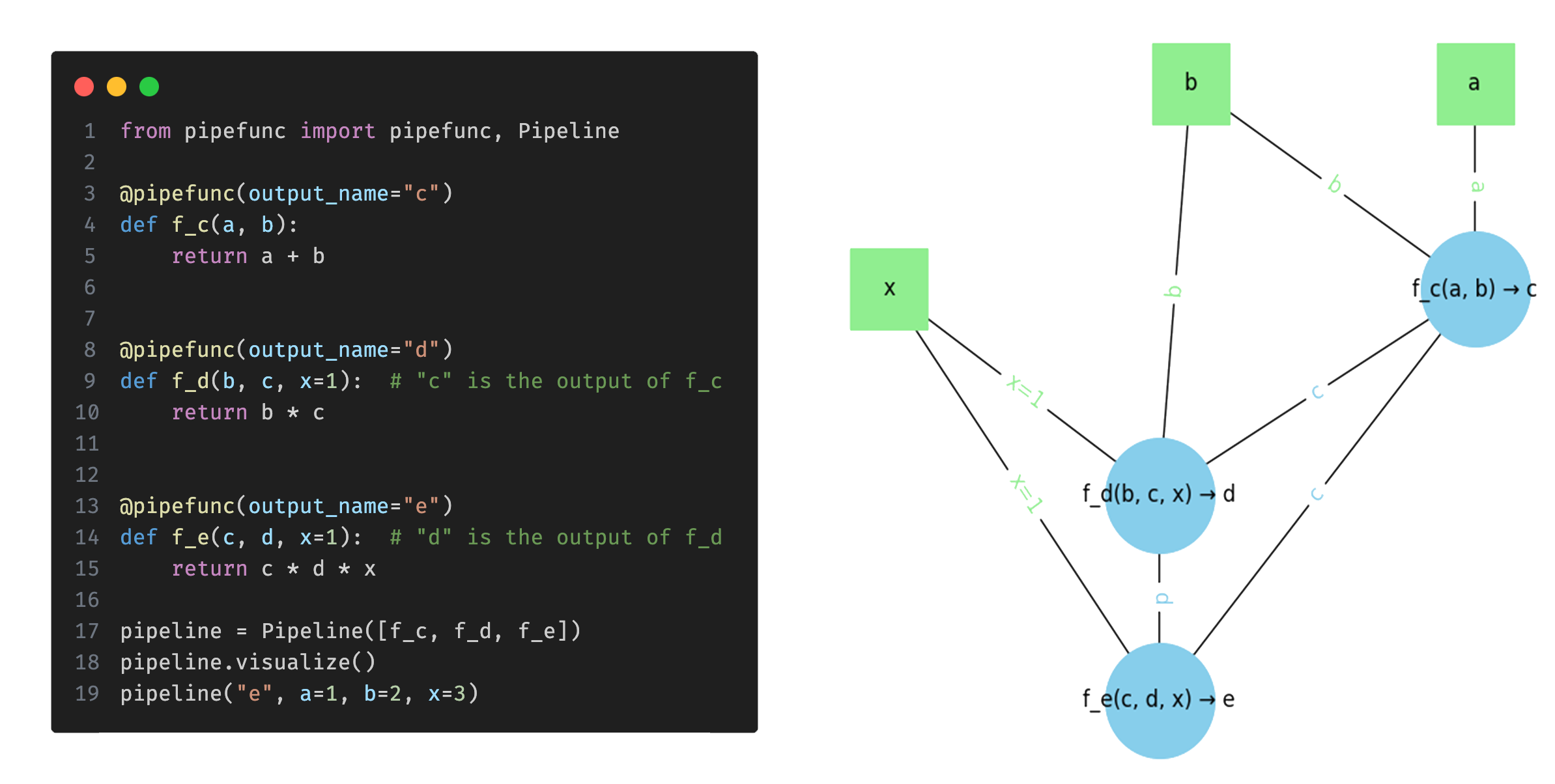
pipefunc 提供了一个 Pipeline 类,您可以使用它来定义您的函数管道。您可以使用 pipefunc 装饰器将函数添加到管道中,这还允许您指定函数的输出名称。一旦定义了管道,您就可以针对特定输出值执行它,通过合并函数节点简化它,将其可视化为有向图,并分析管道函数的资源使用情况。有关更详细的用法说明和示例,请参阅包中提供的用法示例。
以下是一个 pipefunc 的简单示例用法,用于说明其主要功能
from pipefunc import pipefunc, Pipeline
# Define three functions that will be a part of the pipeline
@pipefunc(output_name="c")
def f_c(a, b):
return a + b
@pipefunc(output_name="d")
def f_d(b, c):
return b * c
@pipefunc(output_name="e")
def f_e(c, d, x=1):
return c * d * x
# Create a pipeline with these functions
pipeline = Pipeline([f_c, f_d, f_e], profile=True) # `profile=True` enables resource profiling
# Call the pipeline directly for different outputs:
assert pipeline("d", a=2, b=3) == 15
assert pipeline("e", a=2, b=3, x=1) == 75
# Or create a new function for a specific output
h_d = pipeline.func("d")
assert h_d(a=2, b=3) == 15
h_e = pipeline.func("e")
assert h_e(a=2, b=3, x=1) == 75
# Instead of providing the root arguments, you can also provide the intermediate results directly
assert h_e(c=5, d=15, x=1) == 75
# Visualize the pipeline
pipeline.visualize()
# Get all possible argument mappings for each function
all_args = pipeline.all_arg_combinations
print(all_args)
# Show resource reporting (only works if profile=True)
pipeline.print_profiling_stats()
此示例演示了使用 f_c、f_d、f_e 函数定义管道,使用管道访问和执行这些函数,可视化管道图,获取所有可能的参数映射,并报告资源使用情况。这个基本示例应该能给您一个关于如何使用 pipefunc 构建和管理函数管道的思路。
