通过大规模弱监督实现鲁棒的语音识别

项目描述
Whisper
Whisper是一个通用的语音识别模型。它在大量不同音频数据集上训练,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
方法
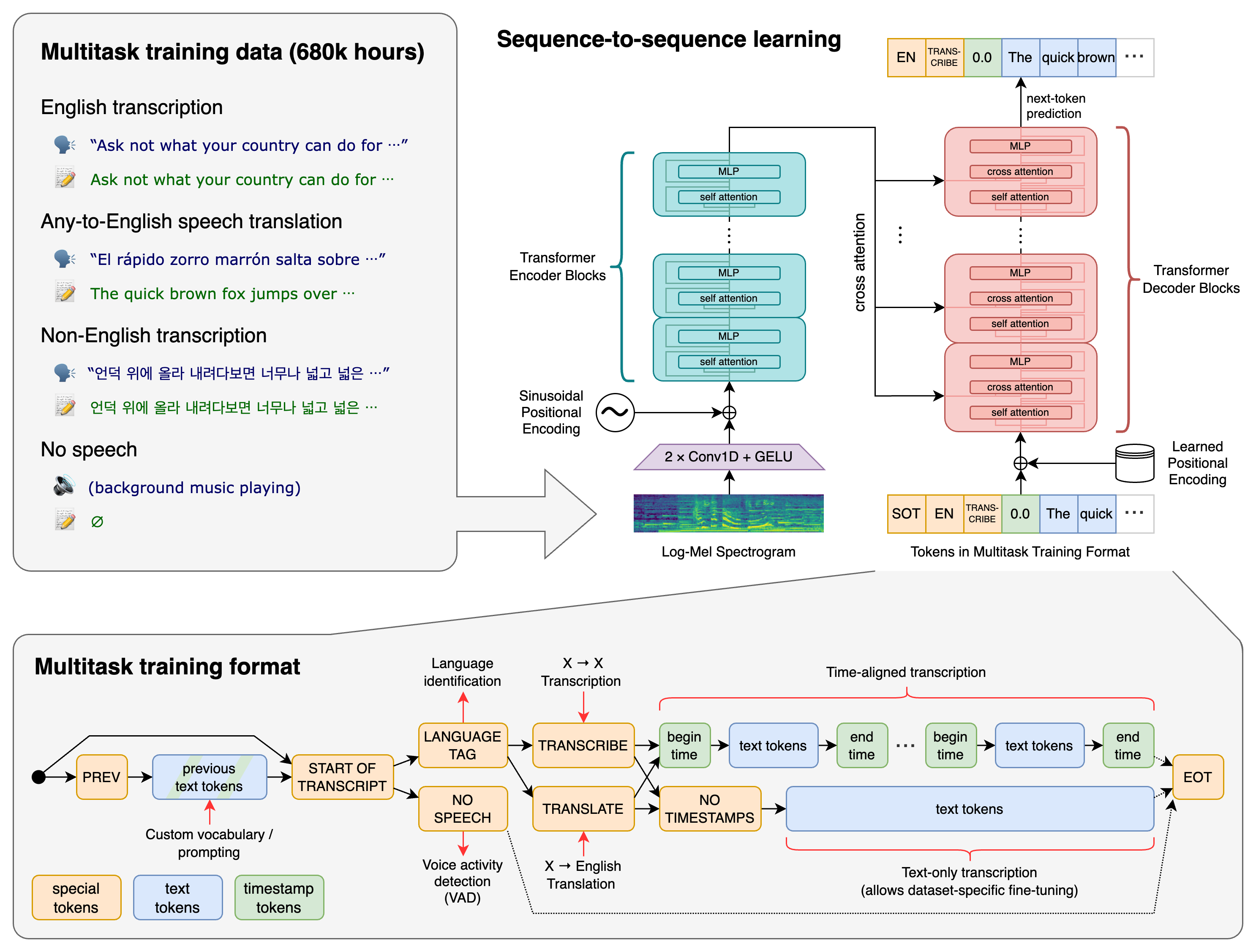
在多语言语音识别、语音翻译、口语语言识别和语音活动检测等语音处理任务上训练了一个Transformer序列到序列模型。这些任务共同表示为一个由解码器预测的标记序列,允许单个模型替换传统语音处理管道的许多阶段。多任务训练格式使用一组特殊标记,作为任务指定符或分类目标。
设置
我们使用了Python 3.9.9和PyTorch 1.10.1来训练和测试我们的模型,但预期代码库与Python 3.8-3.11和最新的PyTorch版本兼容。代码库还依赖于一些Python包,最著名的是OpenAI的tiktoken,用于它们的快速标记化实现。您可以使用以下命令下载和安装Whisper的最新版本:
pip install -U openai-whisper
或者,以下命令将拉取并安装此存储库的最新提交及其Python依赖项:
pip install git+https://github.com/openai/whisper.git
要更新此存储库的包到最新版本,请运行:
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
它还需要在您的系统上安装命令行工具ffmpeg,大多数包管理器都提供此工具。
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh.cn/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
您可能还需要安装rust,以防tiktoken无法为您的平台提供预构建的wheel。如果在上述pip install命令期间出现安装错误,请根据入门页面安装Rust开发环境。此外,您可能需要配置PATH环境变量,例如export PATH="$HOME/.cargo/bin:$PATH"。如果安装失败并显示No module named 'setuptools_rust',则需要安装setuptools_rust,例如通过运行
pip install setuptools-rust
可用模型和语言
共有六种模型大小,其中四种只有英语版本,提供了速度和准确率的权衡。以下是可用模型的名称以及相对于大型模型的近似内存需求和推理速度。以下相对速度是通过在A100上转录英语语音测量的,实际速度可能会因许多因素(包括语言、说话速度和可用硬件)而显著变化。
| 大小 | 参数 | 仅英语模型 | 多语言模型 | 所需VRAM | 相对速度 |
|---|---|---|---|---|---|
| 小型 | 39 M | tiny.en |
小型 |
~1 GB | ~10x |
| 基础 | 74 M | base.en |
基础 |
~1 GB | ~7x |
| 小型 | 244 M | small.en |
小型 |
~2 GB | ~4x |
| 中型 | 769 M | medium.en |
中型 |
~5 GB | ~2x |
| 大型 | 1550 M | N/A | 大型 |
~10 GB | 1x |
| 涡轮 | 809 M | N/A | 涡轮 |
~6 GB | ~8x |
针对仅英语应用的.en模型通常表现更好,尤其是对于tiny.en和base.en模型。我们观察到,对于small.en和medium.en模型,差异变得不那么显著。此外,turbo模型是large-v3的优化版本,在最小程度降低准确率的同时提供更快的转录速度。
Whisper的性能会因语言而异。以下图表显示了使用Common Voice 15和Fleurs数据集评估的WER(单词错误率)或CER(字符错误率,以斜体显示)来按语言对large-v3和large-v2模型进行性能分解。其他模型和数据集的相应WER/CER度量可以在该论文的附录D.1、D.2和D.4中找到,以及翻译的BLEU(双语评估助手)得分在附录D.3中。

