轻松构建反应式后端

项目描述
onto



"boiler": Backend-Originated Instantly-Loaded Entity Repository
注意:此包未进行性能分析或内存使用检查。建议使用Kubernetes来提高容错能力。
Flask-boiler使用Firestore管理您的应用程序状态。您可以创建聚合底层数据源的观点模型,并将它们立即永久地存储在Firestore中。因此,您的前端开发将像使用Firestore一样简单。Flask-boiler类似于Spring Web Reactive。
演示
当您更改会议中某位参与者的出席状态时,所有其他参与者将收到会议出席人员名单的更新版本。
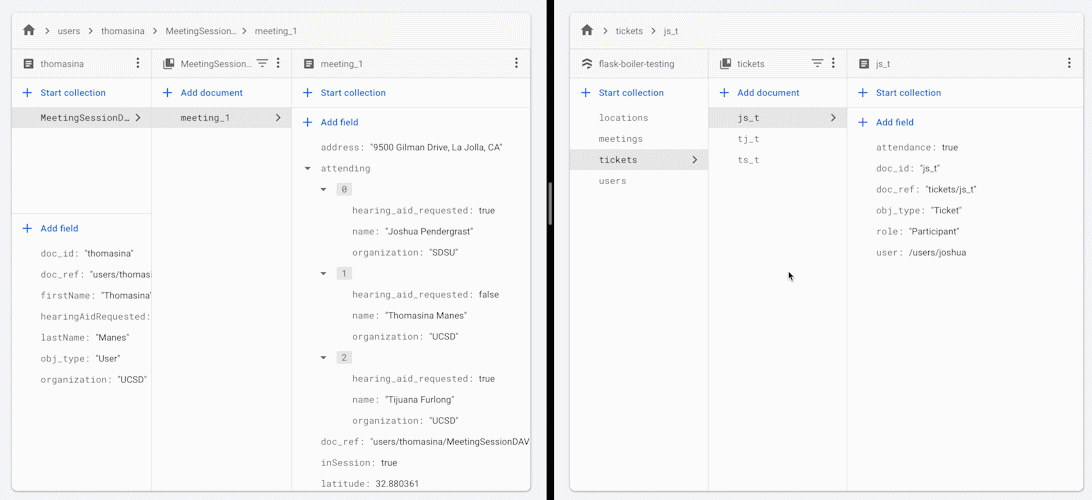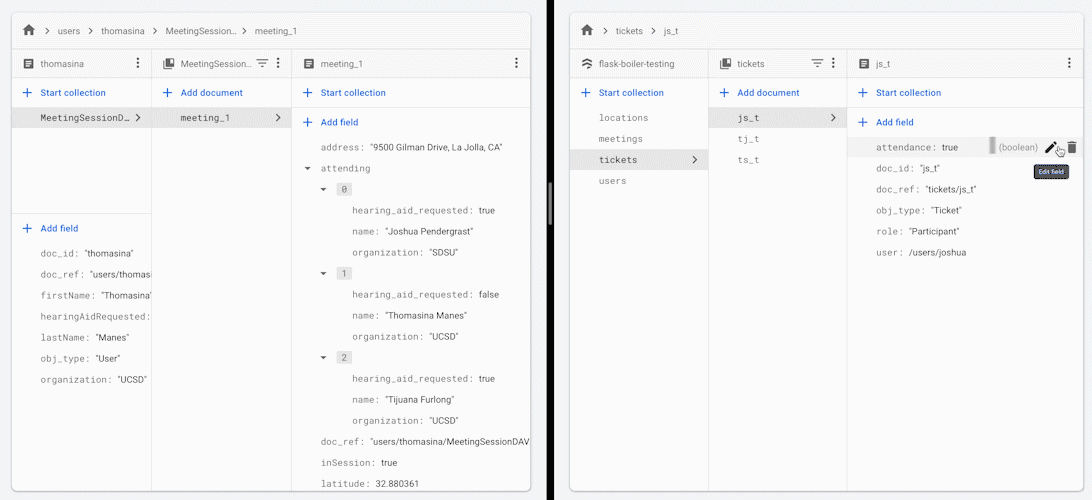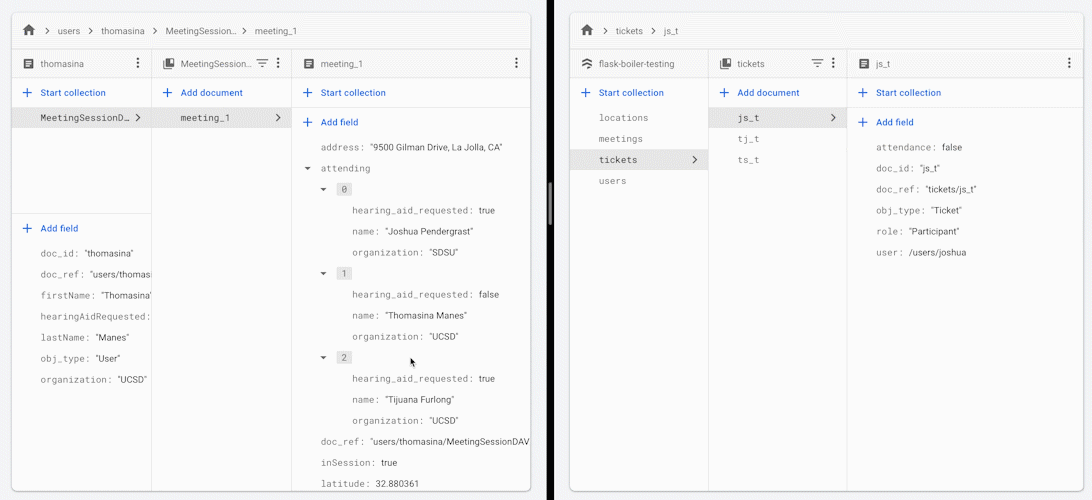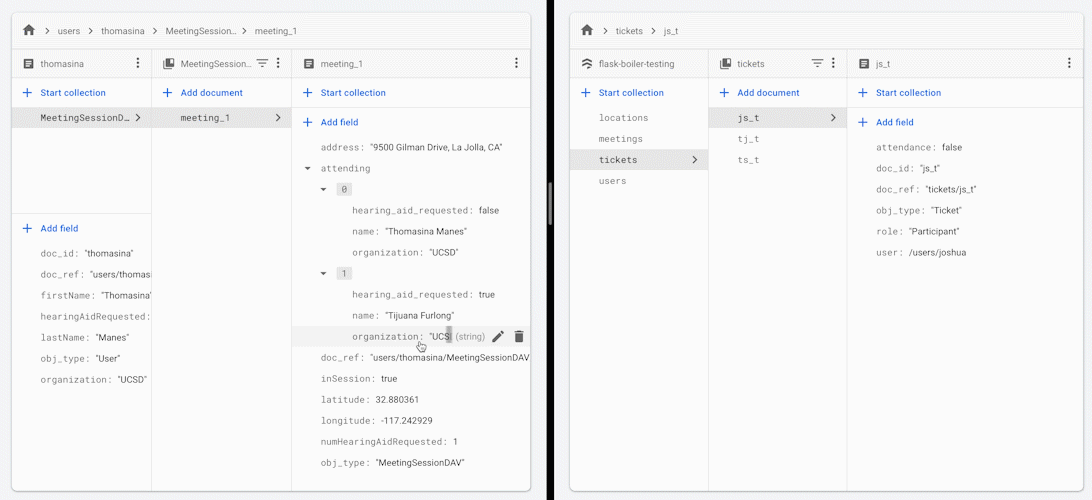
您可能想要使用此框架或架构实践的某些原因
- 您想要构建一个反应式系统,而不仅仅是反应式视图。
- 您想要构建一个适用于分布式系统的原生可扩展应用程序。
- 您需要一个具有更高抽象级别的框架,以便可以交换组件,例如传输协议。
- 您希望代码易于阅读和清晰,并且主要用Python编写,同时保持与不同API的兼容性。
- 您有不断变化的需求,并且希望拥有迁移不同层的灵活性,例如,从REST API切换到WebSocket来提供资源。
本框架处于测试阶段。API 不可保证,可能会更改。
文档:readthedocs
快速入门:快速入门
API 文档:API Docs
使用 flask-boiler 的项目示例:gravitate-backend
理想用法
boiler 会将您的 Python 代码编译成 Flink 任务、Web 服务器等,以便在 Kubernetes 引擎上运行(目前尚未实现)。

支持的连接器
已实现
- REST API(Flask 和 Flasgger)
- GraphQL(Starlette)
- Firestore
- Firebase Functions
- JsonRPC(flask-jsonrpc)
- Leancloud Engine
- WebSocket(flask socketio)
待支持
- Flink Table API
- Kafka
设计模式
onto 抽象为 MVVM(模型-视图-视图模型),其中,
- 模型由事务型数据库或数据存储组成,位于后端。
