ndx-hierarchical-behavioral-data NWB扩展

安装
pip install ndx-hierarchical-behavioral-data
使用
使用预制的分层转录表
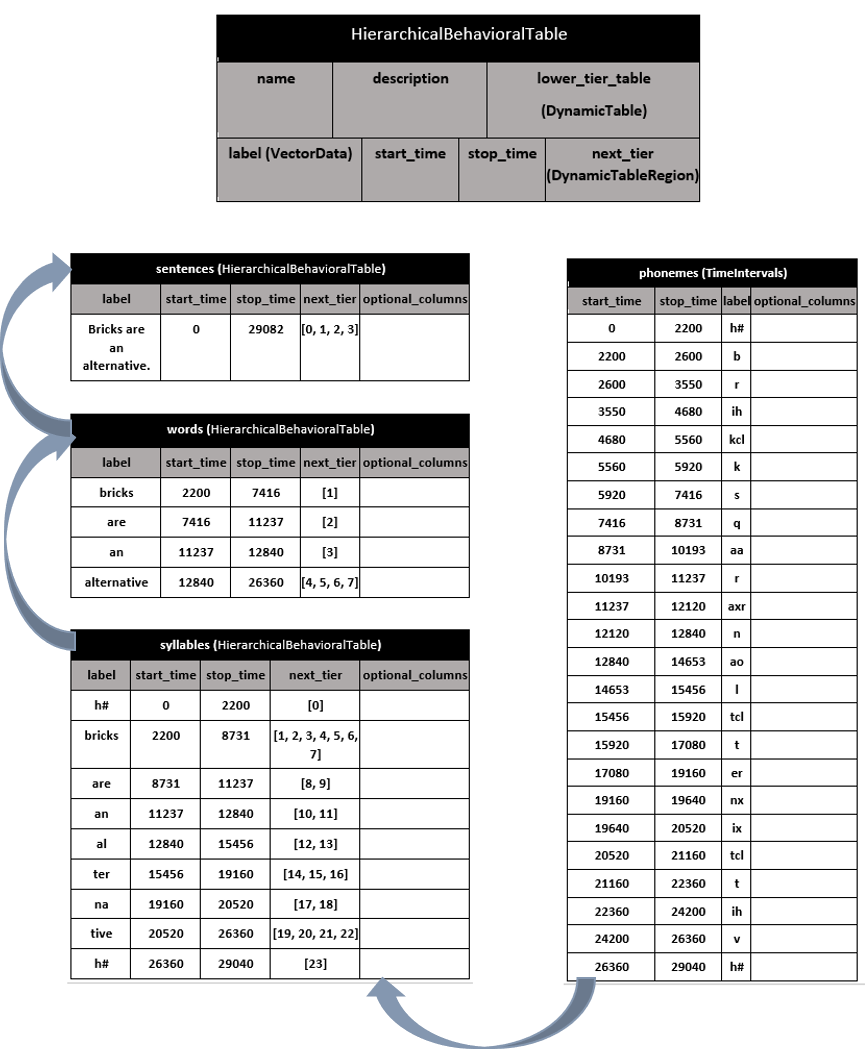
from ndx_hierarchical_behavioral_data.definitions.transcription import TIPhonemes, HBTSyllables, HBTWords, HBTSentences
# Phonemes level
phonemes = TIPhonemes()
phonemes.add_column('max_pitch', 'maximum pitch for this phoneme. NaN for unvoiced')
for i, p in enumerate('abcdefghijkl'):
phonemes.add_interval(label=p, start_time=float(i), stop_time=float(i+1), max_pitch=i**2)
# Syllables level
syllables = HBTSyllables(lower_tier_table=phonemes)
syllables.add_interval(label='abc', next_tier=[0, 1, 2])
syllables.add_interval(label='def', next_tier=[3, 4, 5])
syllables.add_interval(label='ghi', next_tier=[6, 7, 8])
syllables.add_interval(label='jkl', next_tier=[9, 10, 11])
# Words level
words = HBTWords(lower_tier_table=syllables)
words.add_column('emphasis', 'boolean indicating whether this word was emphasized')
words.add_interval(label='A-F', next_tier=[0, 1], emphasis=False)
words.add_interval(label='G-L', next_tier=[2, 3], emphasis=True)
# Sentences level
sentences = HBTSentences(lower_tier_table=words)
sentences.add_interval(label='A-L', next_tier=[0, 1])
查看单个层级
sentences.to_dataframe()
| 标签 | 开始时间 | 结束时间 | 下一个层级 |
|---|
| id | | | | |
|---|
| 0 | A-L | 0.0 | 12.0 | 标签 开始时间 结束时间 \\id ... |
|---|
words.to_dataframe()
| 标签 | 开始时间 | 结束时间 | 下一个层级 | 强调 |
| id | | | | | |
| 0 | A-F | 0.0 | 6.0 | 标签 开始时间 结束时间 \\ id 0 abc 0.0 3.0 1 def 3.0 6.0 下一个层级 id 0 开始时间 结束时间 标签 最大音高 id 0 0.0 1.0 a 0 1 1.0 2.0 b 1 2 2.0 3.0 c 4 1 开始时间 结束时间 标签 最大音高 id 3 3.0 4.0 d 9 4 4.0 5.0 e 16 5 5.0 6.0 f 25 | False |
| 1 | G-L | 6.0 | 12.0 | 标签 开始时间 结束时间 \\ id 2 ghi 6.0 9.0 3 jkl 9.0 12.0 下一个层级 id 2 开始时间 结束时间 标签 最大音高 id 6 6.0 7.0 g 36 7 7.0 8.0 h 49 8 8.0 9.0 i 64 3 开始时间 结束时间 标签 最大音高 id 9 9.0 10.0 j 81 10 10.0 11.0 k 100 11 11.0 12.0 l 121 | True |
syllables.to_dataframe()
| 标签 | 开始时间 | 结束时间 | 下一个层级 |
|---|
| id | | | | |
| 0 | abc | 0.0 | 3.0 | 开始时间 结束时间 标签 id 0 0.0 1.0 a 1 1.0 2.0 b 2 2.0 3.0 c |
| 1 | def | 3.0 | 6.0 | 开始时间 结束时间 标签 id 3 3.0 4.0 d 4 4.0 5.0 e 5 5.0 6.0 f |
| 2 | ghi | 6.0 | 9.0 | 开始时间 结束时间 标签 id 6 6.0 7.0 g 7 7.0 8.0 h 8 8.0 9.0 i |
| 3 | jkl | 9.0 | 12.0 | 开始时间 结束时间 标签 id 9 9.0 10.0 j 10 10.0 11.0 k 11 11.0 12.0 l |
