使用正向传播微调LLMs

项目描述
MeZO:仅使用正向传播微调语言模型
这是论文Fine-Tuning Language Models with Just Forward Passes的实现。在这篇论文中,我们提出了一种内存高效的零阶优化器(MeZO),将经典的零阶SGD方法调整为原地操作,从而以推理相同的内存占用微调语言模型(LMs)。
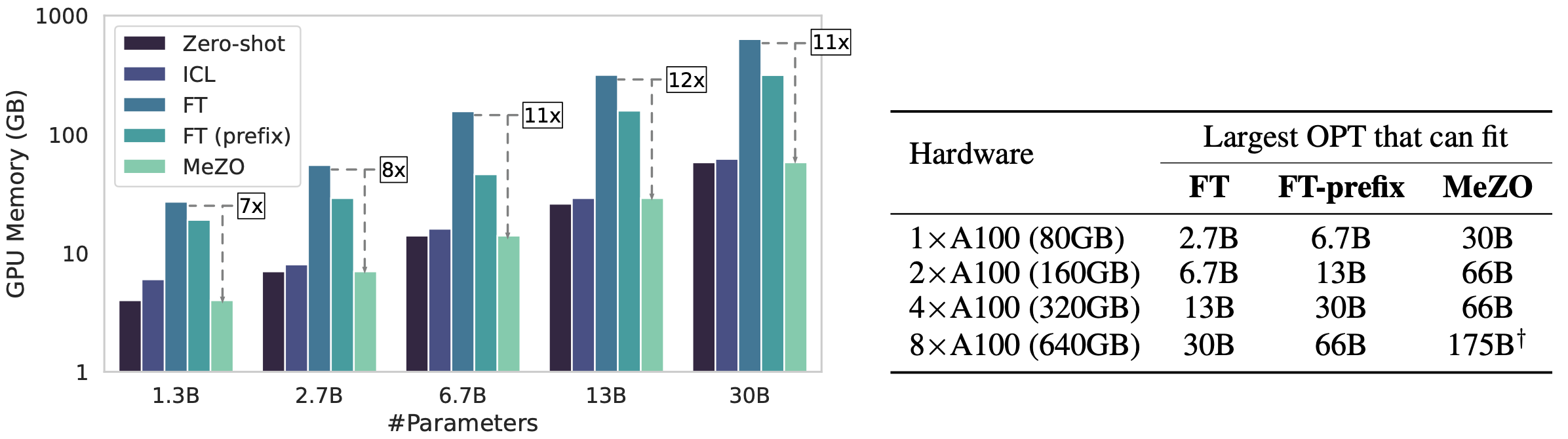
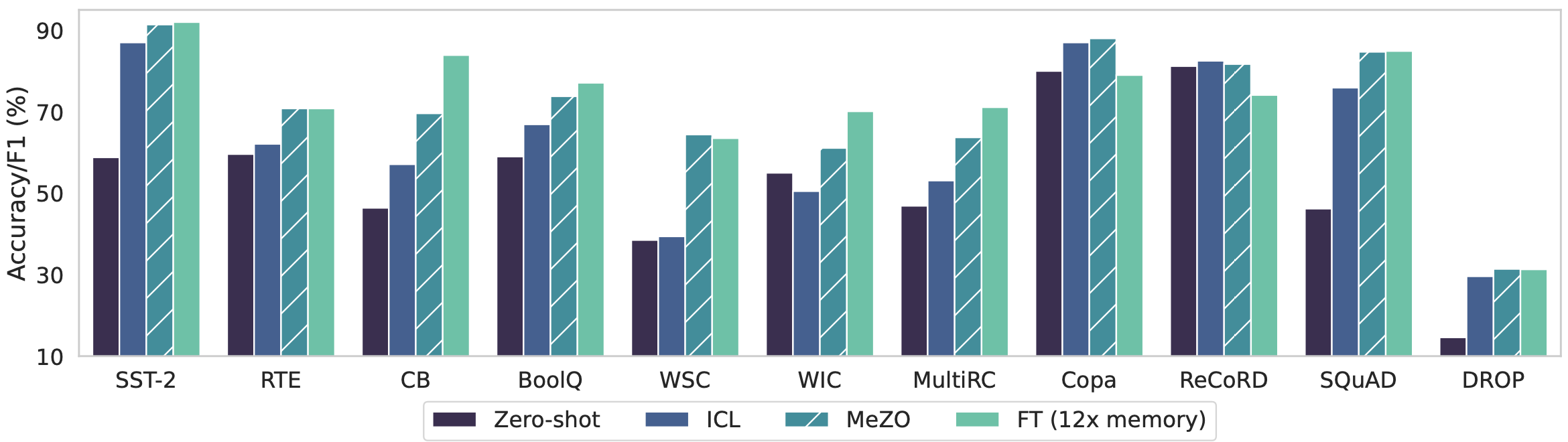
使用单个A100 80GB GPU,MeZO可以训练一个30亿参数的OPT模型,而使用Adam微调只能训练一个27B LM。MeZO在多个任务上显示出与使用反向传播微调相当的性能,内存减少高达12倍。MeZO还与全参数和参数高效的调整技术(如LoRA和前缀调整)兼容。我们还展示了MeZO可以有效地优化不可微分的目标(例如,最大化准确度或F1)。
安装
pip install git+https://www.github.com/lebrice/MeZO
重现我们的论文结果
为重现RoBERTa-large实验,请参考medium_models文件夹。对于自回归LM (OPT) 实验,请参考large_models文件夹。如果您想了解更多关于MeZO的工作原理以及我们如何实现它的信息,我们建议您阅读large_models文件夹,因为它的实现更清晰且更易于扩展。如果您想探索更多MeZO的变体,我们推荐尝试medium_models,因为它更快并且实现了更多变体。
如何将MeZO添加到我的代码中?
我们的MeZO实现基于HuggingFace的Trainer。我们对官方的trainer实现进行了最小程度的修改,添加了MeZO。有关更多详细信息,请参阅large_models README中的“如何将MeZO添加到我的代码中”部分。
有bug或问题吗?
如果您对代码或论文有任何问题,请随时通过电子邮件联系Sadhika(smalladi@princeton.edu)或Tianyu(tianyug@princeton.edu)。如果您在使用代码时遇到任何问题或想报告一个bug,可以提交一个issue。请尽量详细地描述问题,这样我们可以更好地、更快地帮助您!
引用
@article{malladi2023mezo,
title={Fine-Tuning Large Language Models with Just Forward Passes},
author={Malladi, Sadhika and Gao, Tianyu and Nichani, Eshaan and Damian, Alex and Lee, Jason D and Chen, Danqi and Arora, Sanjeev},
year={2023}
}

下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源分布
构建分布
mezo-0.0.1.tar.gz的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 180d168c635c3df0adab28d88760622ec4bfb343c204d39318129e21841eff6e |
|
| MD5 | 6e36dddb267c561cb68e617b1a739c11 |
|
| BLAKE2b-256 | 4a42066a6d31ea5251f676c9c31737f8a764e5d762f06a9dd1bcf28bb87a4d35 |
mezo-0.0.1-py3-none-any.whl的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 72032843ded1cd6fba0a4e15f0b8a54b24f038462f2bf5bba932c29ec98e4b10 |
|
| MD5 | c15b151d07ffc0cfc6722bc7f89141cf |
|
| BLAKE2b-256 | 7b3a7cf86bd226259bdeb1dff4130cc5e4813ebed8ba89a7290dacc981897af4 |







