通过IPython访问InfluxDB


项目描述

- 作者:
Robert Hajek, Bonitoo.io
引入了 %flux (或 %%flux) 魔法。
通过IPython或IPython Notebook连接到InfluxDB并运行Flux命令。
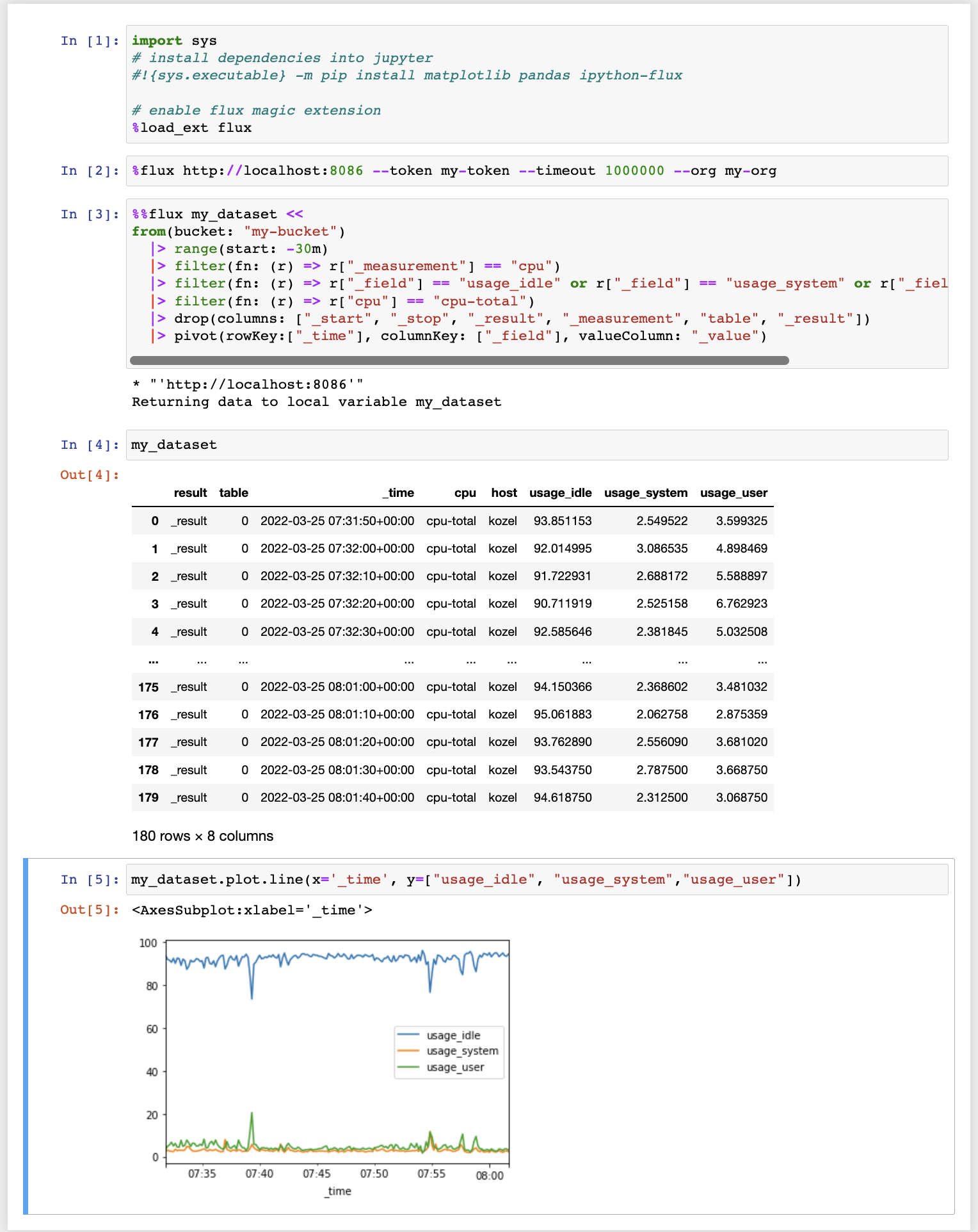
示例
In [1]: %load_ext flux
In [2]: %%flux http://localhost:9999 --token "my-token" --org my-org
...: from(bucket: "apm_metricset")
...: |> range(start: v.timeRangeStart, stop: v.timeRangeStop)
...: |> filter(fn: (r) => r["_measurement"] == "apm_metricset")
...: |> filter(fn: (r) => r["_field"] == "samples_system.process.cpu.total.norm.pct")
...:
Out[2]: ...第一次连接后,可以省略连接信息
In [3]: %flux ...: from(bucket: "apm_metricset") ...: |> range(start: v.timeRangeStart, stop: v.timeRangeStop) ...: |> filter(fn: (r) => r["_measurement"] == "apm_metricset") ...: |> filter(fn: (r) => r["_field"] == "samples_system.process.cpu.total.norm.pct") Out[8]: ...
如果没有提供连接字符串,%flux 将使用环境变量 INFLUXDB_V2_URL、INFLUXDB_V2_ORG、INFLUXDB_V2_TOKEN 来创建到InfluxDB的连接。
常规IPython赋值适用于单行 %flux 查询
In [12]: result = %flux from(bucket: "my-bucket") |> range(start: 0)<< 运算符将查询结果捕获到局部变量中,并可用于多行 %%flux
In [19]: %%flux my_dataset <<
...: from(bucket: "my-bucket")
...: |> range(start: -30m)
...: |> filter(fn: (r) => r["_measurement"] == "cpu")
...: |> filter(fn: (r) => r["_field"] == "usage_idle" or r["_field"] == "usage_system" or r["_field"] == "usage_user")
...: |> filter(fn: (r) => r["cpu"] == "cpu-total")
...: |> drop(columns: ["_start", "_stop", "_result", "_measurement", "table", "_result"])
...: |> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")Flux命令的结果将自动转换为Pandas数据框。通常使用Flux函数 fieldsAsCol() 或 pivot() 将包含多个时间序列的数据转换为单个数据集很有用。
