NebulaGraph的Jupyter扩展


项目描述









https://github.com/wey-gu/jupyter_nebulagraph/assets/1651790/10135264-77b5-4d3c-b68f-c5810257feeb
jupyter_nebulagraph,之前称为ipython-ngql,是一个Python包,它简化了从Jupyter Notebooks或iPython环境连接到NebulaGraph的过程。它通过简化Jupyter Notebooks的创建、调试和共享来增强用户体验。使用jupyter_nebulagraph,用户可以轻松连接到NebulaGraph,加载数据,执行查询,可视化结果,并微调查询输出,从而提高协作效率和生产力。
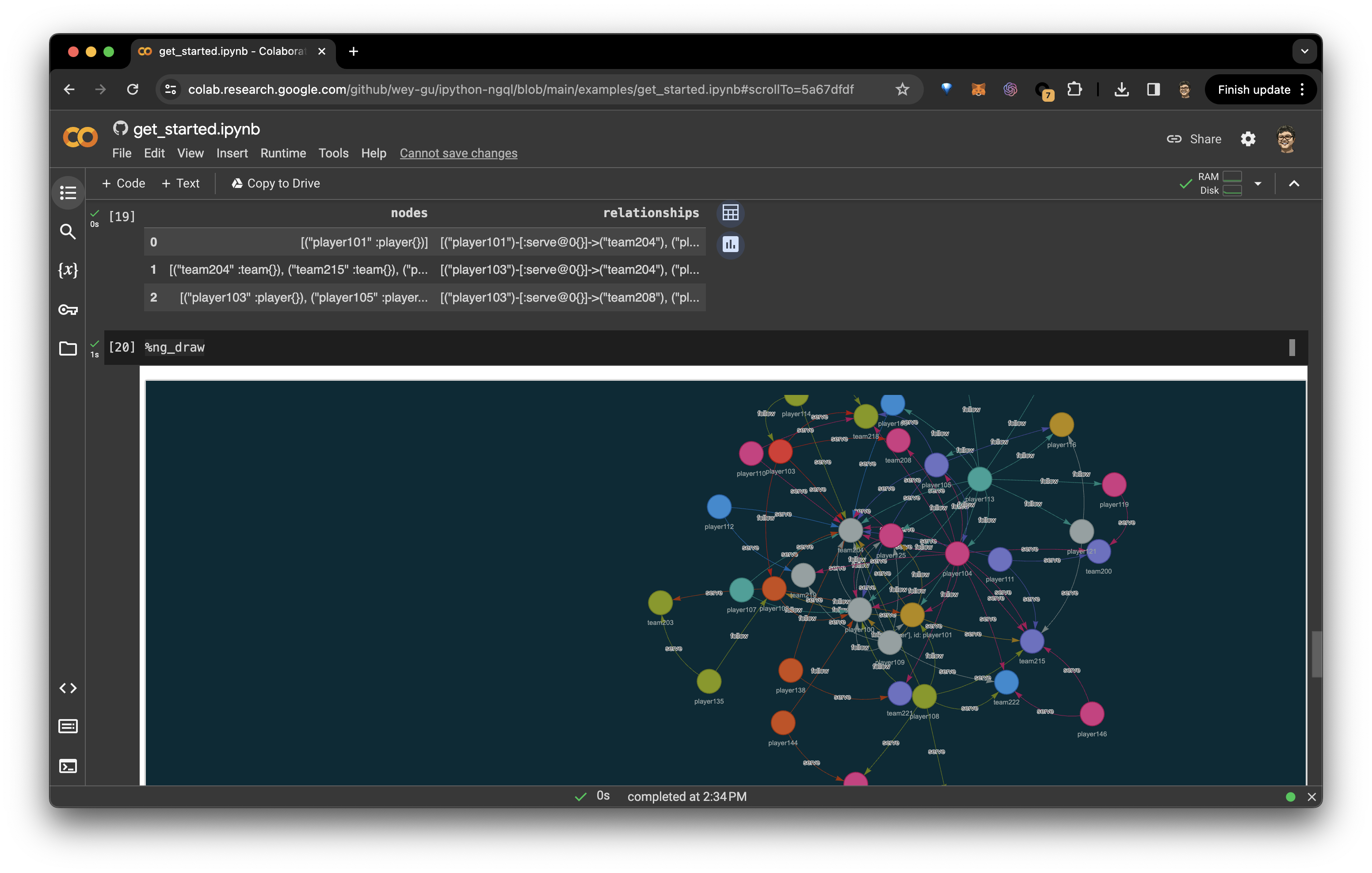
入门指南
pip install jupyter_nebulagraph
在Jupyter Notebook或iPython中加载扩展
%load_ext ngql
%ngql --address 127.0.0.1 --port 9669 --user root --password nebula
进行查询
%ngql USE basketballplayer;
%ngql MATCH p=(v:player)-->(v2:player) WHERE id(v) == "player100" RETURN p;
绘制图形
%ng_draw
通过在Google Colab上对其进行实验来发现jupyter_nebulagraph的功能。您也可以在文档中找到类似的Jupyter Notebook 此处。
有关详细指南,请参阅官方文档。
| 功能 | 速查表 | 示例 | 命令文档 |
|---|---|---|---|
| 连接 | %ngql --address 127.0.0.1 --port 9669 --user user --password password |
连接 | %ngql |
| 从CSV加载数据 | %ng_load --source actor.csv --tag player --vid 0 --props 1:name,2:age --space basketballplayer |
加载数据 | %ng_load |
| 查询执行 | %ngql MATCH p=(v:player{name:"Tim Duncan"})-->(v2:player) RETURN p; |
查询执行 | 使用%ngql或%%ngql(多行) |
| 结果可视化 | %ng_draw |
绘制图 | %ng_draw |
| 绘制模式 | %ng_draw_schema |
绘制模式 | %ng_draw_schema |
| 调整查询结果 | df = _以获取最后查询结果作为pd.dataframe或ResultSet |
调整结果 | 配置ngql_result_style |
点击查看更多!