- ViewModel 由模型和聚合器组成的分布式状态组成。它是 boiler 的主要部分。对于客户端读取,它接收来自模型层的流,并将它们作为视图输出到视图层。对于客户端写入,它接收来自视图层的更改流,并在模型层上操作以持久化更改。ViewModel 位于后端,可以是 boiler Python 代码,也可以在大数据处理应用的情况下编译为 Flink 任务(待实现)。
- 视图是后端的表示层。它提供 1NF 规范化数据,这些数据对前端来说是可读的,无需进一步聚合。客户端对视图进行读写。视图应该是短暂的,可以从 ViewModel 重建。
视图可以是远程系统,例如 Firestore 或 Leancloud。
安装
在您的项目目录中,
pip install onto
更多信息请参阅 快速入门。
状态管理
您可以将收集到的领域模型信息组合起来,并在 Firestore 中提供服务,这样前端就可以从单个文档或集合中读取所需的所有数据,而无需客户端查询和过多的服务器往返时间。
有一篇中等长度的 文章 解释了类似的架构,称为 "reSolve" 架构。
请参阅 examples/meeting_room/view_models 了解如何使用 onto 在 Firestore 中公开一个可以直接由前端查询的 "ViewModel",而不需要聚合。
处理器模式
onto 实质上是一个用于源-汇操作框架
Source(s) -> Processor -> Sink(s)
以查询为例,
- Boiler
- NoSQL
- Flink
- 静态方法:转换为 UDF
- 类方法:转换为操作符和聚合器
声明 ViewModel
class CityView(ViewModel):
name = attrs.bproperty()
country = attrs.bproperty()
@classmethod
def new(cls, snapshot):
store = CityStore()
store.add_snapshot("city", dm_cls=City, snapshot=snapshot)
store.refresh()
return cls(store=store)
@name.getter
def name(self):
return self.store.city.city_name
@country.getter
def country(self):
return self.store.city.country
@property
def doc_ref(self):
return CTX.db.document(f"cityView/{self.store.city.doc_id}")