phonemes.to_dataframe()
| 开始时间 | 结束时间 | 标签 | 最大俯仰角 |
| id | | | | |
| 0 | 0.0 | 1.0 | a | 0 |
| 1 | 1.0 | 2.0 | b | 1 |
| 2 | 2.0 | 3.0 | c | 4 |
| 3 | 3.0 | 4.0 | d | 9 |
| 4 | 4.0 | 5.0 | e | 16 |
| 5 | 5.0 | 6.0 | f | 25 |
| 6 | 6.0 | 7.0 | g | 36 |
| 7 | 7.0 | 8.0 | h | 49 |
| 8 | 8.0 | 9.0 | i | 64 |
| 9 | 9.0 | 10.0 | j | 81 |
| 10 | 10.0 | 11.0 | k | 100 |
| 11 | 11.0 | 12.0 | l | 121 |
分层数据框
sentences.to_hierarchical_dataframe()
| | | | | | | | | | | | 源表 | 音素 |
| | | | | | | | | | | | 标签 | id | 开始时间 | 结束时间 | 标签 | 最大俯仰角 |
| 句子ID | 句子标签 | 句子开始时间 | 句子结束时间 | 单词ID | 单词标签 | 单词开始时间 | 单词结束时间 | 单词强调 | 音节ID | 音节标签 | 音节开始时间 | 音节结束时间 | | | | | |
| 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 3.0 | 1 | 1.0 | 2.0 | b | 1 |
| 3.0 | 2 | 2.0 | 3.0 | c | 4 |
| 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 |
| 6.0 | 4 | 4.0 | 5.0 | e | 16 |
| 6.0 | 5 | 5.0 | 6.0 | f | 25 |
| 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 |
| 9.0 | 7 | 7.0 | 8.0 | h | 49 |
| 9.0 | 8 | 8.0 | 9.0 | i | 64 |
| 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 |
| 12.0 | 10 | 10.0 | 11.0 | k | 100 |
| 12.0 | 11 | 11.0 | 12.0 | l | 121 |
分层列,扁平化行
from hdmf.common.hierarchicaltable import flatten_column_index
flatten_column_index(sentences.to_hierarchical_dataframe(), 1)
| | | | | | | | | | | | | id | 开始时间 | 结束时间 | 标签 | 最大俯仰角 |
| 句子ID | 句子标签 | 句子开始时间 | 句子结束时间 | 单词ID | 单词标签 | 单词开始时间 | 单词结束时间 | 单词强调 | 音节ID | 音节标签 | 音节开始时间 | 音节结束时间 | | | | | |
| 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 3.0 | 1 | 1.0 | 2.0 | b | 1 |
| 3.0 | 2 | 2.0 | 3.0 | c | 4 |
| 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 |
| 6.0 | 4 | 4.0 | 5.0 | e | 16 |
| 6.0 | 5 | 5.0 | 6.0 | f | 25 |
| 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 |
| 9.0 | 7 | 7.0 | 8.0 | h | 49 |
| 9.0 | 8 | 8.0 | 9.0 | i | 64 |
| 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 |
| 12.0 | 10 | 10.0 | 11.0 | k | 100 |
| 12.0 | 11 | 11.0 | 12.0 | l | 121 |
非规范化数据框
from hdmf.common.hierarchicaltable import to_hierarchical_dataframe
to_hierarchical_dataframe(sentences).reset_index()
| 源表 | 句子 | 单词 | 音节 | 音素 |
| 标签 | id | 标签 | 开始时间 | 结束时间 | id | 标签 | 开始时间 | 结束时间 | 强调 | id | 标签 | 开始时间 | 结束时间 | id | 开始时间 | 结束时间 | 标签 | 最大俯仰角 |
