inscriptis - HTML到文本转换器。



项目描述








A python based HTML to text conversion library, command line client and Web service with support for nested tables, a subset of CSS and optional support for providing an annotated output.
Inscriptis is particularly well suited for applications that require high-performance, high-quality (i.e., layout-aware) text representations of HTML content, and will aid knowledge extraction and data science tasks conducted upon Web data.
请查看渲染文档,以了解inscriptis转换质量演示。
inscriptis 1.x的Java端口已由x28发布。
本文档简要介绍了Inscriptis。
完整文档自动构建并发布在Read the Docs上。
如果您对从HTML中提取文本的主题感兴趣,这篇关于不同HTML到文本转换方法和选择标准的博客文章可能对您有所帮助。
需求声明 - 为什么选择inscriptis?
Inscriptis提供了一种布局感知的HTML转换,这种转换更接近标准Web浏览器的渲染效果,因此更好地保留了文本元素的布局。
一旦需要超出简单的HTML片段,转换质量就会成为一个因素。非专业的方法和不太复杂的库不能正确解释HTML语义,因此无法正确转换如列表、枚举和表格等结构。
例如,Beautiful Soup的get_text()函数将以下HTML枚举转换为字符串firstsecond。
<ul> <li>first</li> <li>second</li> <ul>相比之下,Inscriptis不仅返回正确的输出
* first * second还支持更复杂的结构,如嵌套表格,并解释了HTML(例如,align、valign)和CSS(例如,display、white-space、margin-top、vertical-align等)属性,这些属性决定了文本对齐方式。任何文本的空间对齐相关的情况(例如,对于许多知识提取任务,计算词嵌入和语言模型,以及情感分析)都需要准确的HTML到文本转换。
Inscriptis支持注释规则,即用户提供的映射,允许根据HTML标签和属性中编码的结构和语义信息注释提取的文本。这些规则可以用于
为下游知识提取组件提供额外的信息,这些信息可能有助于提高它们各自的性能。
协助手动文档注释过程(例如,用于定性分析或黄金标准创建)。Inscriptis支持多种导出格式,如XML、注释HTML和由开源注释工具doccano使用的JSONL格式。
启用对Inscriptis的使用,以便执行内容提取等任务(例如,从网页中提取特定任务的相关内容),这些任务依赖于HTML文档结构的详细信息。
安装
在命令行中
$ pip install inscriptis
或者,如果您还没有安装pip
$ easy_install inscriptis
Python库
如以下所述,将Inscriptis嵌入到您的代码中非常简单
import urllib.request
from inscriptis import get_text
url = "https://www.fhgr.ch"
html = urllib.request.urlopen(url).read().decode('utf-8')
text = get_text(html)
print(text)独立命令行客户端
命令行客户端将HTML文件或从网页检索的文本转换为相应的文本表示。
命令行参数
Inscriptis命令行客户端支持以下参数
usage: inscript [-h] [-o OUTPUT] [-e ENCODING] [-i] [-d] [-l] [-a] [-r ANNOTATION_RULES] [-p POSTPROCESSOR] [--indentation INDENTATION]
[--table-cell-separator TABLE_CELL_SEPARATOR] [-v]
[input]
Convert the given HTML document to text.
positional arguments:
input Html input either from a file or a URL (default:stdin).
optional arguments:
-h, --help show this help message and exit
-o OUTPUT, --output OUTPUT
Output file (default:stdout).
-e ENCODING, --encoding ENCODING
Input encoding to use (default:utf-8 for files; detected server encoding for Web URLs).
-i, --display-image-captions
Display image captions (default:false).
-d, --deduplicate-image-captions
Deduplicate image captions (default:false).
-l, --display-link-targets
Display link targets (default:false).
-a, --display-anchor-urls
Display anchor URLs (default:false).
-r ANNOTATION_RULES, --annotation-rules ANNOTATION_RULES
Path to an optional JSON file containing rules for annotating the retrieved text.
-p POSTPROCESSOR, --postprocessor POSTPROCESSOR
Optional component for postprocessing the result (html, surface, xml).
--indentation INDENTATION
How to handle indentation (extended or strict; default: extended).
--table-cell-separator TABLE_CELL_SEPARATOR
Separator to use between table cells (default: three spaces).
-v, --version display version information
HTML到文本转换
将给定页面转换为文本并输出到屏幕
$ inscript https://www.fhgr.ch
将文件转换为文本并将其输出保存到fhgr.txt
$ inscript fhgr.html -o fhgr.txt
使用严格的缩进(即最小化缩进和额外空格)将文件转换为文本并将其输出保存到fhgr-layout-optimized.txt