文档视图
class MeetingSessionGet(Mediator):
from onto import source, sink
source = source.domain_model(Meeting)
sink = sink.firestore() # TODO: check variable resolution order
@source.triggers.on_update
@source.triggers.on_create
def materialize_meeting_session(self, obj):
meeting = obj
assert isinstance(meeting, Meeting)
def notify(obj):
for ref in obj._view_refs:
self.sink.emit(reference=ref, snapshot=obj.to_snapshot())
_ = MeetingSession.get(
doc_id=meeting.doc_id,
once=False,
f_notify=notify
)
# mediator.notify(obj=obj)
@classmethod
def start(cls):
cls.source.start()
WebSocket 视图
class Demo(WsMediator):
pass
mediator = Demo(view_model_cls=rainbow_vm,
mutation_cls=None,
namespace="/palette")
io = flask_socketio.SocketIO(app=app)
io.on_namespace(mediator)
创建 Flask 视图
您可以使用 RestMediator 创建 REST API。当您运行 _ = Swagger(app) 时,将在 <site_url>/apidocs 自动生成 OpenAPI3 文档。
app = Flask(__name__)
class MeetingSessionRest(Mediator):
# from onto import source, sink
view_model_cls = MeetingSessionC
rest = RestViewModelSource()
@rest.route('/<doc_id>', methods=('GET',))
def materialize_meeting_session(self, doc_id):
