模拟高速公路驾驶任务的仿真环境。


项目描述
highway-env





由Edouard Leurent开发和维护的用于自动驾驶和战术决策任务的仿真环境的集合。
highway-env中可用环境的一个示例。
在Google Colab上试用! 
环境
高速公路
env = gymnasium.make("highway-v0")
在这个任务中,ego-车辆正在多车道高速公路上驾驶,路上有其他车辆。代理的目标是在避免与相邻车辆碰撞的同时,达到高速行驶。在道路右侧行驶也会获得奖励。
高速公路-v0环境。

还有更快的变体,highway-fast-v0,为了提高大规模训练速度,仿真精度有所降低。
合并
env = gymnasium.make("merge-v0")
在这个任务中,ego-车辆从主高速公路开始,但很快就会接近一个路口,入口匝道上有来车。现在代理的目标是在为车辆腾出空间以便它们可以安全并入交通的同时,保持高速行驶。
合并-v0环境。

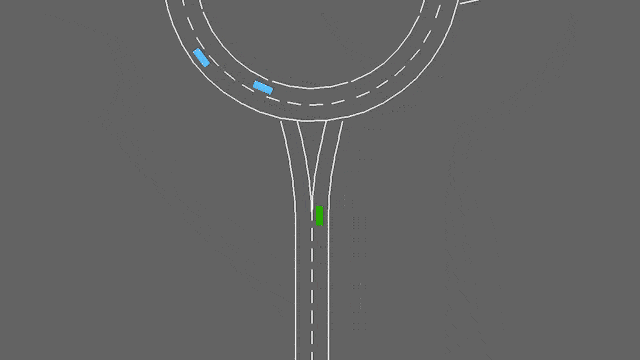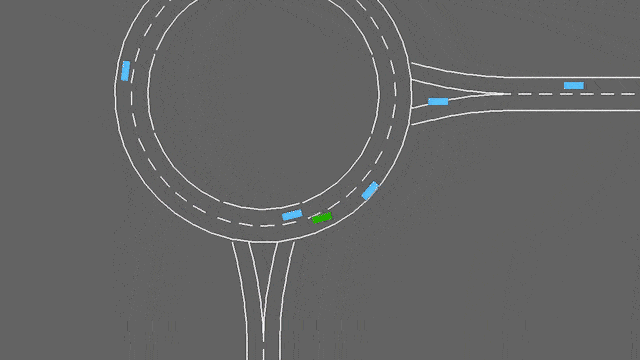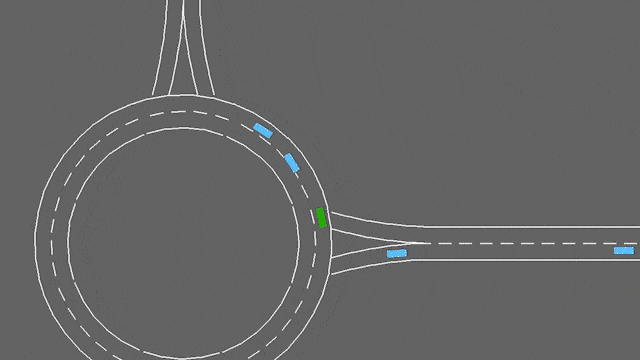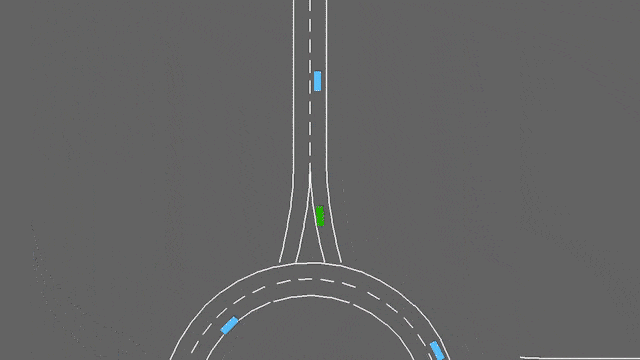
环岛
env = gymnasium.make("roundabout-v0")
在这个任务中,ego-车辆正在接近一个交通繁忙的环岛。它将自动遵循其预定路线,但必须处理车道变换和纵向控制,以便尽可能快速地通过环岛,同时避免碰撞。
环岛-v0环境。
停车
env = gymnasium.make("parking-v0")
这是一个基于目标条件的连续控制任务,其中ego-车辆必须以适当的航向停放在指定的空间中。
