未提供项目描述

项目描述
Follow The Money: Compare
用于比较followthemoney实体的工具和模型
概述
此存储库提供必要的工具,用于预处理和训练模型,以在followthemoney之上构建交叉引用系统。它考虑到了与aleph的紧密集成,但此存储库是aleph无关的。
目前,此系统有三个主要组件
- 导出训练数据
- 创建预处理过滤器(可选)
- 创建训练数据
- 训练模型
以下将详细介绍。
安装
通过pipy进行安装。要安装用于模型评估的最小依赖项,请运行
$ pip install followthemoney-compare
如果您打算训练模型或进行任何模型开发,您还应该安装开发依赖项
$ pip install followthemoney-compare[dev]
此外,提供了一个Dockerfile(默认为最小的followthemoney-compare安装),以简化系统依赖项。
预构建模型
预构建模型和单词频率对象可在OCCRP的公共数据网站上找到。URL如下
- https://public.data.occrp.org/develop/models/word-frequencies/word_frequencies.zip
- https://public.data.occrp.org/develop/models/xref/glm_bernoulli_2e_wf-v0.4.1.pkl
应解压缩word_frequencies.zip存档,并将envvar FTM_COMPARE_FREQUENCIES_DIR设置为解压缩数据的路径。
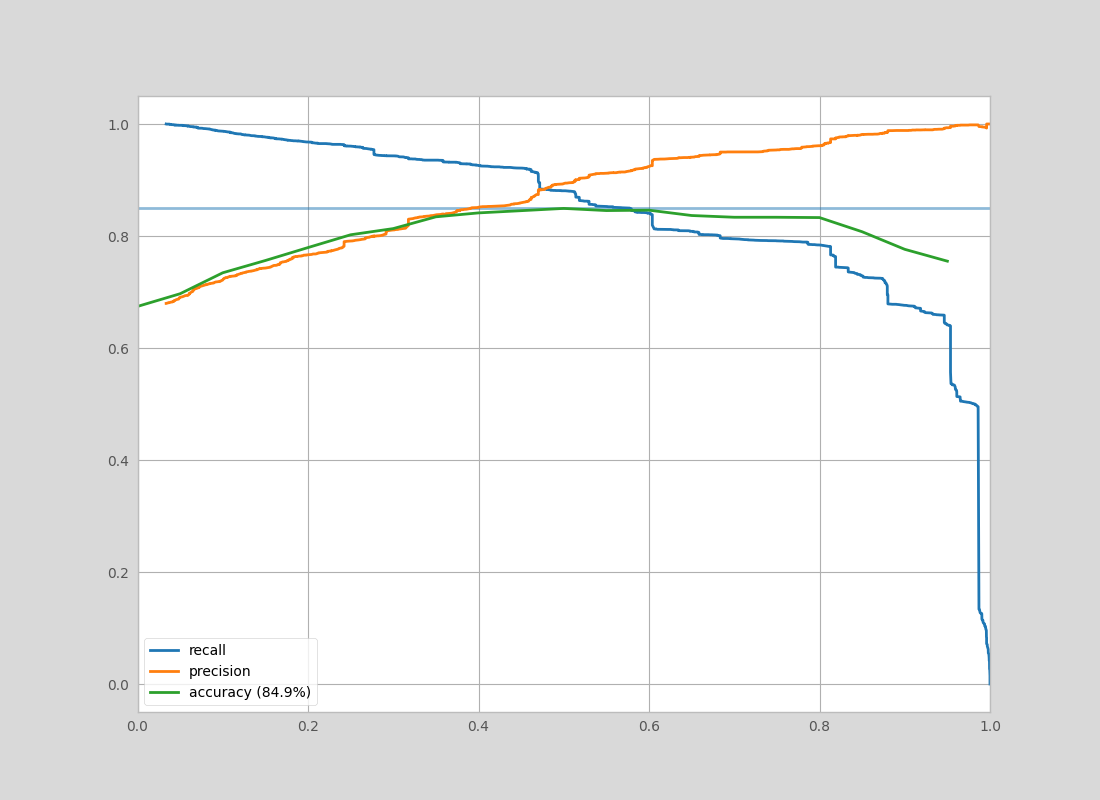
可以使用pickle加载模型文件并立即使用。此预构建模型在https://aleph.occrp.org/构建的数据集上实现了以下准确度-精确度-召回率
导出训练数据
此系统最初的数据来源是aleph配置文件系统。在此系统中,用户看到提议的实体匹配并决定这两个实体是否确实相同。使用aleph配置文件API端点(/api/2/entitysets?filter:type=profile&filter:collection_id=<collection_id>)或使用aleph配置文件导出实用程序($ aleph dump-profiles),可以将这些用户决策导出为JSON格式。
此JSON数据包括配置文件ID、比较的两个实体、它们的来源集合以及用户关于它们相似性的决定。如果所有多个积极匹配都具有相同的配置文件ID,我们可以认为所有实体都是相同的。因此,对单个配置文件所做的许多判断通常比在不同配置文件上做相同数量的判断提供更多的训练数据。
除了这些人工标记的数据之外,您可以选择提供可以用来创建更智能的预处理过滤器的实体列表,以清理数据。这是通过从aleph导出原始实体并确保实体具有collection_id字段来完成的(根据您的导出方法,这可能需要手动添加)。
创建预处理过滤器(可选)
为了减少实体属性中的噪声,我们使用count-min sketch计算一个近似TF-IDF。使用这个系统,我们能够通过“信息量”来权衡每个标记,并帮助结果模型不专注于非常常见的标记(例如常见的姓氏或公司中的“公司”一词)。
为了实现这一点,使用子命令$ followthemoney-compare create-word-frequency。它接受一个包含实体的平面文件(包括它们的collection_id),对name属性进行标记化,并累计所有实体的标记频率、每个架构的标记频率以及该标记在多少个集合中出现过。
在创建这些结构时,您可以决定可以接受的近似TF-IDF的误差大小。置信度和错误率已调整,以在OCCRP的Aleph安装提供的数据量范围内提供合理的结果。在这种情况下,每个结构大约为8MB,99.95%的时间误差为0.01%。错误率和置信水平可以根据您打算使用的数据量进行调整,以调整结果结构的尺寸。
