轻松构建反应式后端

项目描述
flask-boiler



"boiler": Backend-Originated Instantly-Loaded Entity Repository
注意:此包未进行性能分析或内存使用检查。建议您使用Kubernetes来提高容错能力。
Flask-boiler使用Firestore管理您的应用程序状态。您可以为聚合底层数据源创建视图模型,并立即永久地存储在Firestore中。因此,您的前端开发将像使用Firestore一样简单。Flask-boiler类似于Spring Web Reactive。
演示
当您更改会议中某位参与者的出席状态时,所有其他参与者都会收到会议出席人员名单的更新版本。
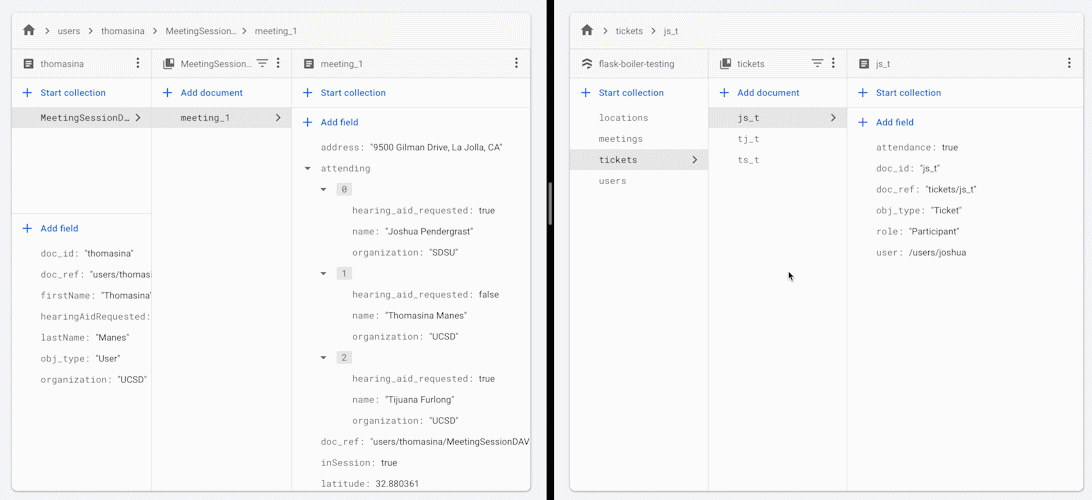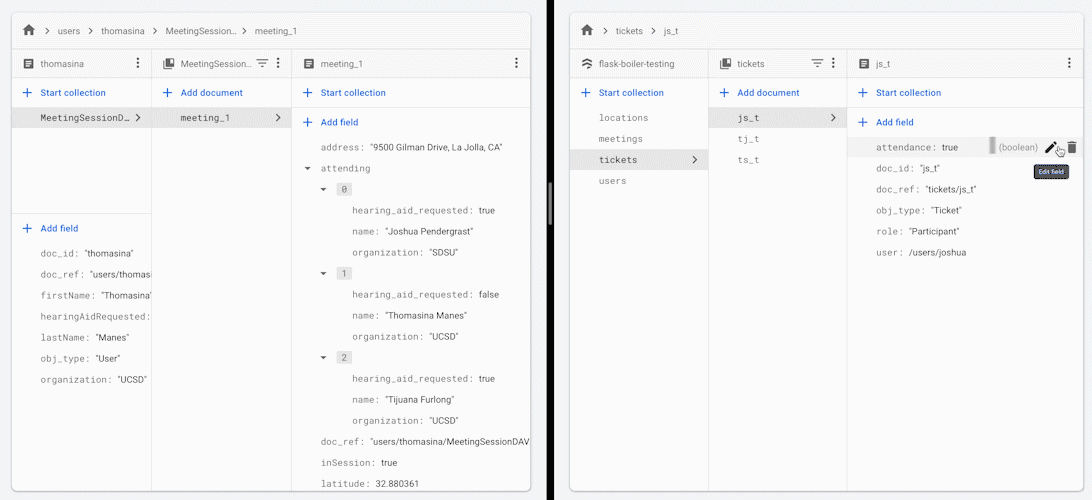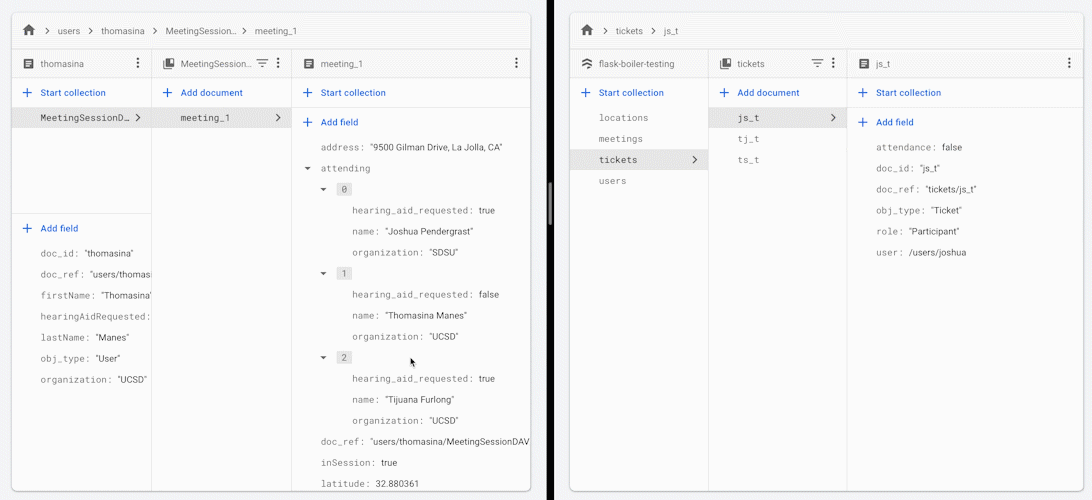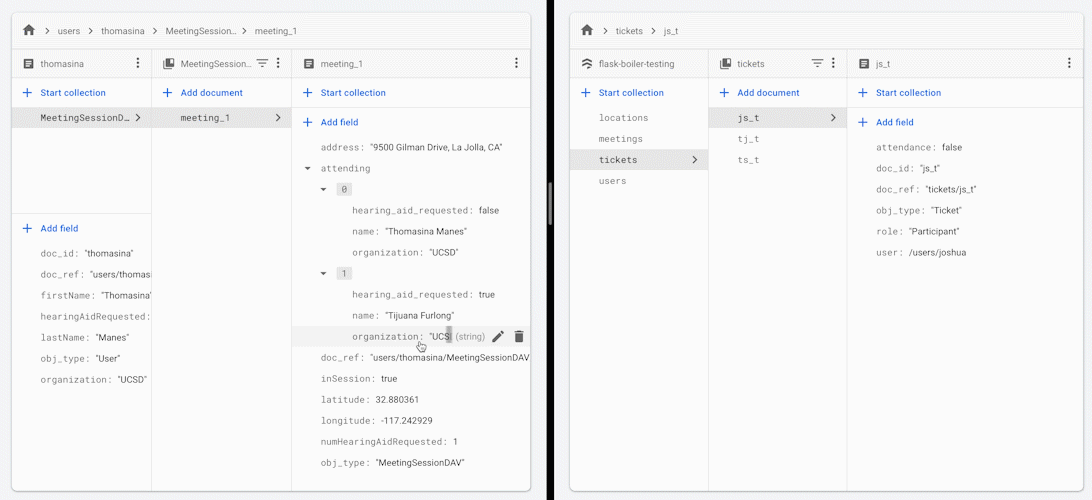
您可能希望使用此框架或架构实践的一些原因
- 您想要构建一个反应式系统,而不仅仅是反应式视图。
- 您想要构建一个适合分布式系统的可扩展应用程序。
- 您需要一个具有更高抽象级别的框架,以便可以交换组件,如传输协议。
- 您希望代码可读、清晰,大部分使用Python编写,同时保持与不同API的兼容性。
- 您的需求不断变化,希望具有灵活性,以迁移不同的层,例如,从REST API切换到WebSocket来服务资源。
此框架处于测试阶段。API不可保证,且可能更改。
文档:readthedocs
快速入门:Quickstart
API文档:API Docs
使用flask-boiler的项目示例:gravitate-backend
理想用法
boiler会将您的Python代码编译成flink作业、Web服务器等,以便在Kubernetes引擎上运行(目前尚未实现)。

支持的连接器
已实现
- REST API(Flask和Flasgger)
- GraphQL(Starlette)
- Firestore
- Firebase Functions
- JsonRPC(flask-jsonrpc)
- Leancloud Engine
- WebSocket(flask socketio)
待支持
- Flink Table API
- Kafka
设计模式
flask-boiler将抽象到MVVM(模型-视图-视图模型),其中,
- 模型由事务型数据库或数据存储组成,位于后端。
- 视图模型由模型和聚合器组成的分布式状态组成。它是boiler的主要部分。对于客户端读取,它接收从模型层进入的流,并将它们作为视图输出到视图层。对于客户端写入,它接收来自视图层的更改流,并在模型层上操作以持久化更改。视图模型位于后端,可以是boiler Python代码,也可以在大数据处理应用的情况下编译为flink作业(待实现)。
- 视图是后端的表示层。它提供1NF归一化数据,这些数据对于前端来说是可读的,无需进一步聚合。客户端读取和写入视图。视图应该是临时的,并可以从视图模型重建。