停车-v0环境。
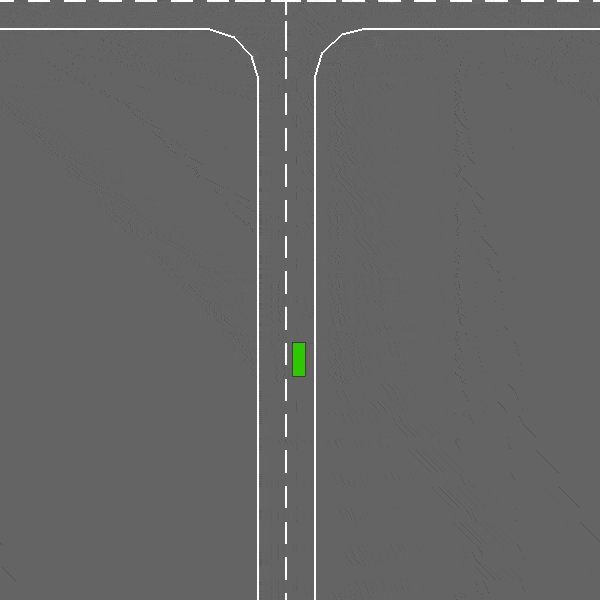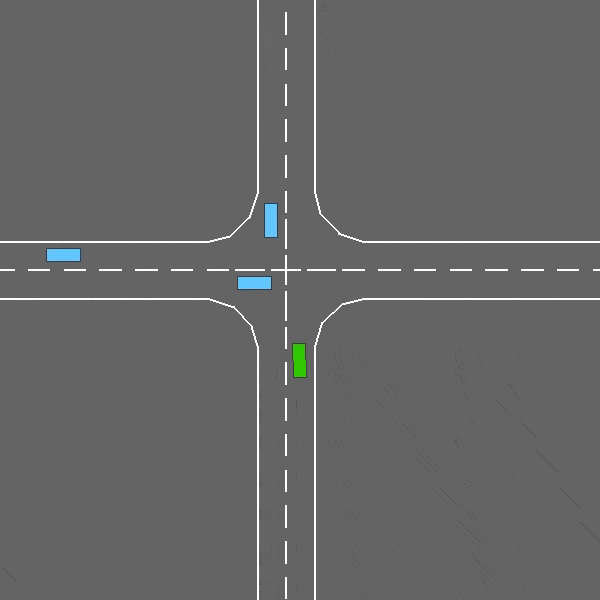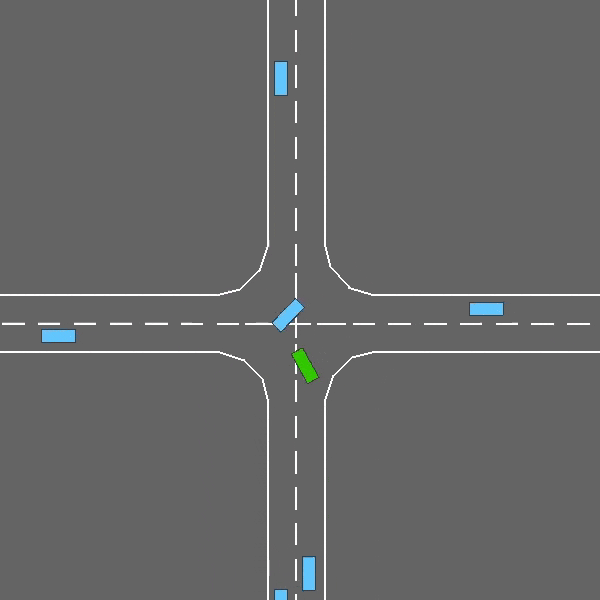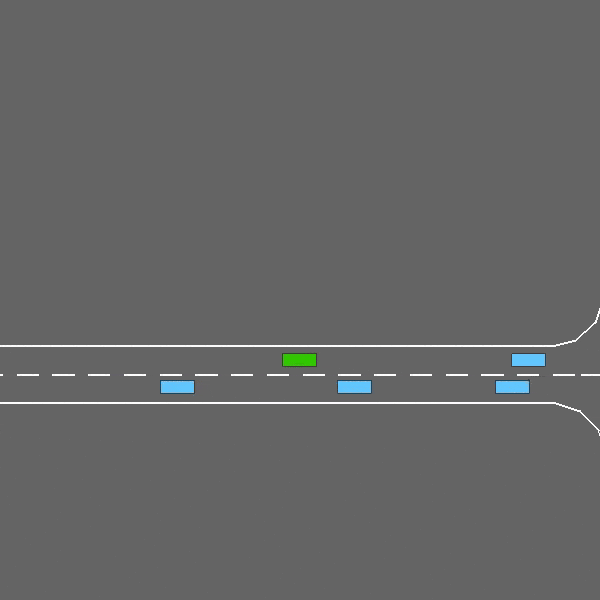
交叉路口
env = gymnasium.make("intersection-v0")
这是一个密集交通的交叉路口协商任务。
交叉路口-v0环境。
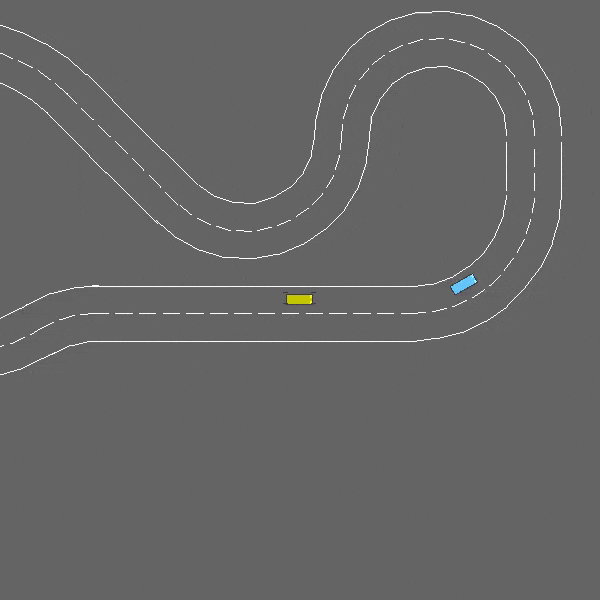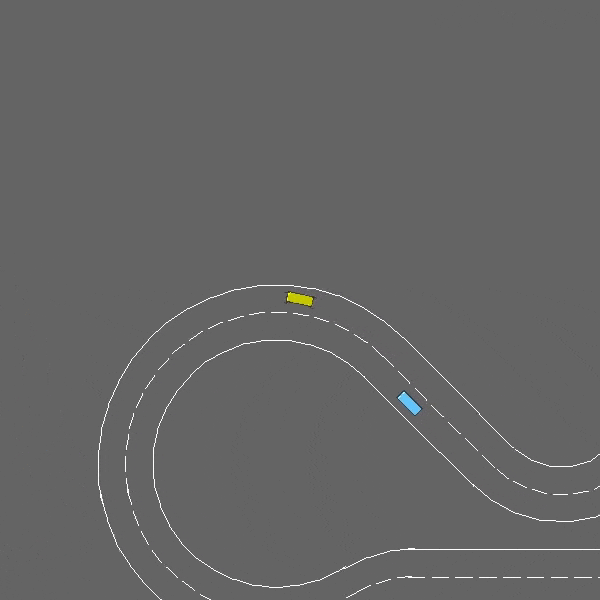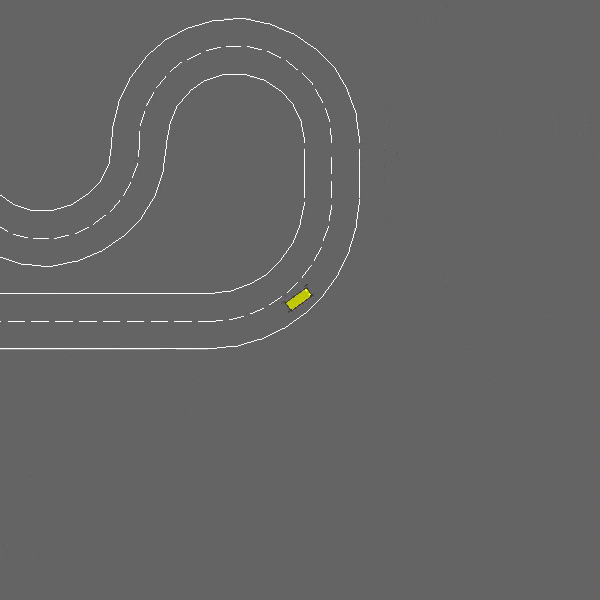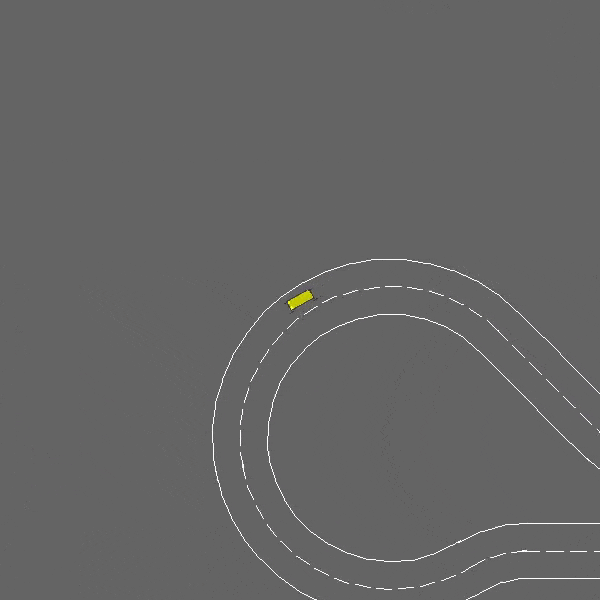
赛道
env = gymnasium.make("racetrack-v0")
这是一个涉及车道保持和障碍物避让的连续控制任务。
赛道-v0环境。
代理示例
解决highway-env环境的代理可在eleurent/rl-agents和DLR-RM/stable-baselines3存储库中找到。
请参阅文档以获取一些示例和笔记本。
深度Q网络
解决highway-v0的DQN代理。
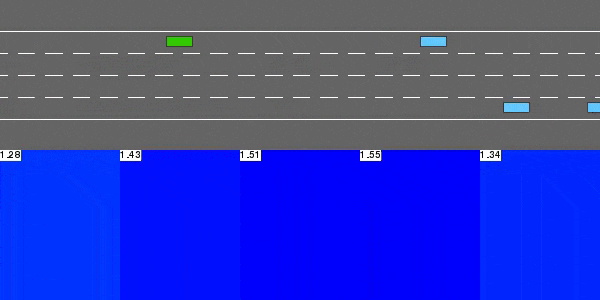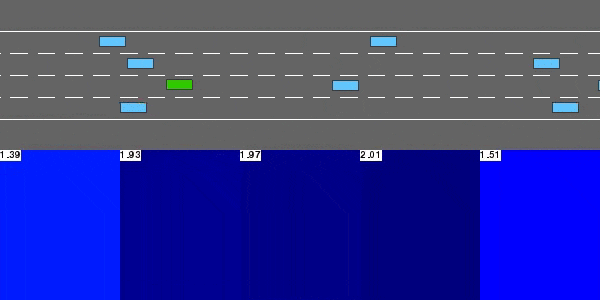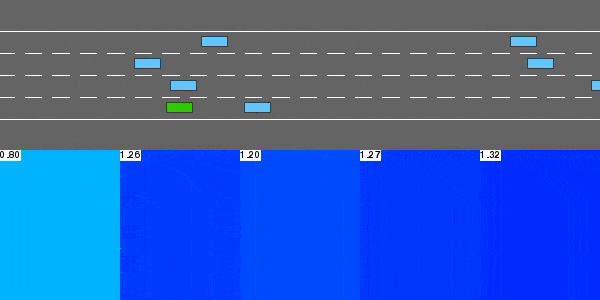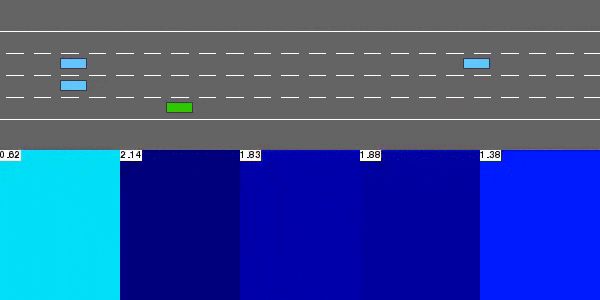
