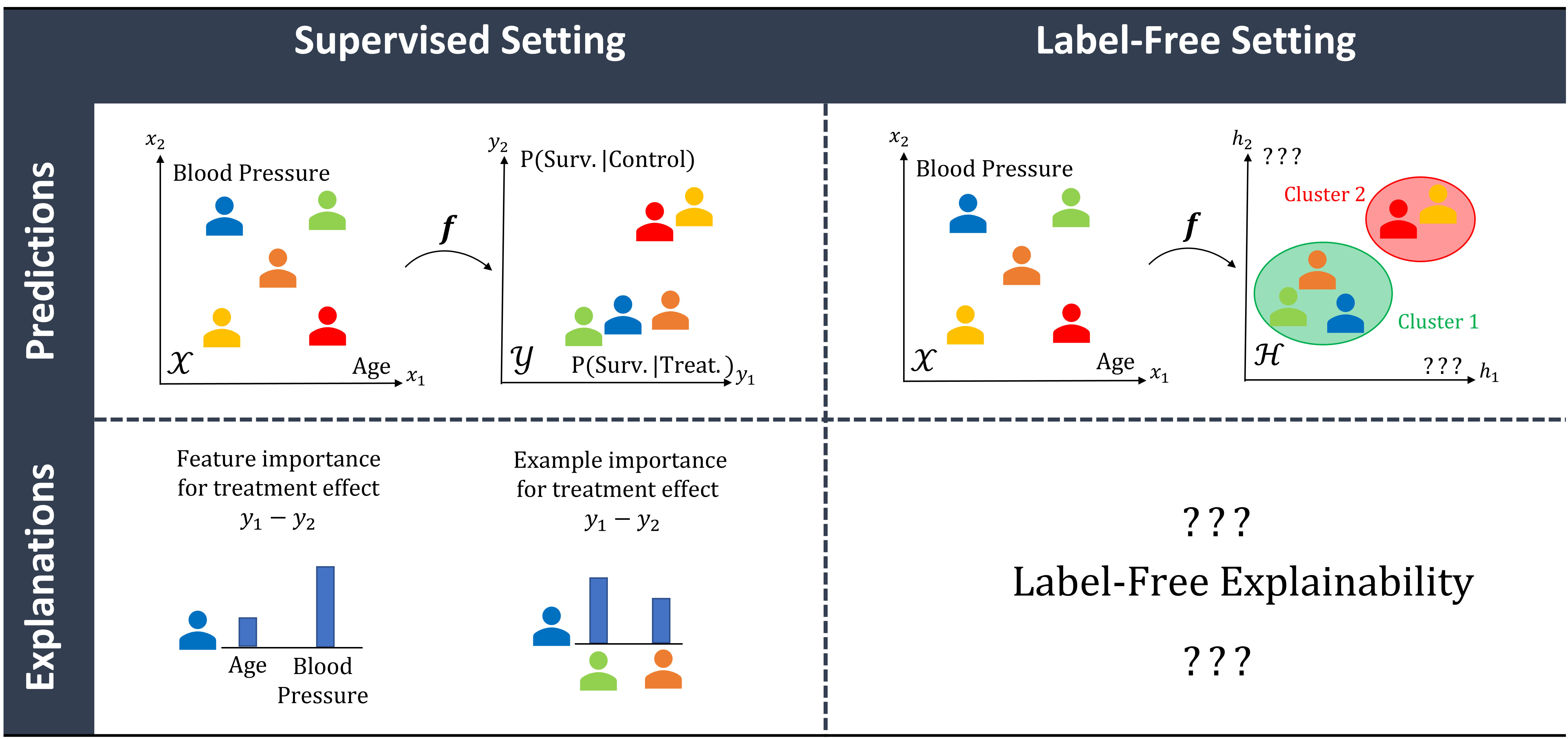
一个利用常用特征重要性和基于实例的方法,帮助解释无监督黑盒模型潜在表示的框架。



项目描述
无标签XAI



代码作者:Jonathan Crabbé (jc2133@cam.ac.uk)
此存储库包含LFXAI的实现,一个利用常用特征重要性和基于实例的方法来解释无监督黑盒模型潜在表示的框架。有关更多详情,请阅读我们的ICML 2022论文:"无标签模型的解释性"。
1. 安装
从PyPI
pip install lfxai
从仓库
- 克隆仓库
- 使用Python 3.8创建新的虚拟环境
- 从仓库文件夹运行以下命令
pip install .