安装
jupyter_nebulagraph可以通过pip安装,也可以从本git仓库本身安装。
通过pip安装
pip install jupyter_nebulagraph
在仓库内安装
git clone git@github.com:wey-gu/jupyter_nebulagraph.git
cd jupyter_nebulagraph
python setup.py install
在Jupyter Notebook或iPython中加载它
%load_ext ngql
连接到NebulaGraph
以下参数是连接NebulaGraph数据库实例所需的
| 参数 | 描述 |
|---|---|
--address或-addr |
NebulaGraph实例的IP地址 |
--port或-P |
NebulaGraph实例的端口号 |
--user或-u |
用户名 |
--password或-p |
密码 |
以下是如何连接到127.0.0.1:9669,用户名为"user",密码为"password"的示例。
%ngql --address 127.0.0.1 --port 9669 --user user --password password
执行查询
现在支持两种iPtython魔幻
选项1:一行类型的%ngql
%ngql USE basketballplayer;
%ngql MATCH (v:player{name:"Tim Duncan"})-->(v2:player) RETURN v2.player.name AS Name;
选项2:多行类型的%%ngql
%%ngql
SHOW TAGS;
SHOW HOSTS;
包含变量的查询字符串
jupyter_nebulagraph支持从本地命名空间中获取变量,通过Jinja2模板框架的帮助,支持查询如下示例。
实际的查询字符串应该是GO FROM "Sue" OVER owns_pokemon ...,并且"{{ trainer }}"通过消费本地变量trainer被渲染为"Sue"
In [8]: vid = "player100"
In [9]: %%ngql
...: MATCH (v)<-[e:follow]- (v2)-[e2:serve]->(v3)
...: WHERE id(v) == "{{ vid }}"
...: RETURN v2.player.name AS FriendOf, v3.team.name AS Team LIMIT 3;
Out[9]: RETURN v2.player.name AS FriendOf, v3.team.name AS Team LIMIT 3;
FriendOf Team
0 LaMarcus Aldridge Trail Blazers
1 LaMarcus Aldridge Spurs
