官方llm2vec库


项目描述
LLM2Vec:大型语言模型是秘密强大的文本编码器





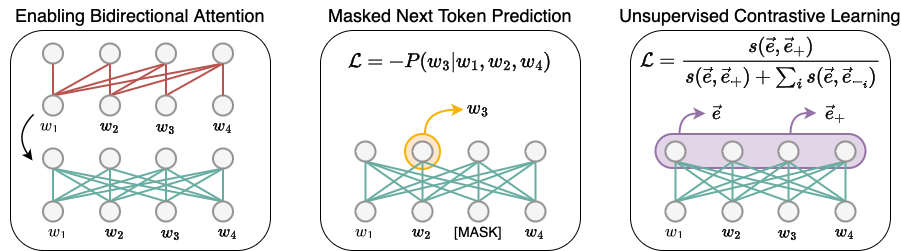
LLM2Vec是一种将仅解码器LLMs转换为文本编码器的简单方法。它包括3个简单步骤:1) 启用双向注意力,2) 使用掩码下一个标记预测进行训练,3) 无监督对比学习。该模型可以进一步微调以达到最先进的性能。
**************************** 更新 ****************************
-
04/07:添加了对Gemma和Qwen-2模型的支持,感谢@bzantium的贡献。
-
30/04:我们发布了LLM2Vec转换的Meta-Llama-3检查点。请参阅我们的HuggingFace收藏,包括监督和无监督版本。
安装
要使用LLM2Vec,首先从PyPI安装llm2vec包,然后安装flash-attention
pip install llm2vec
pip install flash-attn --no-build-isolation
您也可以通过克隆存储库直接安装llm2vec的最新版本
pip install -e .
pip install flash-attn --no-build-isolation
入门
LLM2Vec类是HuggingFace模型的一个包装器,用于在仅解码器的LLMs中启用双向性,序列编码和池化操作。以下步骤展示了如何使用该库的一个示例。
准备模型
使用预训练的LLMs初始化LLM2Vec模型非常简单。LLM2Vec的from_pretrained方法接受一个基本模型标识符/路径和一个可选的PEFT模型标识符/路径。所有HuggingFace模型加载参数都可以传递给from_pretrained方法。默认情况下,模型是带有双向连接加载的。可以通过将enable_bidirectional=False传递给from_pretrained方法来关闭此功能。
在这里,我们首先初始化Llama-3 MNTP基本模型,并加载未监督训练的LoRA权重(使用SimCSE目标和wiki语料库训练)。
import torch
from llm2vec import LLM2Vec
l2v = LLM2Vec.from_pretrained(
"McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp",
peft_model_name_or_path="McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp-unsup-simcse",
device_map="cuda" if torch.cuda.is_available() else "cpu",
torch_dtype=torch.bfloat16,
)
我们也可以通过更改peft_model_name_or_path来加载使用监督训练的LoRA权重(使用对比学习和公共E5数据训练)。
import torch
from llm2vec import LLM2Vec
l2v = LLM2Vec.from_pretrained(
"McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp",
peft_model_name_or_path="McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp-supervised",
device_map="cuda" if torch.cuda.is_available() else "cpu",
torch_dtype=torch.bfloat16,
)
默认情况下,LLM2Vec模型使用mean池化策略。您可以通过将pooling_mode参数传递给from_pretrained方法来更改池化策略。同样,您可以通过传递max_length参数来更改最大序列长度(默认为512)。
推理
此模型现在以[[instruction1, text1], [instruction2, text2]]或[text1, text2]的形式返回任何输入的文本嵌入。在训练时,我们为对称任务中的两个句子提供指令,只为非对称任务中的查询提供。
# Encoding queries using instructions
instruction = (
"Given a web search query, retrieve relevant passages that answer the query:"
)
queries = [
[instruction, "how much protein should a female eat"],
[instruction, "summit define"],
]
q_reps = l2v.encode(queries)
# Encoding documents. Instruction are not required for documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments.",
]
d_reps = l2v.encode(documents)
# Compute cosine similarity
q_reps_norm = torch.nn.functional.normalize(q_reps, p=2, dim=1)
d_reps_norm = torch.nn.functional.normalize(d_reps, p=2, dim=1)