| 0 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 1 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 1 | 1.0 | 2.0 | b | 1 |
| 2 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 2 | 2.0 | 3.0 | c | 4 |
| 3 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 |
| 4 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 4 | 4.0 | 5.0 | e | 16 |
| 5 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 5 | 5.0 | 6.0 | f | 25 |
| 6 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 |
| 7 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 7 | 7.0 | 8.0 | h | 49 |
| 8 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 8 | 8.0 | 9.0 | i | 64 |
| 9 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 |
| 10 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 10 | 10.0 | 11.0 | k | 100 |
| 11 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 11 | 11.0 | 12.0 | l | 121 |
具有扁平化列的非规范化数据框
from hdmf.common.hierarchicaltable import flatten_column_index
flatten_column_index(sentences.to_hierarchical_dataframe(), 1).reset_index()
| 句子ID | 句子标签 | 句子开始时间 | 句子结束时间 | 单词ID | 单词标签 | 单词开始时间 | 单词结束时间 | 单词强调 | 音节ID | 音节标签 | 音节开始时间 | 音节结束时间 | id | 开始时间 | 结束时间 | 标签 | 最大俯仰角 |
| 0 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 0 | 0.0 | 1.0 | a | 0 |
| 1 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 1 | 1.0 | 2.0 | b | 1 |
| 2 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 0 | abc | 0.0 | 3.0 | 2 | 2.0 | 3.0 | c | 4 |
| 3 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 3 | 3.0 | 4.0 | d | 9 |
| 4 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 4 | 4.0 | 5.0 | e | 16 |
| 5 | 0 | A-L | 0.0 | 12.0 | 0 | A-F | 0.0 | 6.0 | False | 1 | def | 3.0 | 6.0 | 5 | 5.0 | 6.0 | f | 25 |
| 6 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 6 | 6.0 | 7.0 | g | 36 |
| 7 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 7 | 7.0 | 8.0 | h | 49 |
| 8 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 2 | ghi | 6.0 | 9.0 | 8 | 8.0 | 9.0 | i | 64 |
| 9 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 9 | 9.0 | 10.0 | j | 81 |
| 10 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 10 | 10.0 | 11.0 | k | 100 |
| 11 | 0 | A-L | 0.0 | 12.0 | 1 | G-L | 6.0 | 12.0 | True | 3 | jkl | 9.0 | 12.0 | 11 | 11.0 | 12.0 | l | 121 |
本扩展使用 ndx-template 创建。