视图可能是一个远程系统,例如firestore或leancloud。
安装
在您的项目目录中,
pip install flask-boiler
更多信息请参阅Quickstart。
状态管理
您可以将从领域模型中收集的信息组合在一起,并在Firestore中提供服务,以便前端可以读取所需的所有数据,而无需客户端查询和过多的服务器往返时间。
有一篇中等文章解释了一个类似的架构,称为“reSolve”架构。
请参阅examples/meeting_room/view_models了解如何使用flask-boiler在firestore中公开“视图模型”,以便前端可以直接查询而无需聚合。
处理器模式
flask-boiler本质上是一个用于源-汇操作的框架
Source(s) -> Processor -> Sink(s)
以查询为例,
- Boiler
- NoSQL
- Flink
- 静态方法:转换为UDF
- 类方法:转换为操作符和聚合器
声明视图模型
class CityView(ViewModel):
name = attrs.bproperty()
country = attrs.bproperty()
@classmethod
def new(cls, snapshot):
store = CityStore()
store.add_snapshot("city", dm_cls=City, snapshot=snapshot)
store.refresh()
return cls(store=store)
@name.getter
def name(self):
return self.store.city.city_name
@country.getter
def country(self):
return self.store.city.country
@property
def doc_ref(self):
return CTX.db.document(f"cityView/{self.store.city.doc_id}")
文档视图
class MeetingSessionGet(Mediator):
from flask_boiler import source, sink
source = source.domain_model(Meeting)
sink = sink.firestore() # TODO: check variable resolution order
@source.triggers.on_update
@source.triggers.on_create
def materialize_meeting_session(self, obj):
meeting = obj
assert isinstance(meeting, Meeting)
def notify(obj):
for ref in obj._view_refs:
self.sink.emit(reference=ref, snapshot=obj.to_snapshot())
_ = MeetingSession.get(
doc_id=meeting.doc_id,