这个无模型的基于价值的强化学习代理通过函数近似执行Q学习,使用神经网络来表示状态-动作值函数Q。
深度确定策略梯度
解决parking-v0的DDPG代理。

这个无模型的基于策略的强化学习代理通过梯度上升直接优化。它使用Hindsight Experience Replay来高效地学习如何解决基于目标的任务。
值迭代
解决highway-v0的值迭代代理。
值迭代仅适用于有限离散MDP,因此环境首先使用env.to_finite_mdp()通过有限-mdp环境进行近似。这种简化的状态表示用预测的碰撞时间(TTC)来描述道路上的附近交通。转换模型简单,假设每辆车都将以恒定速度行驶,不改变车道。这种模型偏差可能成为错误的原因。
然后代理执行值迭代来计算相应的最优状态值函数。
蒙特卡洛树搜索
这个代理利用转换和奖励模型来执行最优轨迹的随机树搜索(Coulom, 2006)。对状态表示或转换模型没有特定要求。
解决highway-v0的MCTS代理。

安装
pip install highway-env
用法
import gymnasium as gym
env = gym.make('highway-v0', render_mode='human')
obs, info = env.reset()
done = truncated = False
while not (done or truncated):
action = ... # Your agent code here
obs, reward, done, truncated, info = env.step(action)
文档
请在线阅读文档。
开发路线图
以下是未来开发工作的路线图。
引用
如果您在您的作品中使用了此项目,请考虑引用它。
@misc{highway-env,