$ inscript --indentation strict fhgr.html -o fhgr-layout-optimized.txt
将通过stdin提供的HTML转换为文本并将其输出保存到output.txt
$ echo "<body><p>Make it so!</p></body>" | inscript -o output.txt
HTML到注释文本转换
使用提供的注释规则转换并注释网页中的HTML
下载示例annotation-profile.json并将其保存到您的当前工作目录
$ inscript https://www.fhgr.ch -r annotation-profile.json
注释规则在annotation-profile.json中指定
{
"h1": ["heading", "h1"],
"h2": ["heading", "h2"],
"b": ["emphasis"],
"div#class=toc": ["table-of-contents"],
"#class=FactBox": ["fact-box"],
"#cite": ["citation"]
}字典将HTML标签和/或属性映射到Inscriptis应为其提供的注释。例如,在上面的示例中,标签h1产生注释heading和h1,具有包含值toc的类的div标签产生注释table-of-contents,并且所有具有 cite属性的标签都注释为citation。
给定这些注释规则,HTML文件
<h1>Chur</h1>
<b>Chur</b> is the capital and largest town of the Swiss canton of the
Grisons and lies in the Grisonian Rhine Valley.产生以下JSONL输出
{"text": "Chur\n\nChur is the capital and largest town of the Swiss canton
of the Grisons and lies in the Grisonian Rhine Valley.",
"label": [[0, 4, "heading"], [0, 4, "h1"], [6, 10, "emphasis"]]}提供的标签列表包含所有注释文本元素及其起始索引、结束索引和分配的标签。
注释后处理器
注释后处理器允许对注释进行后处理,以生成适合您特定应用的格式。后处理器可以通过-p或--postprocessor命令行参数指定
$ inscript https://www.fhgr.ch \
-r ./annotation/examples/annotation-profile.json \
-p surface
输出
{"text": " Chur\n\n Chur is the capital and largest town of the Swiss
canton of the Grisons and lies in the Grisonian Rhine Valley.",
"label": [[0, 6, "heading"], [8, 14, "emphasis"]],
"tag": "<heading>Chur</heading>\n\n<emphasis>Chur</emphasis> is the
capital and largest town of the Swiss canton of the Grisons and
lies in the Grisonian Rhine Valley."}目前,inscriptis支持以下后处理器
surface:返回注释的表面形式和其标签之间的映射列表
[ ['heading', 'Chur'], ['emphasis': 'Chur'] ]
xml:返回一个附加的注释文本版本
<?xml version="1.0" encoding="UTF-8" ?> <heading>Chur</heading> <emphasis>Chur</emphasis> is the capital and largest town of the Swiss canton of the Grisons and lies in the Grisonian Rhine Valley.
html:创建一个包含转换文本并突出显示所有注释的HTML文件,如下所述
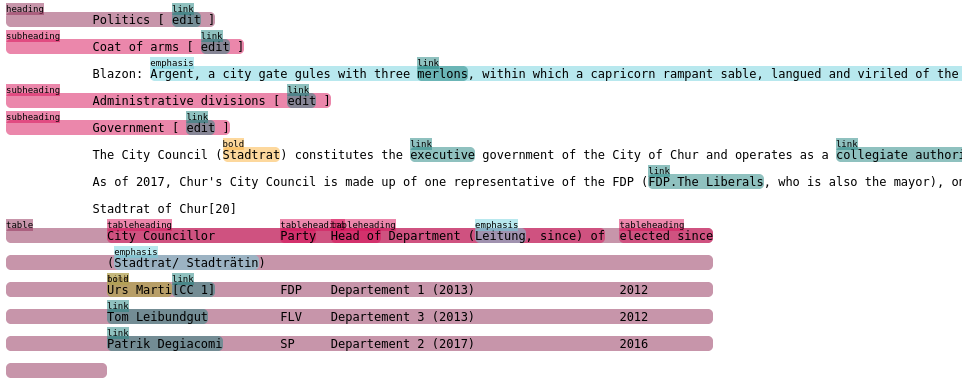
使用以下命令行选项和注释规则创建的渲染HTML文件的片段
inscript --annotation-rules ./wikipedia.json \
--postprocessor html \
https://en.wikipedia.org/wiki/Chur.html在wikipedia.json文件中编码的注释规则
{
"h1": ["heading"],
"h2": ["heading"],
"h3": ["subheading"],
"h4": ["subheading"],
"h5": ["subheading"],
"i": ["emphasis"],
"b": ["bold"],
"table": ["table"],
"th": ["tableheading"],
"a": ["link"]
}Web服务
一个基于FastAPI的Web服务,使用Inscriptis将HTML页面转换为纯文本。
在您的宿主系统上运行Web服务
为inscriptis安装可选功能web-service
$ pip install inscriptis[web-service]
使用以下命令启动Inscriptis Web服务
$ uvicorn inscriptis.service.web:app --port 5000 --host 127.0.0.1
使用Docker运行Web服务
Docker定义可以在此处找到
$ docker pull ghcr.io/weblyzard/inscriptis:latest $ docker run -n inscriptis ghcr.io/weblyzard/inscriptis:latest
作为Kubernetes部署运行
用于在kubernetes集群上部署的helm图表位于inscriptis-helm存储库中。
使用Web服务
Web服务接收请求正文中包含的HTML文件并返回相应的文本。需要在Content-Type头中指定文件的编码(以下示例中的UTF-8)
$ curl -X POST -H "Content-Type: text/html; encoding=UTF8" \
--data-binary @test.html https://:5000/get_text
该服务还支持版本调用
$ curl https://:5000/version
示例注释配置文件
以下部分提供了多个示例注释配置文件,说明了Inscriptis注释支持的使用。示例展示了使用的注释规则和图像,该图像突出显示了在转换为网页上创建的注释文本的片段,该网页使用HTML后处理器创建,如第注释后处理器部分所述。
维基百科表格及其元数据
以下注释规则从维基百科页面中提取表格,并注释通常用于表示列或行标题的表格标题。
{
"table": ["table"],
"th": ["tableheading"],
"caption": ["caption"]
}以下图表概述了一个来自维基百科的示例表格,该表格已使用这些规则进行了注释。