cos_sim = torch.mm(q_reps_norm, d_reps_norm.transpose(0, 1))
print(cos_sim)
"""
tensor([[0.6470, 0.1619],
[0.0786, 0.5844]])
"""
更多关于分类、聚类、句子相似度等的示例请参见examples目录。
模型列表
| Meta-Llama-3-8B | Mistral-7B | Llama-2-7B | Sheared-Llama-1.3B | |
|---|---|---|---|---|
| Bi + MNTP | HF链接 | HF链接 | HF链接 | HF链接 |
| Bi + MNTP + SimCSE | HF链接 | HF链接** | HF链接 | HF链接 |
| Bi + MNTP + Supervised | HF链接* | HF链接 | HF链接 | HF链接 |
* 在基于公共数据训练的模型中,MTEB上的最先进状态
** 在MTEB上未监督的最先进状态
训练
MNTP训练
要使用掩码下一个标记预测(MNTP)训练模型,您可以使用experiments/run_mntp.py脚本。它是从HuggingFace掩码语言模型(MLM)脚本改编的。要使用MNTP训练Meta-Llama-3-8B模型,请运行以下命令
python experiments/run_mntp.py train_configs/mntp/MetaLlama3.json
Meta-Llama-3-8B训练配置文件包含我们在论文中使用的所有训练超参数和配置。
{
"model_name_or_path": "meta-llama/Meta-Llama-3-8B-Instruct",
"dataset_name": "wikitext",
"dataset_config_name": "wikitext-103-raw-v1",
"mask_token_type": "blank",
"data_collator_type": "default",
"mlm_probability": 0.2,
"lora_r": 16,
"gradient_checkpointing": true,
"torch_dtype": "bfloat16",
"attn_implementation": "flash_attention_2"
// ....
}
类似的配置也适用于Mistral-7B、Llama-2-7B和Sheared-Llama-1.3B模型。
无监督对比训练(SimCSE)
对于SimCSE训练,我们复制了SimCSE论文中的训练过程。对于训练,我们使用作者发布的包含100万句英文维基百科数据的集合。可以使用以下命令下载
wget https://hugging-face.cn/datasets/princeton-nlp/datasets-for-simcse/resolve/main/wiki1m_for_simcse.txt
要使用预设置配置的训练脚本,下载的文件应放在cache目录中。目录布局应如下所示
cache
└── wiki1m_for_simcse.txt
如果数据集放在不同的目录中,请相应地更改训练配置中的dataset_file_path。
要使用SimCSE训练Meta-Llama-3-8B模型,请运行以下命令
python experiments/run_simcse.py train_configs/simcse/MetaLlama3.json
Meta-Llama-3-8B训练配置文件包含我们在论文中使用的所有训练超参数和配置。
{
"model_name_or_path": "meta-llama/Meta-Llama-3-8B-Instruct",
"peft_model_name_or_path": "McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp",
"simcse_dropout": 0.3,
"bidirectional": true,
"pooling_mode": "mean",
"dataset_name": "Wiki1M",
"dataset_file_path": "cache/wiki1m_for_simcse.txt",
"learning_rate": 3e-5,
"loss_scale": 20,
"per_device_train_batch_size": 128,
"max_seq_length": 128,
"stop_after_n_steps": 1000,
"lora_r": 16,
"gradient_checkpointing": true,
"torch_dtype": "bfloat16",
"attn_implementation": "flash_attention_2",
// ....
}
类似的配置也适用于Mistral、Llama-2-7B和Sheared-Llama-1.3B模型。
监督对比训练
对于监督对比训练,我们使用了由《通过大型语言模型改进文本嵌入》一文的作者整理的公开数据集的一部分,该文发表于arXiv,并且由《重复改进语言模型嵌入》一文的作者整理,该文也发表于arXiv。数据集可以从Echo embeddings仓库的GitHub页面下载。要使用训练脚本,下载的数据集应放置在cache目录下。目录结构应如下所示
cache
|── wiki1m_for_simcse.txt
└── echo-data
├── allnli_split1.jsonl
├── allnli_split2.jsonl
├── allnli.jsonl
├── dureader.jsonl
...