author = {Leurent, Edouard},
title = {An Environment for Autonomous Driving Decision-Making},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/eleurent/highway-env}},
}
使用highway-env的出版物和预印本列表(请提交一个拉取请求以添加缺失条目)
- 不确定动态系统的近似鲁棒控制(2018年12月)
- 具有参数不确定性的连续时间系统的区间预测 (2019年4月)
- 实际开环乐观规划 (2019年4月)
- α^α-Rank:通过随机优化实现α-Rank的实践扩展 (2019年9月)
- 密集交通中的自主决策的社交注意力 (2019年11月)
- 连续状态空间中的预算强化学习 (2019年12月)
- 多视角强化学习 (2019年12月)
- 具有用户自适应的对话系统优化的强化学习 (2019年12月)
- 分布软演员评论员:用于风险敏感学习的分布软演员评论员 (2020年4月)
- 多智能体协调的分层演员评论员 (2020年4月)
- 具有无限高斯过程混合的无需任务的在线强化学习 (2020年6月)
- 超越优先回放:通过模拟优先级在基于模型的RL中采样状态 (2020年7月)
- 线性不确定系统的鲁棒自适应区间预测控制 (2020年7月)
- SMART:同时多智能体递归轨迹预测 (2020年7月)
- 针对合作和竞争环境的延迟感知多智能体强化学习 (2020年8月)
- B-GAP:用于自主导航的行为引导动作预测 (2020年11月)
- 基于信号时间逻辑规范的模型强化学习 (2020年11月)
- 超越二次成本的线性系统鲁棒自适应控制 (2020年12月)
