可扩展的机器学习时间序列预测



项目描述
mlforecast

机器学习 🤖 预测
可扩展的机器学习时间序列预测





mlforecast 是一个使用机器学习模型进行时间序列预测的框架,可选择使用远程集群扩展到大量数据。
安装
PyPI
pip install mlforecast
conda-forge
conda install -c conda-forge mlforecast
更多详细说明,请参考安装页面。
快速入门
通过此快速指南开始。
遵循此端到端演练以了解最佳实践。
示例笔记本
为什么?
目前,机器学习模型的Python替代方案速度慢、不准确,且扩展性不好。因此,我们创建了一个库,可以在生产环境中进行预测。《MLForecast》包括高效的特性工程,可以训练任何机器学习模型(具有fit和predict方法,如sklearn),以适应数百万的时间序列。MLForecast包括高效的特性工程,以便训练任何机器学习模型(具有fit和predict方法,如sklearn),以适应数百万的时间序列。
特性
- Python中时间序列预测特性工程的最快实现。
- 与pandas、polars、spark、dask和ray开箱即用兼容。
- 符合预测的概率预测。
- 支持外生变量和静态协变量。
- 熟悉的
sklearn语法:.fit和.predict。
缺少什么?请提出问题或给我们
示例和指南
📚 端到端演练:多时间序列的模型训练、评估和选择。
🔎 概率预测:使用符合预测来生成预测区间。
👩🔬 交叉验证:稳健的模型性能评估。
🔌 预测需求峰值:检测每日峰值并降低电费的电负荷预测。
📈 迁移学习:使用一组时间序列预训练模型,然后使用预训练模型预测另一个时间序列。
🌡️ 分布式训练:使用Dask、Ray或Spark集群进行大规模模型训练。
如何使用
以下提供非常基本的概述,更详细的信息请参阅文档。
数据设置
将您的时序数据存储在长格式的pandas数据框中,即每一行代表特定系列和时间戳的观测值。
from mlforecast.utils import generate_daily_series
series = generate_daily_series(
n_series=20,
max_length=100,
n_static_features=1,
static_as_categorical=False,
with_trend=True
)
series.head()
| unique_id | ds | y | static_0 | |
|---|---|---|---|---|
| 0 | id_00 | 2000-01-01 | 17.519167 | 72 |
| 1 | id_00 | 2000-01-02 | 87.799695 | 72 |
| 2 | id_00 | 2000-01-03 | 177.442975 | 72 |
| 3 | id_00 | 2000-01-04 | 232.704110 | 72 |
| 4 | id_00 | 2000-01-05 | 317.510474 | 72 |
注意:unique_id用作数据集中每个不同时序的标识符。如果您仅使用数据集中的单个时序,则将此列设置为常量值。
模型
接下来定义您的模型,每个模型将训练在所有序列上。这些可以是遵循scikit-learn API的任何回归器。
import lightgbm as lgb
from sklearn.linear_model import LinearRegression
models = [
lgb.LGBMRegressor(random_state=0, verbosity=-1),
LinearRegression(),
]
预测对象
现在实例化一个包含模型和您想要使用的特征的MLForecast对象。这些特征可以是滞后、滞后上的转换和日期特征。您还可以定义在拟合之前应用于目标的转换,这将在线预测时恢复。
from mlforecast import MLForecast
from mlforecast.lag_transforms import ExpandingMean, RollingMean
from mlforecast.target_transforms import Differences
fcst = MLForecast(
models=models,
freq='D',
lags=[7, 14],