create-word-frequency子命令将结果计数保存到包含计数-min sketch的目录结构中。应将此目录的路径保存到您的FTM_COMPARE_FREQUENCIES_DIR环境变量中(默认为"./data/word_frequencies/")。
$ cat ./data/entities.json | \
followthemoney-compare create-word-frequency ./data/word-frequency/
创建训练数据
为了加快训练速度,模型使用的所有实体比较特征都是预先计算并保存到pandas数据框中的。为了创建此数据框,运行$ followthemoney-compare create-data子命令。如果它们可用(如果不,将发出UserWarning以确保您知道!),它将使用上一步计算的计数-min sketch过滤器。
请注意,如果您有大型配置文件,在此步骤中进度条可能会非常跳跃。对此步骤要有耐心,因为它可能需要一个小时才能完成。如果您发现自己经常重建训练数据(即:如果您正在调整模型特征),这个阶段可能是优化的好时机。
$ export FTM_COMPARE_FREQUENCIES_DIR="./data/word-frequency" # optional
$ followthemoney-compare create-data \
./data/profiles-export/ ./data/training-data.pkl
训练模型
所有模型都可以使用相同的CLI进行训练。为了查看可用的模型,运行命令$ followthemoney-compare list-models。目前,glm_bernoulli_2e模型表现最好,尤其是在可以具有不同完整级别的实体上。
$ export FTM_COMPARE_FREQUENCIES_DIR="./data/word-frequency" # optional
$ followthemoney-compare train \
--plot "./data/models/glm_bernoulli_2e.png" \
glm_bernoulli_2e \
./data/training-data.pkl \
"./data/models/glm_bernoulli_2e.pkl"
一旦训练完毕,可选参数--plot将为结果模型创建一个准确性/精确度/召回率曲线,可用于诊断。
可以使用pickle或followthemoney_compare.models.GLMBernouli2EEvaluate.load_pickles方法加载结果模型。此模型文件是训练模型的简化版本,适用于快速评估,具有最小的依赖性和资源开销。然而,它也缺少用于模型训练的诊断和中间变量。因此,在创建新的模型类型时,最好使用Python API来训练模型,并且仅在使用已知模型时使用CLI工具。
结果评估对象的评估非常简单和灵活。它提供了以下方法:
- predict(): 返回True / False,表示参数是否匹配
- predict_proba(): 返回一个概率值(范围在0到1之间),表示参数是否匹配
- predict_std(): 返回预测的标准差或置信度(值越高表示置信度越低)
- predict_proba_std(): 返回匹配概率和标准差,速度比单独调用两个方法快(并非所有模型都有此功能)
这些函数的参数可以采用以下形式
- DataFrame: 与
create-data命令返回的DataFrame格式相同的DataFrame - dict: 从
followthemoney_compare.compare.scores()输出的字典 - 代理对列表:两个
followthemoney.proxy.EntityProxy对象或这些对列表的元组。
