多元字典学习算法

项目描述
MDLA - 多元字典学习算法



多元数据集的字典学习
这种字典学习变体专门用于处理多元数据集,尤其是时序数据,其中样本是矩阵,数据集被视为一个张量。字典学习算法(DLA)通过稀疏系数向量将输入向量分解到字典矩阵中,如图(a)所示。为了处理多元数据,一个称为多通道DLA的初步方法,如图(b)所示,是在字典矩阵上分解矩阵向量,但使用稀疏系数矩阵,假设多元样本可以被视为由同一字典解释的通道集合。然而,多通道DLA打破了多元样本的“空间”一致性,丢弃了样本中存在的列间关系。《多元DLA》(c),如图所示,将矩阵输入分解到张量字典中,其中每个原子是一个矩阵,具有稀疏系数向量。在这种情况下,空间关系直接编码在字典中,因为每个原子与输入样本具有相同的维度。
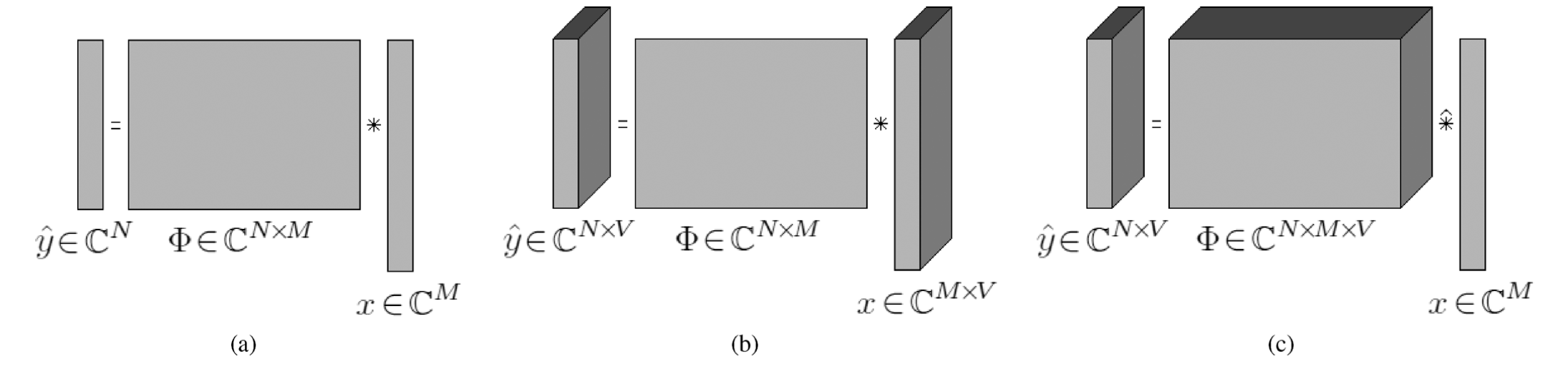
(图片来自Chevallier et al., 2014 )
为了处理时序数据,对DLA进行了两项主要修改
- 扩展到多元样本
- 位移不变方法,第一点已在上面解释。为了实现第二点,有两种可能性,要么将输入时间序列切割成小重叠样本,要么使用比输入样本更小的原子,从而得到具有稀疏系数和偏移量的分解。在后一种情况下,分解可以看作是不同时间步发生的核序列。
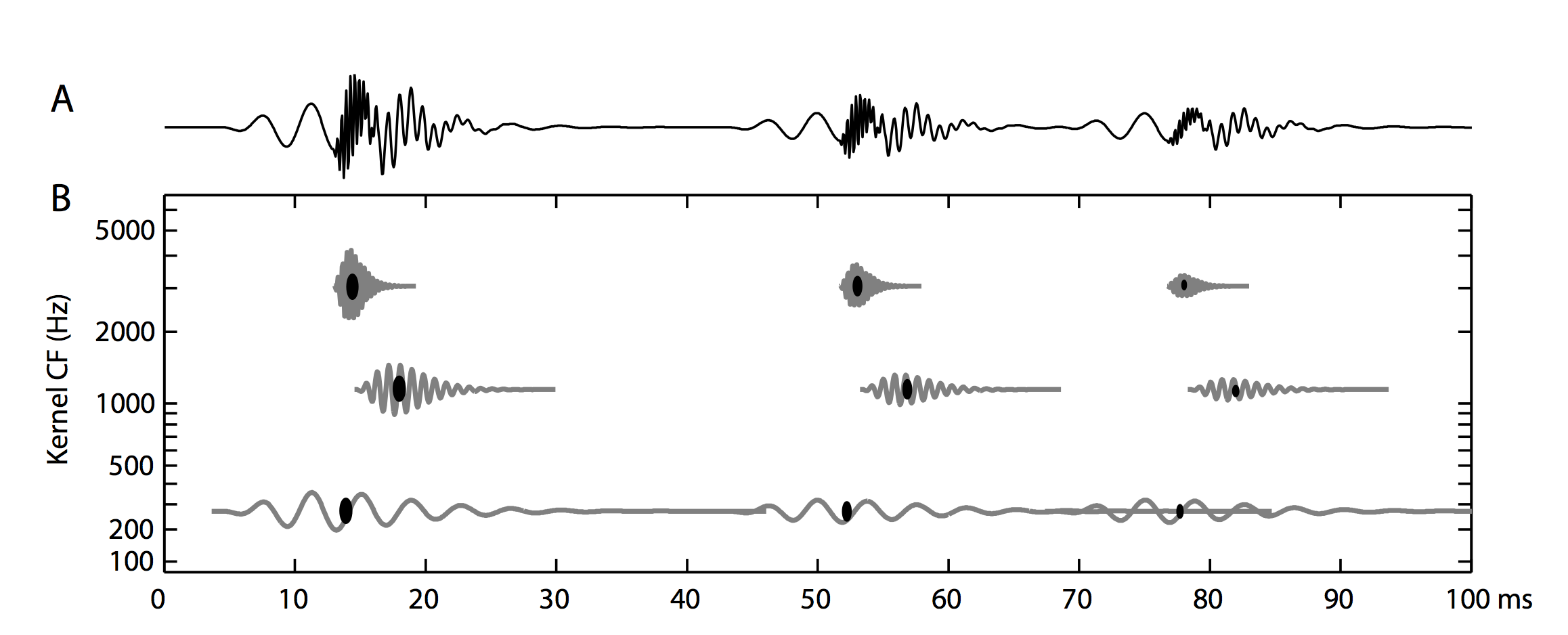
(图来源于 Smith & Lewicki, 2005)
所提出的实现是对以下作者工作的改编
- Q. Barthélemy,A. Larue,A. Mayoue,D. Mercier,和J.I. Mars. 多变量信号中的位移和2D旋转不变稀疏编码. IEEE信号处理汇刊,60:1597–1611,2012。
- Q. Barthélemy,A. Larue,和J.I. Mars. 3D轨迹的分解和字典学习. 信号处理,98:423–437,2014。
- Q. Barthélemy,C. Gouy-Pailler,Y. Isaac,A. Souloumiac,A. Larue,和J.I. Mars. EEG的多变量时间字典学习. 神经科学方法杂志,215:19–28,2013。
依赖关系
唯一的依赖关系是scikit-learn,matplotlib,numpy和scipy。
不需要安装。
示例
一个简单的示例是
import numpy as np
from mdla import MultivariateDictLearning
from mdla import multivariate_sparse_encode
from numpy.linalg import norm
rng_global = np.random.RandomState(0)
n_samples, n_features, n_dims = 10, 5, 3
X = rng_global.randn(n_samples, n_features, n_dims)