持久化数据框
使用内存中DataFrame对象的名称的--persist参数将在数据库中创建一个从命名DataFrame生成的测量。
In [1]: %flux --persist <data_frame_variable_name> --bucket my-bucket --measurement <new measurement name> --tags tag_column1,tag_column2选项
-l/--connections列出所有活动连接
-t/--tokenInfluxDB令牌
-o/--orgInfluxDB组织
--timeoutInfluxDB查询超时(以毫秒为单位,默认超时为10_000毫秒)
-f/--file<路径>从该路径运行Flux文件
-x/--close<会话名称>关闭命名连接
持久化选项
-p/--persist从命名DataFrame创建数据库中的测量
-b/--bucket目标存储桶名称
-T/--tags以逗号分隔的列列表,这些列将存储为标签,其余列将存储为字段
-m/--measurement可选的,目标测量名称,如果未指定,则从DataFrame名称中获取测量
安装
使用以下命令安装最新版本
pip install ipython-flux
或从https://github.com/bonitoo-io/ipython-flux下载,并
cd ipython-flux sudo python setup.py install
使用以下命令在Jupyter笔记本中启用IPython flux魔法扩展
In [1]: %load_ext flux开发
新闻
0.0.6
发布日期:2022-11-06
#5 - 修复
setup.py格式化
0.0.5
发布日期:2022-03-25
0.0.4
发布日期:2020-08-18
#1:修复以“-”开头的令牌参数
0.0.3
发布日期:2020-08-12
更新tox.ini和要求依赖项
0.0.2
发布日期:2020-08-06
修复从环境变量创建连接
添加将DataFrame持久化到InfluxDB的功能
0.0.1
发布日期:2020-07-21
初始版本


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解更多关于安装包的信息。
源分发
构建分发
ipython-flux-0.0.6.tar.gz 的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 113d0281e92a4ea45e57c031105f90526d5afe6798be2db205ba96228a7e5657 |
|
| MD5 | 40e722040f2d42836caab72d5646036d |
|
| BLAKE2b-256 | 82ad0f527dcac184ae70d158c2b62d886e00d4390a325816c555408c98342440 |
ipython_flux-0.0.6-py3-none-any.whl 的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 1d6b18530f99a5f7293f9cc609780a3df1ae815a0ec0c7ad7d6e108d97fb5983 |
|
| MD5 | 1ea7c9690b4aa81b509cb973485a9f4a |
|
| BLAKE2b-256 | 47644b82a4b60682e73d07e9ffc2b3b2e973475299b169d0356d556d29cd0974 |