meeting = Meeting.get(doc_id=doc_id)
def notify(obj):
d = obj.to_snapshot().to_dict()
content = jsonify(d)
self.rest.emit(content)
_ = MeetingSessionC.get(
doc_id=meeting.doc_id,
once=False,
f_notify=notify
)
# @rest.route('/', methods=('GET',))
# def list_meeting_ids(self):
# return [meeting.to_snapshot().to_dict() for meeting in Meeting.all()]
@classmethod
def start(cls, app):
cls.rest.start(app)
swagger = Swagger(app)
app.run(debug=True)
(目前处于实施中)
对象生命周期
一次
使用 cls.new 创建对象 -> 使用 obj.to_view_dict 导出对象。
多次
当数据库中创建新的领域模型时创建对象 -> 当底层数据源更改时更改对象 -> 对象调用 self.notify
典型的 ViewMediator 用例
数据流向描述为源 -> 汇。 "读取" 描述了前端在汇中找到数据有用的数据流。 "写入" 描述了汇是唯一真相来源的数据流。
REST
读取:请求 -> 响应
写入:请求 -> 文档
- 前端向服务器发送 HTTP 请求
- 服务器查询数据存储
- 服务器返回响应
查询
读取:文档 -> 文档
写入:文档 -> 文档
- 数据存储触发更新函数
- 服务器重建可能因更新而改变的 ViewModel
- 服务器将新建的 ViewModel 保存到数据存储
查询+任务
读取:文档 -> 文档
写入:文档 -> 文档
- 数据存储在时间
t触发对文档d的更新函数 - 服务器开始事务
- 服务器设置 write_option 只允许在文档在时间
t最后更新时提交(仍在设计中) - 服务器使用事务构建 ViewModel
- 服务器使用事务保存 ViewModel
- 服务器将文档
d标记为已处理(删除文档或更新字段) - 如果前提条件失败,服务器从步骤 2 重新尝试最多 MAX_RETRIES 次
WebSocket
读取:文档 -> WebSocket 事件
写入:WebSocket 事件 -> 文档
- 前端通过向服务器发送 WebSocket 事件来订阅 ViewModel
- 服务器将监听器附加到查询结果