2 Marco Belinelli Warriors
绘制查询结果
绘制最后查询
在具有图形数据的查询后调用%ng_draw
# one query
%ngql GET SUBGRAPH 2 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships;
%ng_draw
# another query
%ngql match p=(:player)-[]->() return p LIMIT 5
%ng_draw
绘制查询
或使用%ng_draw <one_line_query>,%%ng_draw <multiline_query>来代替绘制最后查询的结果。
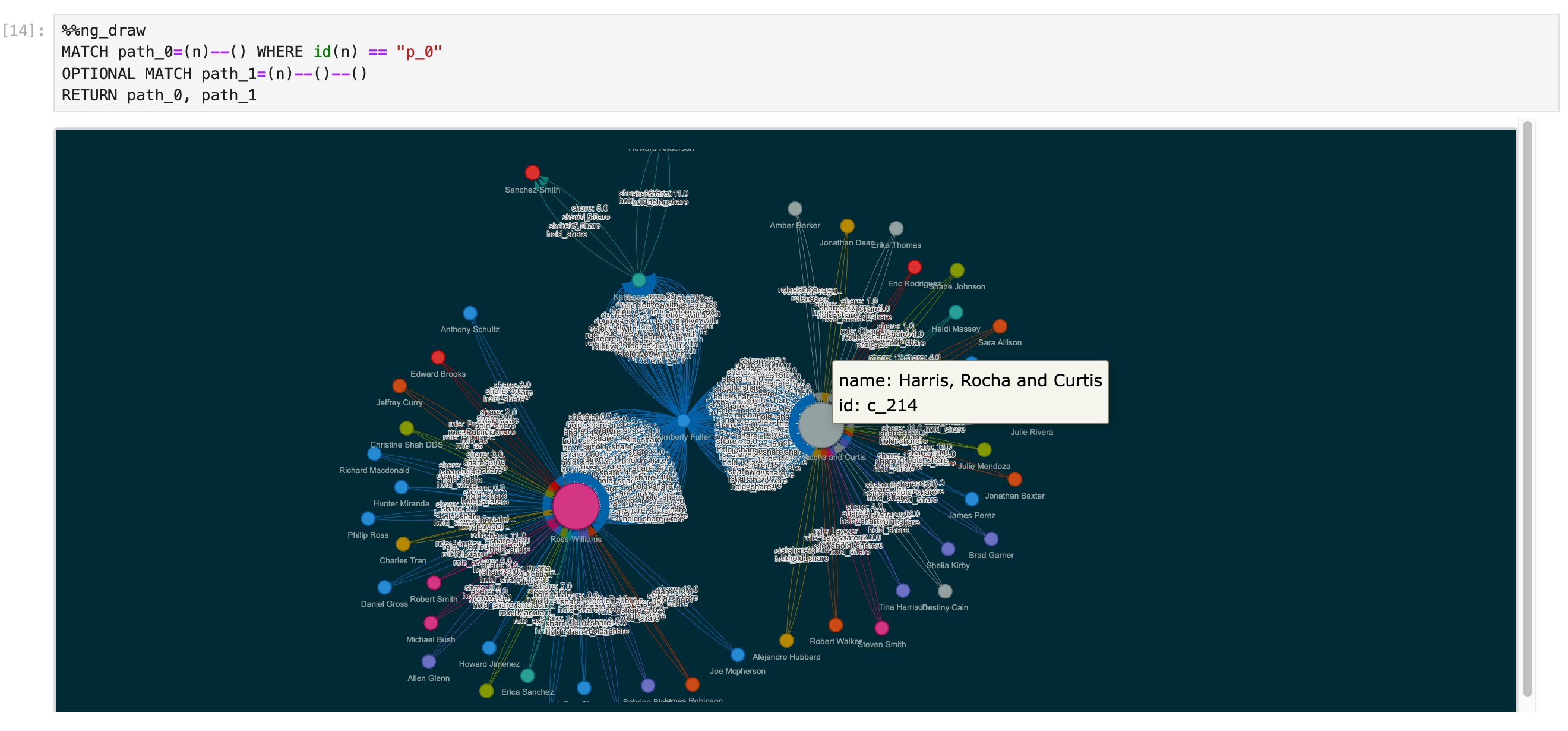
一行查询
%ng_draw GET SUBGRAPH 2 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships;
多行查询
%%ng_draw
MATCH path_0=(n)--() WHERE id(n) == "p_0"
OPTIONAL MATCH path_1=(n)--()--()
RETURN path_0, path_1
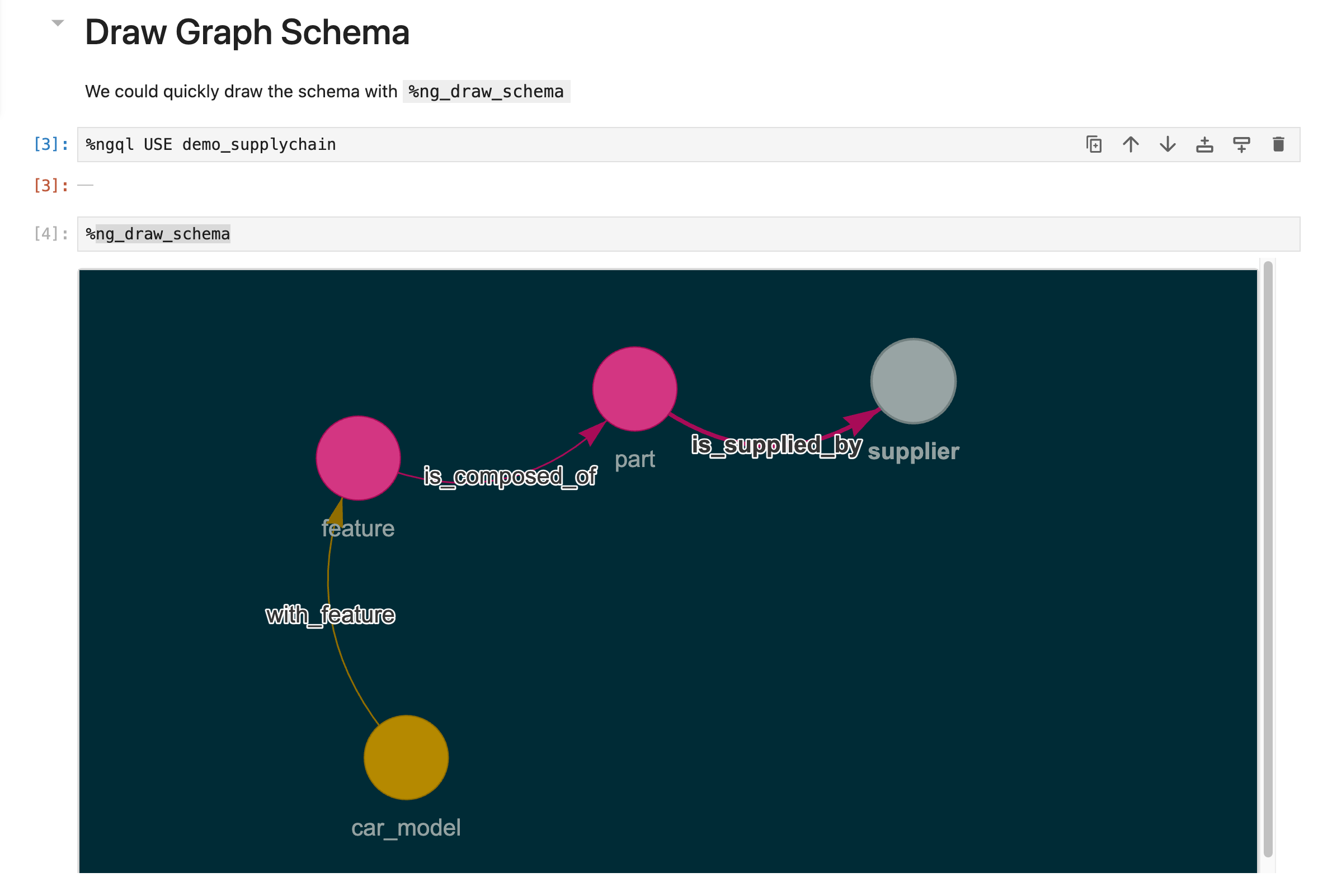
绘制图模式
%ng_draw_schema
从CSV加载数据
通过ng_load_csv魔幻的帮助,可以支持将数据从CSV文件加载到NebulaGraph中。
例如,将CSV文件actor.csv中的数据加载到空间basketballplayer中,标签为player,vid在列0,属性在列1和2中
"player999","Tom Hanks",30
"player1000","Tom Cruise",40
"player1001","Jimmy X",33
只需运行以下行
%ng_load --source actor.csv --tag player --vid 0 --props 1:name,2:age --space basketballplayer
一些其他示例
# load CSV from a URL
%ng_load --source https://github.com/wey-gu/jupyter_nebulagraph/raw/main/examples/actor.csv --tag player --vid 0 --props 1:name,2:age --space demo_basketballplayer
# with rank column
%ng_load --source follow_with_rank.csv --edge follow --src 0 --dst 1 --props 2:degree --rank 3 --space basketballplayer