来自维基百科的实体引用、缺失实体和引文
此配置文件提取了维基百科实体、缺失实体和引文的引用。请注意,此配置文件并不完美,因为它还注释了[编辑]链接。
{
"a#title": ["entity"],
"a#class=new": ["missing"],
"class=reference": ["citation"]
}该图显示了使用这些规则在维基百科页面上识别出的实体和引文。

来自XDA开发者论坛的帖子及其元数据
以下注释规则从XDA开发者论坛中提取带有帖子的时间、用户和用户职称等元数据的帖子。
{
"article#class=message-body": ["article"],
"li#class=u-concealed": ["time"],
"#itemprop=name": ["user-name"],
"#itemprop=jobTitle": ["user-title"]
}该图说明了XDA开发者论坛帖子上的注释元数据。

来自Stackoverflow页面的代码及其元数据
以下规则提取了Stackoverflow页面上的代码和用户及评论的元数据。
{
"code": ["code"],
"#itemprop=dateCreated": ["creation-date"],
"#class=user-details": ["user"],
"#class=reputation-score": ["reputation"],
"#class=comment-date": ["comment-date"],
"#class=comment-copy": ["comment-comment"]
}将这些规则应用于从HTML中提取文本的Stackoverflow页面,可以得到以下片段

高级主题
注释文本
Inscriptis可以提供与提取文本一起的注释,这使得下游组件可以利用仅在原始HTML文件中可用的语义。
提取的文本和注释可以以不同的格式导出,包括流行的JSONL格式,该格式由doccano使用。
示例输出
{"text": "Chur\n\nChur is the capital and largest town of the Swiss canton
of the Grisons and lies in the Grisonian Rhine Valley.",
"label": [[0, 4, "heading"], [0, 4, "h1"], [6, 10, "emphasis"]]}如果使用以下注释规则运行inscriptis,将产生上述输出
{
"h1": ["heading", "h1"],
"b": ["emphasis"],
}以下代码演示了如何在程序中使用inscriptis的注释功能
import urllib.request
from inscriptis import get_annotated_text
from inscriptis.model.config import ParserConfig
url = "https://www.fhgr.ch"
html = urllib.request.urlopen(url).read().decode('utf-8')
rules = {'h1': ['heading', 'h1'],
'h2': ['heading', 'h2'],
'b': ['emphasis'],
'table': ['table']
}
output = get_annotated_text(html, ParserConfig(annotation_rules=rules)
print("Text:", output['text'])
print("Annotations:", output['label'])微调
以下选项可用于微调inscriptis的HTML渲染
更严格的缩进:通过将参数indentation='extended'传递给inscriptis.get_text()来使用标签(如<div>和<span>)的缩进,这些标签在其标准定义中不提供缩进。这是inscript和许多其他工具(如Lynx)中的默认策略。如果您不想使用扩展缩进,则可以使用参数indentation='standard'。
覆盖默认CSS定义:inscriptis使用保存在inscriptis.css.CSS中的CSS定义来渲染HTML标签。您可以按照以下方式覆盖这些定义(因此更改渲染)
from lxml.html import fromstring
from inscriptis.css_profiles import CSS_PROFILES, HtmlElement
from inscriptis.html_properties import Display
from inscriptis.model.config import ParserConfig
# create a custom CSS based on the default style sheet and change the
# rendering of `div` and `span` elements
css = CSS_PROFILES['strict'].copy()
css['div'] = HtmlElement(display=Display.block, padding=2)
css['span'] = HtmlElement(prefix=' ', suffix=' ')
html_tree = fromstring(html)
# create a parser using a custom css
config = ParserConfig(css=css)
parser = Inscriptis(html_tree, config)
text = parser.get_text()自定义HTML标签处理
如果上述微调选项不足,您甚至可以按照以下方式覆盖Inscriptis处理开始和结束标签的方式
from inscriptis import ParserConfig
from inscriptis.html_engine import Inscriptis
from inscriptis.model.tag import CustomHtmlTagHandlerMapping
my_mapping = CustomHtmlTagHandlerMapping(
