MLPerf Inference LoadGen Python绑定


项目描述
概述 {#mainpage}
简介
- LoadGen是一个可重复使用的模块,能够高效且公正地衡量推理系统的性能。
- 它生成由来自MLCommons工作组的专家们制定的多样化场景的流量。
- 这些场景模拟了在移动设备、自动驾驶汽车、机器人和基于云的设置中看到的负载。
- 尽管LoadGen不识别模型或数据集,但其优势在于其逻辑的可重复使用性。
集成示例和流程
以下是一个图,展示了如何将LoadGen集成到推理系统中,类似于一些MLPerf参考模型的实现。

- 基准测试知道模型、数据集和预处理。
- 基准测试将数据样本ID交给LoadGen。
- LoadGen开始生成样本ID的查询。
- 基准测试创建对后端的服务请求。
- 结果经过后处理并转发给LoadGen。
- LoadGen输出用于分析的日志。
有用链接
- 常见问题解答
- LoadGen构建说明
- LoadGen API
- 测试设置 - 提供了可用的场景、模式和旋钮的良好描述。
- MLPerf Inference代码 - 包含LoadGen和使用了LoadGen的参考模型的源代码。
- MLPerf Inference规则 - 任何与此不符的地方都是LoadGen的bug。
LoadGen责任的范围
范围内
- 提供一个可重复使用的 C++库,并带有Python绑定。
- 实现 MLPerf Inference 场景和模式的流量模式。
- 记录 所有的生成和接收到的流量,以供后续分析和验证。
- 总结 结果以及性能约束是否满足。
- 针对高性能 系统,使用高效的、多线程友好的日志工具。
- 通过 共享、经过充分测试和社区加固的代码库来建立信任。
范围之外
LoadGen 是
- 不 了解其运行的 ML 模型。
- 不 了解模型输入和输出的数据格式。
- 不 了解如何评分模型输出的准确性。
- 不 了解 MLPerf 关于特定场景约束的规则。
以这种方式限制 LoadGen 的范围,使其可以在不同的模型和数据集之间重用而不需要修改。用户可以通过组合和依赖注入来定义自己的模型、数据集和指标。
此外,不硬编码 MLPerf 特定的测试约束,如测试持续时间和性能目标,允许用户在不修改的情况下用于自定义测试和持续集成。
提交注意事项
将所有本地修改上传
- 原则上,不允许对 LoadGen 的 C++ 库进行本地修改以供提交。
- 请尽早并经常上传,以保持竞争环境公平。
仔细选择您的测试设置!
- 由于 LoadGen 对模型一无所知,因此无法强制执行 MLPerf 的提交要求。例如: 目标百分位和延迟。
- 为了验证,将记录 TestSettings 中的值。
- 为了确保您的设置符合规范,请结合使用 TestSettings::FromConfig 和与参考模型一起提供的相关配置文件。
LoadGen 用户的职责
实现接口
- 实现 SystemUnderTest 和 QuerySampleLibrary 接口,并将它们传递给 StartTest 函数。
- 对于 SystemUnderTest::IssueQuery 接收到的每个样本,调用 QuerySampleComplete。
评估准确性
- 通过 LoadGen 处理 mlperf_log_accuracy.json 输出来确定系统的准确性。
- 对于官方模型,MLPerf 模型所有者将提供 Python 脚本,以自动执行此操作。
有关如何详细执行上述操作的模板,请参阅演示、测试和参考模型的代码。
网络上的 LoadGen
仅供参考,从高层次来看,一个提交看起来像这样
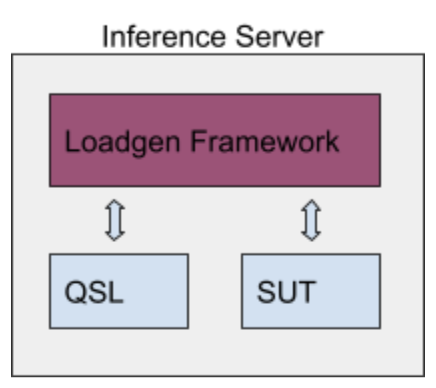
LoadGen 实现对所有提交都是通用的,而 QSL(“查询样本库”)和 SUT(“待测系统”)由提交者实现。QSL 负责加载数据,包括不计时的预处理。
通过网络提交引入了一个新组件“QDL”(查询调度库),如下面的图所示添加到系统中
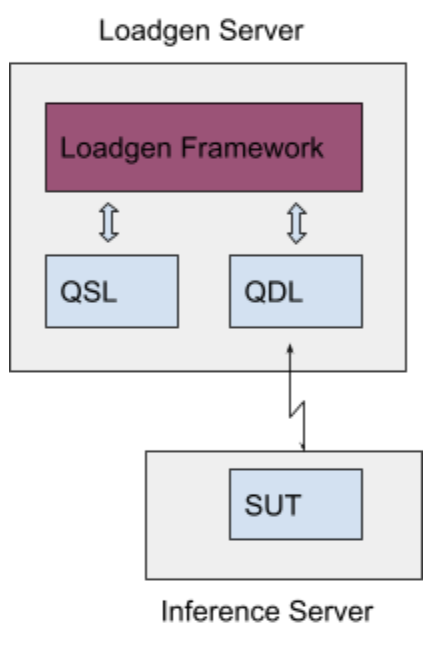