lag_transforms={
1: [ExpandingMean()],
7: [RollingMean(window_size=28)]
},
date_features=['dayofweek'],
target_transforms=[Differences([1])],
)
训练
要计算特征并训练模型,请对您的Forecast对象调用fit。
fcst.fit(series)
MLForecast(models=[LGBMRegressor, LinearRegression], freq=D, lag_features=['lag7', 'lag14', 'expanding_mean_lag1', 'rolling_mean_lag7_window_size28'], date_features=['dayofweek'], num_threads=1)
预测
要获取下n天的预测,请在预测对象上调用predict(n)。这将自动使用递归策略处理特征所需的更新。
predictions = fcst.predict(14)
predictions
| unique_id | ds | LGBMRegressor | LinearRegression | |
|---|---|---|---|---|
| 0 | id_00 | 2000-04-04 | 299.923771 | 311.432371 |
| 1 | id_00 | 2000-04-05 | 365.424147 | 379.466214 |
| 2 | id_00 | 2000-04-06 | 432.562441 | 460.234028 |
| 3 | id_00 | 2000-04-07 | 495.628000 | 524.278924 |
| 4 | id_00 | 2000-04-08 | 60.786223 | 79.828767 |
| ... | ... | ... | ... | ... |
| 275 | id_19 | 2000-03-23 | 36.266780 | 28.333215 |
| 276 | id_19 | 2000-03-24 | 44.370984 | 33.368228 |
| 277 | id_19 | 2000-03-25 | 50.746222 | 38.613001 |
| 278 | id_19 | 2000-03-26 | 58.906524 | 43.447398 |
| 279 | id_19 | 2000-03-27 | 63.073949 | 48.666783 |
280行 × 4列
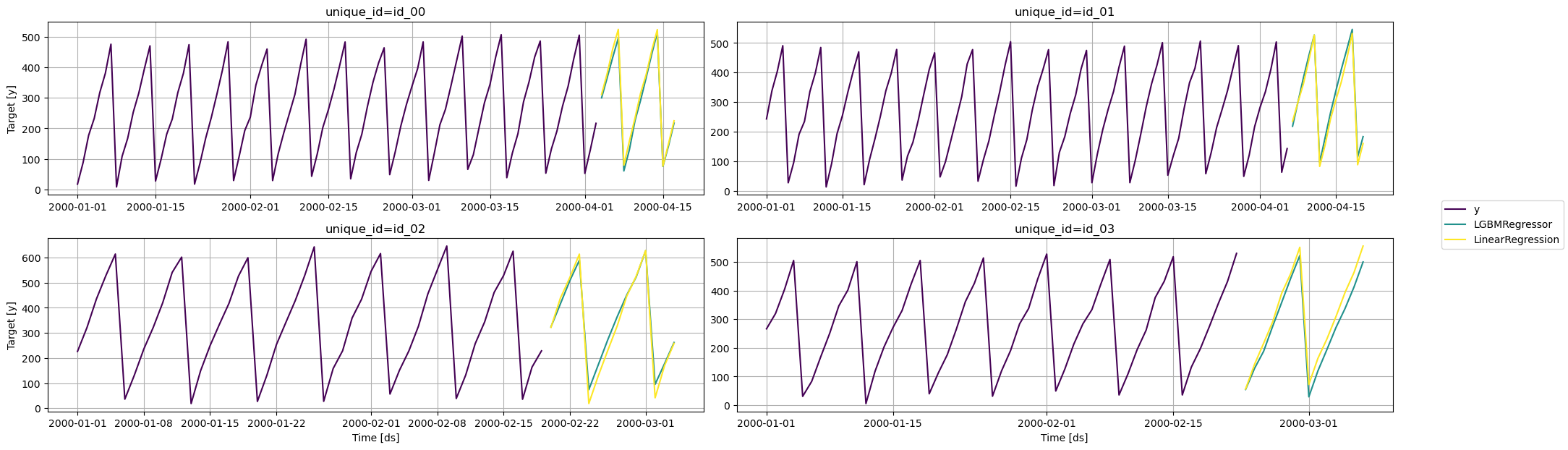
可视化结果
from utilsforecast.plotting import plot_series
fig = plot_series(series, predictions, max_ids=4, plot_random=False)
如何贡献


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。
源分布
构建分布
mlforecast-0.13.4.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | ca55bd7ed1a167f7c6d23554816aa539e2f678a4758d11be7fad7a288f815ee6 |
|
| MD5 | b2e9bf22d51a5b571afef18eb332de63 |
|
| BLAKE2b-256 | 89d88cef1aefed168b22f16551bc16a908ef154d34d85f2a02796e6abf1628c9 |
mlforecast-0.13.4-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | a33be2671e3914f2271deb1a59ab8f50a8c02c617726fdc3232c4f38fdb4e992 |
|
| MD5 | 248c2a32bad9469b75c877aa0290a116 |
|
| BLAKE2b-256 | c231725d92f22fc36e710654051f5ce36c00d78528ea48c6db49875fdf55bb27 |