- 评估和加速深度强化学习中的覆盖率 (2020年12月)
- 用于自动驾驶车辆测试的自然主义驾驶环境的一致分布模拟 (2021年1月)
- 通过自然语言和RL进行可解释策略规范和合成 (2021年1月)
- 多样化领域的深度强化学习技术综述 (2021年2月)
- 用于自动驾驶车辆安全评估的角案例生成和分析 (2021年2月)
- 具有自然主义和对抗环境的自动驾驶车辆智能驾驶测试 (2021年2月)
- 利用风险驾驶行为知识构建更安全的自主代理
- 通过元强化学习快速学习适应变化交通文化的自动驾驶车辆 (2021年4月)
- 用于混合交通中高速公路匝道合并的深度多智能体强化学习 (2021年5月)
- 通过自适应重要性抽样加速策略评估:学习对抗环境 (2021年6月)
- 在密集交通场景中通过学习感知交互引导策略进行运动规划 (2021年7月)
- 基于近端策略优化的双向道路自动超车:基于车辆交互 (2021年7月)
- 鲁棒可预测控制 (2021年9月)
- 为自动驾驶游戏适应自主代理 (2021年11月)
- 增强深度强化学习智能体的鲁棒性:基于评论网络的攻击环境(2022年7月)
- 使用强化学习和运动预测安全控制器在混合交通中进行自主高速公路合并(2022年10月)
- 高级决策的非玩家车辆(2022年11月)
- 设计用于高速公路自动驾驶模拟的深度强化学习(DRL)智能体的可解释性分析框架(2023年2月)
- 解释基于深度强化学习(DRL)的公路模拟中的自动驾驶智能体(2023年3月)
- 研究自动驾驶的高级决策(2023年4月)
- 实现基于深度强化学习(DRL)的驾驶风格用于非玩家车辆(2023年11月)
- 研究自动驾驶高速公路模拟中的鲁棒智能体的对抗策略学习(2024年1月)
博士论文