QDL 是负载均衡器的代理,将查询调度到 SUT,通过网络接收响应并将其传递回 LoadGen。它由提交者实现。QDL 的接口与 SUT 的 API 相同。
在使用 QDL 的场景中,数据可以选择在 QSL 中压缩以减少网络传输时间。解压缩是 SUT 中的计时代码的一部分。每个基准将指定一组批准的标准压缩方案;必须由工作组提前批准额外的压缩方案。
LoadGen/QSL 与 SUT 之间的所有通信都通过 QDL 进行,QDL 与 SUT 之间的所有通信都必须通过网络进行。
QDL 实现了在网络中传输查询并接收响应的协议。它还实现了对 SUT 返回的任何响应的解压缩,其中允许压缩响应。在 QDL 中执行任何计时代码或推理的部分都是明确禁止的。目前 QDL 中不允许批处理,尽管将来可能会重新考虑。
MLperf over the Network将在服务器模式和离线模式中运行。所有LoadGen模式都应保持原样,仅做微小修改。这包括在性能模式、准确性模式、寻找峰值性能模式和合规性模式下运行测试。同样的规则也适用于功耗测量。
QDL详细信息
查询调度库(Query Dispatch Library,QDL)由提交者实现,并使用相同的SUT API与LoadGen接口。所有MLPerf Inference SUTs都实现了在system_under_test.h中定义的mlperf::SystemUnderTest类。QDL实现了继承自mlperf::SystemUnderTest类的mlperf::QueryDispatchLibrary类,并具有相同的API,支持所有现有的mlperf::SystemUnderTest方法。它有一个单独的头文件query_dispatch_library.h。在LoadGen的StartTest中使用具有mlperf::SystemUnderTest类的sut进行原生上转型是使用mlperf::QueryDispatchLibrary类。
QDL通过网络查询和响应
QDL通过以下方式从LoadGen获取查询:
void IssueQuery(const std::vector<QuerySample>& samples)
QDL将查询调度到SUT的物理媒体。具体方法和实现由提交者特定,不会在MLCommons中指定。提交者实现包括所有序列化查询、负载均衡、驱动到操作系统和网络接口卡以及发送到SUT所需的方法。
QDL通过网络从SUT接收查询响应。具体方法和实现由提交者特定,不会在MLCommons中指定。提交者实现包括所有从网络接口卡接收网络数据、通过操作系统、反序列化查询响应、并通过查询完成将其提供给LoadGen所需的方法。
struct QuerySampleResponse {
ResponseId id;
uintptr_t data;
size_t size;
};
void QuerySamplesComplete(QuerySampleResponse* responses,
size_t response_count);
QDL附加方法
除了上述方法外,QDL还需要实现SUT接口提供给LoadGen的以下方法:
const std::string& Name();
Name函数返回一个已知字符串,以便网络SUT可以将其识别为网络基准。
void FlushQueries();
此处未指定QDL如何查询和配置SUT以执行上述方法。QDL在从SUT收到自己的响应后对LoadGen做出响应。
示例
有关在网络中使用Loadgen的示例,请参阅LON演示。


mlcommons_loadgen-4.0.1.tar.gz的散列
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 0e7059b289ea2aabb3e9ad1179bbce89703294570ee59c07cf30d52f1b38f732 |
|
| MD5 | 2dce499688f9e7a901c509c4e7ec54d8 |
|
| BLAKE2b-256 | b0fc83d26c14a213adc2a7cf068ce853b841b23a91fcf62216013db6cd858731 |