- 每当查询结果改变且一致时
- 服务器重建可能因更新而改变的 ViewModel
- 服务器发布新构建的 ViewModel
- 前端结束会话
- 文档监听器被释放
文档
读取:文档 -> 文档
写入:文档 -> 文档
比较
| REST | 查询 | 查询+任务 | WebSocket | 文档 | |
|---|---|---|---|---|---|
| 保证 | ≤1 (最多一次) | ≥ 1 (至少一次) | =1[^1] (恰好一次) | ≤1 (最多一次) | ≥ 1 (至少一次) |
| 幂等性 | 如果实现 | 否 | 是,带有事务[^1] | 如果实现 | 否 |
| 设计用于 | 无状态 Lambda | 有状态容器 | 无状态 Lambda | 无状态 Lambda | 有状态容器 |
| 延迟 | 更高 | 更高 | 更高 | 更低 | 更高 |
| 吞吐量 | 当扩展时更高 | 更低[^2] | 更低 | 当扩展时更高 | 更低[^2] |
| 有状态 | 否 | 如果实现 | 如果实现 | 是 | 是 |
| 响应式 | 否 | 是 | 是 | 是 | 是 |
[^1]: 消息可能被多个消费者接收和处理,但只有一个消费者可以成功提交更改并标记事件为已处理。[^2]: 可扩展性受您可以附加到数据存储的监听器数量的限制。
优点
解耦领域模型和视图模型
使用 Firebase Firestore 有时需要在多个文档中重复字段,以便查询数据和在前端正确显示。Flask-boiler 通过解耦领域模型和视图模型来解决此问题。视图模型随着领域模型的变化自动生成和刷新。这意味着您只需在领域模型上编写业务逻辑,无需担心数据的显示方式。这也意味着视图模型可以直接在前端显示,同时支持 Firebase Firestore 的实时功能。
一键配置
而不是为您的数据库和其他云服务配置网络和不同的证书设置。您需要做的只是通过 Google Cloud Console 启用相关服务,并添加您的证书。Flask-boiler 配置您需要的所有服务,并将它们作为单例 Context 对象在整个项目中公开。
冗余
由于所有 ViewModel 都持久保存在 Firebase Firestore 中。即使您的应用实例离线,用户仍然可以通过 Firebase Firestore 访问数据的视图。每个视图也是 Flask 视图,因此您也可以通过自动生成的 REST API 访问数据,以防 Firebase Firestore 不可用。
增加安全性
通过将业务数据与前端可访问的文档分开,您可以更好地控制哪些数据根据用户的角色显示。
一键文档