模型描述
样本加权
为了减轻训练数据中的潜在噪声,每个样本都被加权。权重有两个贡献:用户权重和样本权重。
用户权重根据用户提交的判断数量对用户的所有判断应用权重。这种加权更倾向于那些提交了100+条提交的用户,并逐渐降低提交数量较少的用户(代码在followthemoney_compare.lib.utils user_weight())
样本权重检查实体对中的潜在信息内容。它对那些明显相同或明显不同的样本进行降权(即:所有属性完全相同或完全不同的两个实体)。它通过从compare.scores()中取平均值,并对远离平均分0.25 - 0.7的实体进行下采样来实现(代码在followthemoney_compare.lib.utils.pair_weight())。
这两个权重的乘积形成了一个样本的有效权重,该权重用于模型中。
GLM Bernoulli 2E
此模型使用pymc3通过MCMC拟合模型。作为输入,该模型使用followthemoney_compare.compare.scores的输出,该输出比较两个实体之间的followthemoney属性组,此外还有辅助变量,这些变量显示了两个实体共享了多少属性以及有多少属性仅存在于一个实体中。
以下是模型中使用的特征列表。例如,name的值是从followthemoney_compare.compare.scores中得到的(0, 1)的数值,表示两个实体的"name"属性的相似度。
- name
- country
- date
- identifier
- address
- phone
- iban
- url
- pct_share_prop: 两个实体共享的可能属性的百分比
- pct_miss_prop: 仅一个实体拥有的可能属性的百分比
- pct_share_prop^2
- name * pct_share_prop
- name^2
- pct_share_prop * pct_miss_prop
- pct_miss_prop^2
- name * identifier
- country * pct_share_prop
- identifier^2
- identifier * pct_miss_prop
- date^2
- address^2
所有这些特征都被输入到一个带有偏置的逻辑回归中,并使用样本权重进行拟合,以帮助去除噪声。
当使用CLI使用这种方法训练模型时,在退出之前会显示MCMC过程的摘要。以下是一些确保模型表现良好的指标
- 参数的SD(标准差)应该很低。任何具有高标准差的变量对分类不是特别有用,应该重新考虑
bulk_essi字段应该合理。此字段显示用于拟合此参数的有效样本数量。如果相当低,则表示数据没有很好地表示模型或训练数据太嘈杂。- 检查准确度-精确度-召回率曲线,确保模型是合理的。
改进
- 并行化训练数据创建
- 更好的测试/训练数据分割(按集合ID进行分层组采样?k折?)
- 更好的特征工程或深度学习模型?


下载文件
下载适用于您的平台的文件。如果您不确定选择哪个,请了解更多关于 安装包 的信息。
源代码分发
构建分发
哈希值 for followthemoney_compare-0.4.4-py3-none-any.whl
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | d6b1e1152dad7dbb7712087f99fd9623c56daac0e748b23af9c7e16ce956dec9 |
|
| MD5 | 024fcc5803336c797ae7685528dfa5ad |
|
| BLAKE2b-256 | d32ce48a9bd6d759d76220ee2aa94704ea719df0e7b11196ba2c8124443ea8a1 |