近似最近邻库




项目描述




轻量级近似 Nearest N
N2代表两个N,来源于'近似 Nearest Neighbor 算法'。 在N2之前,已经存在其他一些优秀的近似最近邻库,例如 Annoy 和 NMSLIB。然而,它们各自在可用性、性能等方面都有不同的优势和劣势。因此,N2的开发目标是结合现有aKNN库的优势,并弥补其不足。 轻量级库,可以快速处理大型数据集。 在索引构建时间、搜索速度和内存使用方面表现出良好的性能。 支持多核CPU进行索引构建。 默认支持mmap功能,以高效处理大型索引文件。 支持Python/Go绑定。 度量 定义 d(p, q) “角度” 1 - cosθ 1 - {sum(pi · qi) / sqrt(sum(pi · pi) · sum(qi · qi))} “L2” 平方L2 sum{(pi - qi)2} “点积” 点积 sum(pi · qi) N2支持三种距离度量。对于“角度”和“L2”,距离 d 的定义是:向量越接近,d 越小。然而,对于“点积”,距离 d 的定义是:向量越接近,d 越大。您可能想知道为什么我们将“点积”度量定义为“点积”而不是“(1 - 点积)”。做出这一决定的理由是,允许用户将Hnsw搜索函数返回的 d 值直接解释为点积值。 使用pip安装N2。 以下是一个Python代码片段,演示如何使用N2。 请访问 n2.readthedocs.io 获取完整文档。该文档网站详细解释了以下内容。 以下是我们的基准实验结果。 您还可以在 ann-benchmarks.com 上查看各种ANN库的基准测试。请注意,ann-benchmarks.com(最后检查日期:2020年10月8日)使用的是N2版本0.1.6,我们正在继续努力提高N2的性能。 Y. A. Malkov和D. A. Yashunin,“使用分层可导航小世界图进行高效且鲁棒的近似最近邻搜索,”CoRR,vol. abs/1603.09320,2016。[在线]。可获得:http://arxiv.org/abs/1603.09320 本软件根据以下 Apache 2许可证 许可,如下所述。 版权所有 2017 Kakao Corp。http://www.kakaocorp.com 根据“许可证”(“许可证”);除非遵守本许可证,否则不得使用本项目。您可以在 https://apache.ac.cn/licenses/LICENSE-2.0 获取许可证的副本。 除非适用法律要求或书面同意,否则在许可证下分发的软件按“原样”提供,不提供任何明示或暗示的保证或条件。有关许可证的具体语言、许可和限制,请参阅许可证。为什么创建N2
特性
支持的距离度量
快速入门
$ pip install n2
import numpy as np
from n2 import HnswIndex
N, dim = 10240, 20
samples = np.arange(N * dim).reshape(N, dim)
index = HnswIndex(dim)
for sample in samples:
index.add_data(sample)
index.build(m=5, n_threads=4)
print(index.search_by_id(0, 10))
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]完整文档
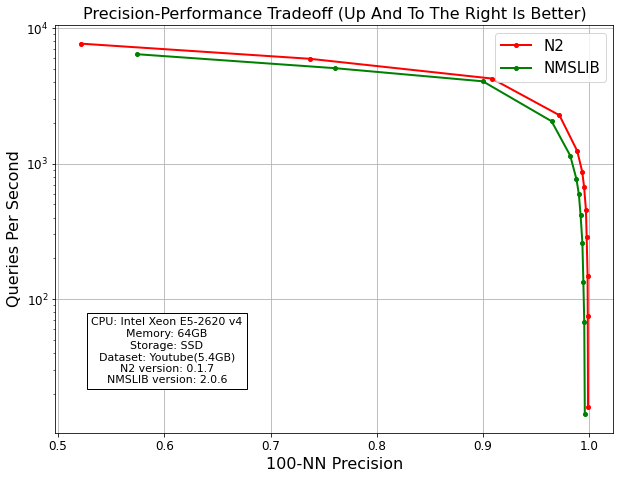
性能
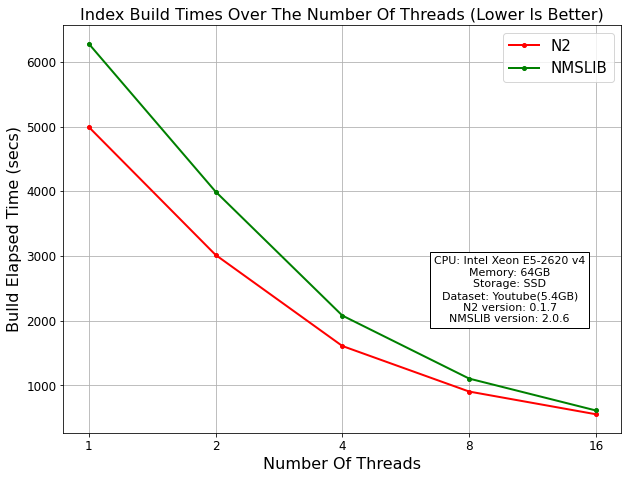
索引构建时间
搜索速度
内存使用
参考文献
许可证



n2-0.1.7.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 6a044d89aa20fc13063788447103aa285889ef8d581335f8a7afe8a6170a9e51 |
|
| MD5 | 1bd3b3a31e8c518fc90f88b708cac9b4 |
|
| BLAKE2b-256 | d6cb103c5a332e528940a8096bf34c914e26f90dc52d5998d32fad135f21b944 |