所有 ViewModel 都有自动生成的文档(由 Flasgger 提供)。这有助于敏捷团队保持文档和实际代码的一致性。
完全可扩展
当您需要更好的性能或关系数据库支持时,您始终可以通过添加模块(如 flask-sqlalchemy)来重构特定的层。
比较
GraphQL
在 GraphQL 中,字段是在每次查询时评估的,但只有在底层数据源更改时才会评估字段。这导致对一段时间内没有更改的数据的读取更快。此外,预期数据源是一致的,因为字段评估是在对 firestore 的一次事务中所有更改读取之后触发的。
然而,GraphQL 允许前端自定义返回的内容。您必须在 onto 中定义您想要返回的确切结构。尽管如此,这也有其优势,因为大多数请求和响应的文档都可以像 REST API 一样进行。
REST API / Flask
REST API 不缓存或存储响应。当 onto 评估视图模型时,响应将永久存储在 firestore 中,直到更新或手动删除。
Flask-boiler 通过与 Firestore 集成的安全规则控制基于角色的访问。REST API 通常使用 JWT 令牌来控制这些访问。
Redux
Redux 主要在前端实现。Flask-boiler 面向后端,更具有可扩展性,因为所有数据都是通过 Firestore 通信,它是无限可扩展的 NoSQL 数据存储。
Flask-boiler 是声明式的,而 Redux 是命令式的。REDUX 的设计模式要求你在领域模型中编写函数式编程,但 onto 倾向于不同的方法:ViewModel 从领域模型读取和计算数据,并将属性暴露为属性获取器。(当写入 DomainModel 时,视图模型更改领域模型,并将操作暴露为属性设置器)。尽管如此,您仍然可以添加在领域模型更新后触发的功能回调,但这可能会引入并发问题,并且由于 onto 的设计权衡,这可能不会得到完美的支持。
架构图
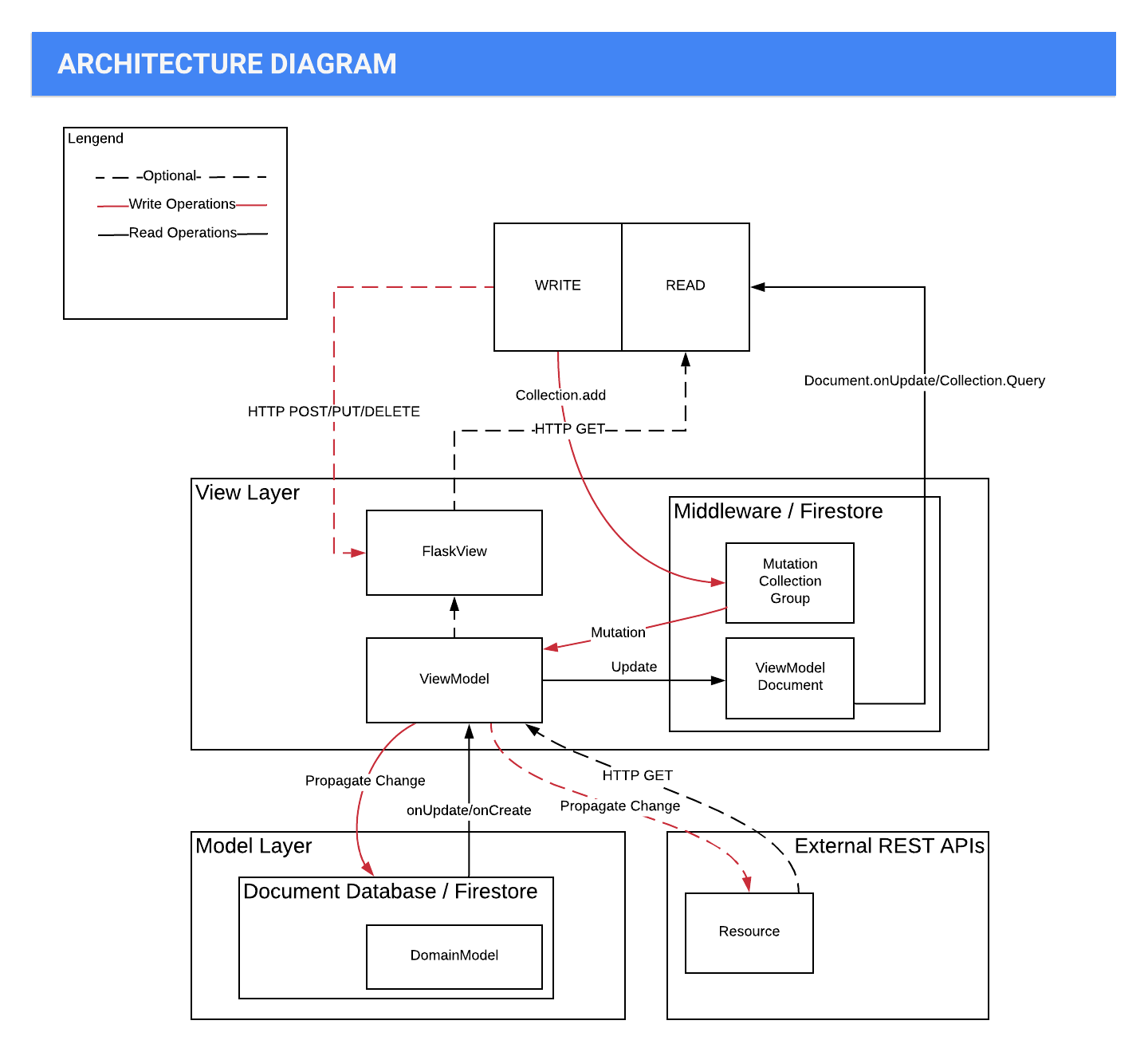
贡献
欢迎提交拉取请求。
请确保适当更新测试。
许可证


onto-0.0.1.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | b34376e682d126ec1b8ffe44b73769d3399a487ad1ea37559be5fca99920a302 |
|
| MD5 | 279e76ba72f24daa2023687ce48039e3 |
|
| BLAKE2b-256 | 947ce092ced8fd0d0f36fb65c72ef38eb1a2ba205e9cf8a305bb5fb5b8fbbc22 |