start_tag_mapping={'a': my_handle_start_a},
end_tag_mapping={'a': my_handle_end_a}
)
inscriptis = Inscriptis(html_tree,
ParserConfig(custom_html_tag_handler_mapping=my_mapping))
text = inscriptis.get_text()在示例中,标准HTML的a标签处理程序被自定义版本(即my_handle_start_a和my_handle_end_a)覆盖。您可以定义任何标签的自定义处理程序,无论该标签是否已在标准映射中存在。
请参阅custom-html-handling.py以获取一个有效示例。标准HTML标签处理程序可以在inscriptis.model.tag包中找到。
优化内存消耗
Inscriptis使用Python lxml库,该库更喜欢重用内存而不是将其释放给操作系统。如果您在Web服务中使用inscriptis解析非常复杂的HTML页面,这种行为可能会导致内存消耗增加。
以下代码通过手动强制lxml释放分配的内存来在Unix系统上减轻此问题
import ctypes
def trim_memory() -> int:
libc = ctypes.CDLL("libc.so.6")
return libc.malloc_trim(0)示例
严格缩进处理
以下示例演示了修改ParserConfig以进行严格的缩进处理。
from inscriptis import get_text
from inscriptis.css_profiles import CSS_PROFILES
from inscriptis.model.config import ParserConfig
config = ParserConfig(css=CSS_PROFILES['strict'].copy())
text = get_text('fi<span>r</span>st', config)
print(text)在解析过程中忽略元素
覆盖默认CSS配置文件还可以更改选定元素的渲染。以下示例中,通过将form标签的定义设置为Display.none,从解析的文本中删除表单。
from inscriptis import get_text
from inscriptis.css_profiles import CSS_PROFILES, HtmlElement
from inscriptis.html_properties import Display
from inscriptis.model.config import ParserConfig
# create a custom CSS based on the default style sheet and change the
# rendering of `div` and `span` elements
css = CSS_PROFILES['strict'].copy()
css['form'] = HtmlElement(display=Display.none)
# create a parser configuration using a custom css
html = """First line.
<form>
User data
<label for="name">Name:</label><br>
<input type="text" id="name" name="name"><br>
<label for="pass">Password:</label><br>
<input type="hidden" id="pass" name="pass">
</form>"""
config = ParserConfig(css=css)
text = get_text(html, config)
print(text)引用
@article{Weichselbraun2021,
doi = {10.21105/joss.03557},
url = {https://doi.org/10.21105/joss.03557},
year = {2021},
publisher = {The Open Journal},
volume = {6},
number = {66},
pages = {3557},
author = {Albert Weichselbraun},
title = {Inscriptis - A Python-based HTML to text conversion library optimized for knowledge extraction from the Web},
journal = {Journal of Open Source Software}
}变更日志
完整的更改列表可以在发行说明中找到。


下载文件
下载适用于您的平台的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。
源代码发行版
构建发行版
inscriptis-2.5.0.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 3ebccaa0fca3d860ff8943d22f10c8ade8adbf481a0f81eb150c7b911db6f3c9 |
|
| MD5 | f8acb3aef99ed428d4fcb85d41f3a4e9 |
|
| BLAKE2b-256 | 3e0d167d2b9e0a30c37dc0a8d152707b23c67e75d210a3a0986494cd7070af1e |
inscriptis-2.5.0-py3-none-any.whl 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 28ac4eed83bc470833eada0139d07672a74b4f7eb4dbab69c93ca1e903de2ea0 |
|
| MD5 | 7cb6f5ecbb6cb8254e4a7605c8c31020 |
|
| BLAKE2b-256 | 36efb5459a0192ad8a943be67a4821e5234be9b567e7b8a34658c93a460c51d6 |