命令行用法
以下命令将使用turbo模型转录音频文件中的语音
whisper audio.flac audio.mp3 audio.wav --model turbo
默认设置(选择small模型)对于转录英语效果良好。要转录包含非英语语音的音频文件,您可以使用--language选项指定语言
whisper japanese.wav --language Japanese
添加--task translate将语音翻译成英语
whisper japanese.wav --language Japanese --task translate
运行以下命令以查看所有可用选项
whisper --help
有关所有可用语言的列表,请参阅tokenizer.py
Python用法
转录也可以在Python中进行
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])
内部,transcribe()方法读取整个文件,并使用滑动30秒窗口处理音频,在每个窗口上进行自回归序列到序列预测。
以下是使用whisper.detect_language()和whisper.decode()的示例用法,它们提供了对模型的低级别访问。
import whisper
model = whisper.load_model("turbo")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
更多示例
请使用讨论区中的🙌 Show and tell类别分享更多Whisper和第三方扩展(如网络演示、与其他工具的集成、不同平台的移植等)的示例用法。
许可证
Whisper的代码和模型权重在MIT许可证下发布。有关详细信息,请参阅LICENSE


openai-whisper-20240930.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | b7178e9c1615576807a300024f4daa6353f7e1a815dac5e38c33f1ef055dd2d2 |
|
| MD5 | aab53b4c78af150af9a071f55472b7ca |
|
| BLAKE2b-256 | f577952ca71515f81919bd8a6a4a3f89a27b09e73880cebf90957eda8f2f8545 |