可扩展的开源分析堆栈Pandata

项目描述
Pandata:可扩展的开源分析堆栈
Pandata是一个完全开源、高性能、现代Python数据分析堆栈,适用于任何科学、工程或分析领域。
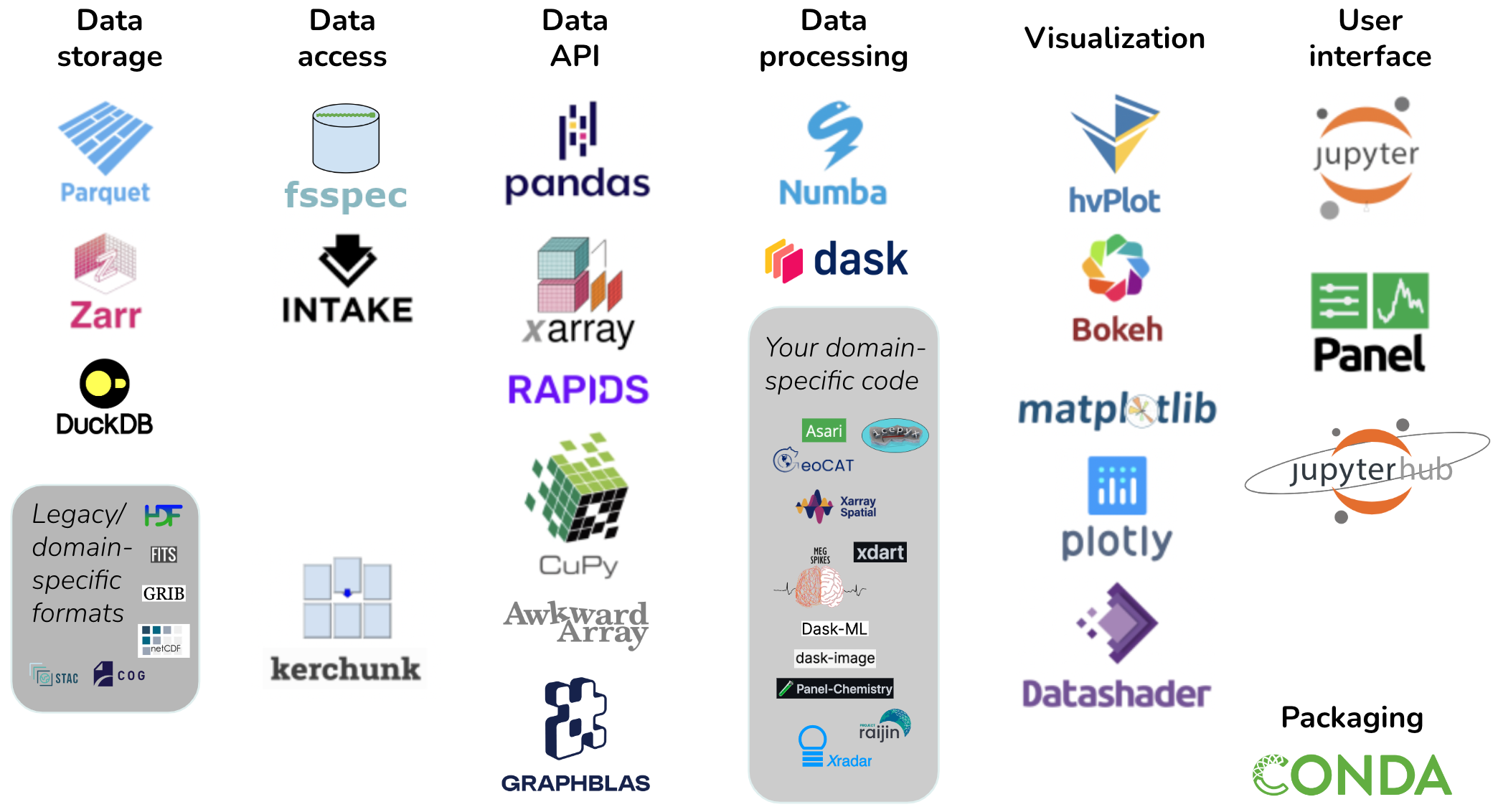
您是否受限于您领域软件堆栈的限制?
每个科学或工程学科都有自己的计算需求。许多这样的学科已经为以下目的开发了完全独立的工具集:
- 存储数据
- 读取数据
- 处理数据
- 绘制数据
- 分析数据
- 建模数据
- 探索数据
这些堆栈在很大程度上与过时的架构和假设有关
- 不友好于云或远程:绑定到本地桌面GUI或操作系统
- 不可扩展:绑定到单个处理器(CPU),无论是出于技术原因还是许可原因
- 非通用:受众狭窄,维护者少,且该领域之外的人未知
这些都是数据——是时候找到更好的方法了!
Pandata:可扩展的开源分析堆栈
与其使用过时的堆栈,不如使用现代Python数据科学工具,这些工具是
- 领域无关:由世界各地许多人维护、使用和测试
- 高效的:使用矢量化数据或即时编译以机器码速度运行
- 可扩展的:从单核笔记本电脑到千节点集群均可运行
- 云友好:适用于本地或远程计算,并使用任何文件存储系统上的数据
- 多架构:在您的桌面以及Mac/Windows/Linux CPU和GPU上运行
- 可脚本化的:用于参数搜索和无监督操作,以批处理模式运行
- 可组合的:选择您需要的工具,并将它们组合起来解决问题
- 可可视化的:支持渲染甚至最大的数据集,无需转换或近似
- 交互式的:支持完全交互式探索,而不仅仅是渲染静态图像或文本文件
- 可分享:可作为网络应用程序部署,任何人任何地方都可以使用
- 开源软件(OSS):免费、开源,可用于研究或商业用途,不受限制性许可的约束
但是你说你不做数据科学?你确实在做!数据科学是众多学科之间共享的,不仅仅是为了人工智能和机器学习(尽管它也很好地支持这些!)
什么是 Pandata,为什么我需要它?
Pandata 只是一个名称,指的是由不同人员分别维护的特定集合的 Python 库。Pandata 库旨在相互协作,实现上述目标(可扩展性、交互性等)。除了知道哪些库设计得可以很好地一起工作之外,你不需要 Pandata 做任何事情。只需使用 Pandata 中的任何库,并为此感到高兴,知道如果你需要其他库覆盖的功能,你可以将它们一起使用,而不会危及可扩展性、交互性等。
谁运营 Pandata?
Pandata 只是由一些 Pandata 工具的作者建立的信息网站;没有专门与 Pandata 相关的管理、政策或软件开发。但是,如果你对 Pandata 的用途有任何问题或想法,请随时为讨论打开一个问题!
示例
网上有很多将 Pandata 库应用于解决问题的示例,包括
- Pangeo:JupyterHub、Dask、Xarray 用于气候科学;Pandata 是 Pangeo,但适用于任何领域!
- Project Pythia:地球科学特定示例,其中许多示例使用 Pandata 工具
- Attractors:使用 Numba 处理大量数据集,使用 Datashader 渲染
- Census:从 Parquet 读取分块数据,使用 Dask + Datashader 渲染
- Ship traffic:使用交互式查找渲染空间索引数据
- Landsat:Intake 数据目录,xarray n-D 数据,hvPlot+Bokeh 绘图,Dask ML
- Minian:Jupyter、Dask 和 HoloViews 用于神经科学
有关所有详细信息,请参阅 SciPy 2023 的 Pandata 论文,然后下载并使用 Pandata 中的任何包,以任何组合方式使用,享受所有这些功能尽在指尖!