如果数据集放置在不同的目录下,请相应地更改训练配置中的dataset_file_path。
要使用监督对比学习训练Meta-Llama-3-8B模型,请运行以下命令
torchrun --nproc_per_node=8 experiments/run_supervised.py train_configs/supervised/MetaLlama3.json
可以通过修改--nproc_per_node参数来更改GPU的数量。
Meta-Llama-3-8B的训练配置文件包含了我们论文中使用的所有训练超参数和配置。
{
"model_name_or_path": "meta-llama/Meta-Llama-3-8B-Instruct",
"peft_model_name_or_path": "McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp",
"bidirectional": true,
"pooling_mode": "mean",
"dataset_name": "E5",
"dataset_file_path": "cache/echo-data",
"learning_rate": 2e-4,
"num_train_epochs": 3,
"warmup_steps": 300,
"per_device_train_batch_size": 64,
"lora_r": 16,
"gradient_checkpointing": true,
"torch_dtype": "bfloat16",
"attn_implementation": "flash_attention_2"
// ....
}
类似配置也适用于Mistral、Llama-2-7B和Sheared-Llama-1.3B模型。
词级任务训练
为了对词级任务进行微调,我们在模型之上定义了一个分类器,并且只训练分类器的权重。代码来自HuggingFace的token分类示例。要训练和测试Llama-2-7B MNTP模型在pos_tags任务上的分类器,请运行以下命令
python experiments/run_word_task.py train_configs/word-task/Llama2-bi-mntp.json
python experiments/test_word_task.py --config_file test_configs/word-task/Llama2-bi-mntp.json
配置文件包含了我们论文中使用的所有参数和配置。例如,Llama2-bi-mntp.json包括
{
"model_name_or_path": "meta-llama/Llama-2-7b-chat-hf",
"peft_addr": "McGill-NLP/LLM2Vec-Llama-2-7b-chat-hf-mntp", // or any local directory containing `adapter_model` files.
"model_class": "custom",
"bidirectional": true,
"classifier_dropout": 0.1,
"merge_subwords": true,
"retroactive_labels": "next_token",
"output_dir": "output/word-task/pos_tags/Llama2/bi-mntp",
"dataset_name": "conll2003",
"task": "pos_tags", // or ner_tags, or chunk_tags
// ....
}
train_configs/word-task和test_configs/word-task包含了Llama-2-7B、Mistral-7B和Sheared-Llama-1.3B的所有Uni、Bi、Bi-MNTP和Bi-MNTP-SimCSE (LLM2Vec)变体的相似配置。
评估
MTEB评估
为了在MTEB基准上评估模型,我们使用experiments/mteb_eval.py脚本。该脚本需要mteb>=1.12.60等依赖项,可以使用以下命令安装。
pip install llm2vec[evaluation]
评估使用了在test_configs/mteb/task_to_instructions.json文件中提供的每个任务的指令。
要评估监督训练的Meta-Llama-3-8B模型在STS16任务上的性能,请运行以下命令
python experiments/mteb_eval.py --model_name McGill-NLP/LLM2Vec-Meta-Llama-3-8B-Instruct-mntp-supervised \
--task_name STS16 \
--task_to_instructions_fp test_configs/mteb/task_to_instructions.json \
--output_dir results
评估脚本支持HuggingFace收藏夹中所有可用的模型。
引用
如果您觉得我们的工作对您有帮助,请引用我们
@article{llm2vec,
title={{LLM2Vec}: {L}arge Language Models Are Secretly Powerful Text Encoders},
author={Parishad BehnamGhader and Vaibhav Adlakha and Marius Mosbach and Dzmitry Bahdanau and Nicolas Chapados and Siva Reddy},
year={2024},
journal={arXiv preprint},
url={https://arxiv.org/abs/2404.05961}
}
有疑问或错误?
如果您对代码有任何疑问,请自由地在GitHub仓库上创建问题。


下载文件
下载适用于您的平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。