当包安装完毕后,您就可以解释无监督模型了。
2. 示例
以下是一个玩具演示,其中我们使用MNIST自动编码器计算无标签特征和示例重要性。相关代码可在说明文件夹中找到。
import torch
from pathlib import Path
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, Subset
from torchvision import transforms
from torch.nn import MSELoss
from captum.attr import IntegratedGradients
from lfxai.models.images import AutoEncoderMnist, EncoderMnist, DecoderMnist
from lfxai.models.pretext import Identity
from lfxai.explanations.features import attribute_auxiliary
from lfxai.explanations.examples import SimplEx
# Select torch device
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# Load data
data_dir = Path.cwd() / "data/mnist"
train_dataset = MNIST(data_dir, train=True, download=True)
test_dataset = MNIST(data_dir, train=False, download=True)
train_dataset.transform = transforms.Compose([transforms.ToTensor()])
test_dataset.transform = transforms.Compose([transforms.ToTensor()])
train_loader = DataLoader(train_dataset, batch_size=100)
test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False)
# Get a model
encoder = EncoderMnist(encoded_space_dim=10)
decoder = DecoderMnist(encoded_space_dim=10)
model = AutoEncoderMnist(encoder, decoder, latent_dim=10, input_pert=Identity())
model.to(device)
# Get label-free feature importance
baseline = torch.zeros((1, 1, 28, 28)).to(device) # black image as baseline
attr_method = IntegratedGradients(model)
feature_importance = attribute_auxiliary(encoder, test_loader,
device, attr_method, baseline)
# Get label-free example importance
train_subset = Subset(train_dataset, indices=list(range(500))) # Limit the number of training examples
train_subloader = DataLoader(train_subset, batch_size=500)
attr_method = SimplEx(model, loss_f=MSELoss())
example_importance = attr_method.attribute_loader(device, train_subloader, test_loader)
3. 重复论文结果
MNIST实验
在experiments文件夹中运行以下脚本
python -m mnist --name experiment_name
其中 experiment_name 可以取以下值
| experiment_name | 描述 |
|---|---|
| consistency_features | 无标签的一致性检查 特征重要性(论文第4.1节) |
| consistency_examples | 无标签的一致性检查 示例重要性(论文第4.1节) |
| roar_test | 无标签的ROAR测试 特征重要性(论文附录C) |
| pretext | 预训练任务敏感性 用例(论文第4.2节) |
| disvae | 用解耦VAEs挑战假设 (论文第4.3节) |
生成的图表和数据保存在这里。
ECG5000实验
运行以下脚本
python -m ecg5000 --name experiment_name
其中 experiment_name 可以取以下值
| experiment_name | 描述 |
|---|---|
| consistency_features | 无标签的一致性检查 特征重要性(论文第4.1节) |
| consistency_examples | 无标签的一致性检查 示例重要性(论文第4.1节) |
生成的图表和数据保存在这里。
CIFAR10实验
运行以下脚本
python -m cifar10
可以通过更改此文件中的 experiment_name 参数来选择实验。参数可以取以下值
| experiment_name | 描述 |
|---|---|
| consistency_features | 无标签的一致性检查 特征重要性(论文第4.1节) |
| consistency_examples | 无标签的一致性检查 示例重要性(论文第4.1节) |
生成的图表和数据保存在这里。
dSprites实验
运行以下脚本
python -m dsprites
由于需要训练多个VAEs,该实验运行需要几个小时。生成的图表和数据保存在这里。
4. 引用
如果您使用此代码,请引用相关论文
@misc{Crabbe2022LFXAI,
doi = {10.48550/ARXIV.2203.01928},
url = {https://arxiv.org/abs/2203.01928},
author = {Crabbé, Jonathan and van der Schaar, Mihaela},
keywords = {Machine Learning (cs.LG), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Label-Free Explainability for Unsupervised Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。
源分发
此版本没有提供源分发文件。请参阅生成分发存档的教程。
构建分发
lfxai-0.1.1-py3-none-any.whl (32.0 kB 查看散列)
关闭
散列 for lfxai-0.1.1-py3-none-macosx_10_14_x86_64.whl
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 81d7cff725fceb5d76fd4c6c4ebc9f3ad783031a1f8545d01dccd66807df00df |
|
| MD5 | f80e939904cef1d718d21d1f8705d063 |
|
| BLAKE2b-256 | e8c4bc1b5829c29c87765c88161e4893a9d9284deb3f59c69a45a4f44b93e59e |