以下示例演示了如何使用 pipefunc 执行 map-reduce 操作。
from pipefunc import pipefunc, Pipeline
from pipefunc.map import load_outputs
import numpy as np
@pipefunc(output_name="c", mapspec="a[i], b[j] -> c[i, j]") # the mapspec is used to specify the mapping
def f(a: int, b: int):
return a + b
@pipefunc(output_name="mean") # there is no mapspec, so this function takes the full 2D array
def g(c: np.ndarray):
return np.mean(c)
pipeline = Pipeline([f, g])
inputs = {"a": [1, 2, 3], "b": [4, 5, 6]}
pipeline.map(inputs, run_folder="my_run_folder", parallel=True)
result = load_outputs("mean", run_folder="my_run_folder")
print(result) # prints 7.0
在这里,mapspec 参数用于指定函数 f 的输入和输出之间的映射,它创建了输入列表 a 和 b 的乘积,并计算每对数字的和。然后,g 函数计算结果二维数组的平均值。map 方法对 inputs 执行管道,而 load_outputs 函数用于从指定的运行文件夹中加载 g 函数的结果。
:notebook: Jupyter Notebook示例
请参阅我们的 example.ipynb 中的详细用法示例和其他内容。
:computer: 安装
建议从 conda 安装 最新稳定版(推荐)
conda install pipefunc
或从 PyPI 安装
pip install "pipefunc[all]"
或使用以下命令安装 main
pip install -U https://github.com/pipefunc/pipefunc/archive/main.zip
或克隆存储库并执行开发安装(推荐用于开发)
git clone git@github.com:pipefunc/pipefunc.git
cd pipefunc
pip install -e ".[dev]"
:hammer_and_wrench: 开发
我们使用 pre-commit 来管理预提交钩子,这有助于我们确保我们的代码始终干净并符合我们的编码标准。要设置它,请使用 pip 安装 pre-commit,然后运行安装命令
pip install pre-commit
pre-commit install


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解有关 安装包 的更多信息。