# without rank column
%ng_load --source follow.csv --edge follow --src 0 --dst 1 --props 2:degree --space basketballplayer
调整查询结果
默认情况下,查询结果是Pandas Dataframe,我们可以通过从变量_中读取来访问它。
In [1]: %ngql MATCH (v:player{name:"Tim Duncan"})-->(v2:player) RETURN v2.player.name AS Name;
In [2]: df = _
还可以配置结果以在原始ResultSet中,以启用便捷的NebulaGraph Python应用程序开发。
有关更多信息,请参阅文档:结果处理
速查表
如果你发现自己忘记了命令或者不希望完全依赖速查表,请记住这一点:通过帮助命令寻求帮助!
%ngql help
致谢♥️
- 本项目的灵感来自ipython-sql,归功于Catherine Devlin。
- 图可视化功能由pyvis提供,这是一个由WestHealth的项目。
- 由Vesoft Inc.和NebulaGraph社区提供了慷慨的赞助和支持。


下载文件
下载适用于您平台文件的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源代码分发
构建分发
jupyter_nebulagraph-0.14.3.tar.gz的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | b3470498d0a6fb9fcbc46cb4c4a8a8e4ecc1de7805465e0c752b6f00a8ab1ab6 |
|
| MD5 | b66c586c80ea3256d295b8b63e3d432b |
|
| BLAKE2b-256 | b3071128e2826311254a37279553928594ec790430ecb2dc3ca5f950dad88669 |
jupyter_nebulagraph-0.14.3-py3-none-any.whl的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 48edb1bf3f7afa67e7d5ee6c05edf40ba7d977ab4dbadee9b169b8aa0f0cb60d |
|
| MD5 | b73b0d14e0d3dc8738ac4324f9b720dc |
|
| BLAKE2b-256 | a7bb98964c4e4d0cb1702d41a4ec3d359f08e5f4fdad5d578ff0177ca446e614 |