once=False,
f_notify=notify
)
# mediator.notify(obj=obj)
@classmethod
def start(cls):
cls.source.start()
WebSocket视图
class Demo(WsMediator):
pass
mediator = Demo(view_model_cls=rainbow_vm,
mutation_cls=None,
namespace="/palette")
io = flask_socketio.SocketIO(app=app)
io.on_namespace(mediator)
创建Flask视图
您可以使用RestMediator创建REST API。当您运行_ = Swagger(app)时,将在<site_url>/apidocs自动生成OpenAPI3文档。
app = Flask(__name__)
class MeetingSessionRest(Mediator):
# from flask_boiler import source, sink
view_model_cls = MeetingSessionC
rest = RestViewModelSource()
@rest.route('/<doc_id>', methods=('GET',))
def materialize_meeting_session(self, doc_id):
meeting = Meeting.get(doc_id=doc_id)
def notify(obj):
d = obj.to_snapshot().to_dict()
content = jsonify(d)
self.rest.emit(content)
_ = MeetingSessionC.get(
doc_id=meeting.doc_id,
once=False,
f_notify=notify
)
# @rest.route('/', methods=('GET',))
# def list_meeting_ids(self):
# return [meeting.to_snapshot().to_dict() for meeting in Meeting.all()]
@classmethod
def start(cls, app):
cls.rest.start(app)
swagger = Swagger(app)
app.run(debug=True)
(目前处于实现中)
对象生命周期
一次
使用cls.new创建对象 -> 使用obj.to_view_dict导出对象。
多次
当数据库中创建新的领域模型时创建对象 -> 当底层数据源更改时更改对象 -> 对象调用self.notify
典型的ViewMediator用例
数据流方向描述为源 -> 汇。 "读取"描述了前端在汇中找到数据有用的数据流。"写入"描述了汇是唯一真相来源的数据流。
Rest
读取:请求 -> 响应
写入:请求 -> 文档
- 前端向服务器发送HTTP请求
- 服务器查询数据存储
- 服务器返回响应
查询
读:文档 -> 文档
写:文档 -> 文档