n_kernels = 8
dico = MultivariateDictLearning(n_kernels=n_kernels, max_iter=10).fit(X)
residual, code = multivariate_sparse_encode(X, dico)
print ('Objective error for each samples is:')
for i in range(len(residual)):
print ('Sample', i, ':', norm(residual[i], 'fro') + len(code[i]))
参考文献
- Chevallier, S.,Barthelemy, Q.,和Atif, J. (2014). 多变量字典的子空间度量及其在EEG中的应用. 在声学,语音和信号处理(ICASSP),IEEE国际会议(第7178-7182页)。
- Smith, E.,& Lewicki, M. S. (2005). 使用尖峰有效编码时间相对结构. 神经计算,17(1),19-45
- Chevallier, S.,Barthelemy, Q.,和Atif, J. (2014). 在字典学习评估中需要度量. 在欧洲信号处理会议(EUSIPCO),第1427-1431页。


下载文件
下载适用于您的平台的文件。如果您不确定选择哪一个,请了解更多关于安装包的信息。
源分布
mdla-1.0.2.tar.gz (32.4 kB 查看哈希值)
构建分布
mdla-1.0.2-py3-none-any.whl (31.0 kB 查看哈希值)
关闭
mdla-1.0.2.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 6a64948ccac93d0c611630fe354daf337fd404c0c8f70fe7402a774ff1d31273 |
|
| MD5 | 81236c6427522e8813d329bc20ce4095 |
|
| BLAKE2b-256 | ea11bf51b51ec91c5bd0eb8ca78cbcac38f2afff52491c43bea4d3154a36bcae |
关闭
mdla-1.0.2-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | b2c13d1649e1e7809ddc581f7545e466cec756e17eb229695ceee121e9c259e2 |
|
| MD5 | 49c30e7459dd987f3ba2195491354b97 |
|
| BLAKE2b-256 | 2b9f6ab2b806308c836074901578904c95f15eadefc8820baa5f347e26fea422 |