- 具有用户自适应的对话系统优化的强化学习 (2019)
- 自动驾驶行为规划中的安全和高效强化学习 (2020)
- 多智能体强化学习 (2021)
硕士学位论文
- 应用于交通流量控制的多智能体强化学习(2021年6月)
- 用于自动驾驶泊车的深度强化学习(2021年8月)
- 在简约环境中进行自动驾驶的深度强化学习和模仿学习(2021年6月)


下载文件
下载适用于您平台的文件。如果您不确定选择哪个,请了解有关 安装包 的更多信息。
源分布
构建分布
highway_env-1.10.1.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | d40158345c4eadd876d572a9193c10e487d3ae81c95b8d17949965595481db55 |
|
| MD5 | 3f36bd7bbe407656fa9168d8bd2eb1df |
|
| BLAKE2b-256 | 20f0250bdaef408b27e55a3cac6cb8d4fbf6163b7bc18a6f3ca571b34cb6385c |
highway_env-1.10.1-py3-none-any.whl 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 37a9e71268e70c32fc5b7f01f14a6e3cb41f6f456cd67affe87d4ce04601521e |
|
| MD5 | 1a6030e971a9b9806cffb3d55b98b774 |
|
| BLAKE2b-256 | 4a0de3b8a92da9b8f19f630fea300e94411fa5605b70bfa49e1c4fe20489a3a3 |