- 数据存储触发更新函数
- 服务器重建可能已更改的ViewModel
- 服务器将新构建的ViewModel保存到数据存储
查询+任务
读:文档 -> 文档
写:文档 -> 文档
- 数据存储在时间
t触发对文档d的更新函数 - 服务器开始事务
- 服务器将write_option设置为仅在文档在时间
t最后更新时允许提交(仍在设计中) - 服务器使用事务构建ViewModel
- 服务器使用事务保存ViewModel
- 服务器将文档
d标记为已处理(删除文档或更新字段) - 如果前提条件失败,服务器从步骤2重试最多MAX_RETRIES次
WebSocket
读:文档 -> WebSocket事件
写:WebSocket事件 -> 文档
- 前端通过向服务器发送WebSocket事件来订阅ViewModel
- 服务器将监听器附加到查询的结果
- 每当查询的结果改变并且一致时
- 服务器重建可能已更改的ViewModel
- 服务器发布新构建的ViewModel
- 前端结束会话
- 文档监听器被释放
文档
读:文档 -> 文档
写:文档 -> 文档
比较
| Rest | 查询 | 查询+任务 | WebSocket | 文档 | |
|---|---|---|---|---|---|
| 保证 | ≤1(至多一次) | ≥ 1(至少一次) | =1[^1](恰好一次) | ≤1(至多一次) | ≥ 1(至少一次) |
| 幂等性 | 如果实现 | 否 | 是,带有事务[^1] | 如果实现 | 否 |
| 设计用于 | 无状态Lambda | 有状态容器 | 无状态Lambda | 无状态Lambda | 有状态容器 |
| 延迟 | 更高 | 更高 | 更高 | 更低 | 更高 |
| 吞吐量 | 在扩展时更高 | 更低[^2] | 更低 | 在扩展时更高 | 更低[^2] |
| 有状态 | 否 | 如果实现 | 如果实现 | 是 | 是 |
| 响应式 | 否 | 是 | 是 | 是 | 是 |
[^1]: 消息可能被多个消费者接收和处理,但只有一个消费者可以成功提交更改并标记事件为已处理。 [^2]: 可扩展性受您可以附加到数据存储的监听器数量的限制。
优点
解耦领域模型和视图模型
使用Firebase Firestore有时需要在多个文档中重复字段,以便同时查询数据和在前端正确显示它们。Flask-boiler通过解耦领域模型和视图模型解决了这个问题。视图模型会随着领域模型的变化自动生成和刷新。这意味着您只需在领域模型上编写业务逻辑,而无需担心数据如何显示。这也意味着视图模型可以直接在前端显示,同时支持Firebase Firestore的实时功能。
一键配置
而不是为您数据库和其他云服务配置网络和不同的证书设置。您只需要在Google Cloud Console上启用相关服务,并添加您的证书。Flask-boiler配置您需要的所有服务,并将它们作为单例上下文对象在项目中公开。
冗余
由于所有视图模型都保存在Firebase Firestore中。即使您的应用程序实例离线,用户也可以从Firebase Firestore访问数据的视图。每个视图也是Flask视图,因此您也可以使用自动生成的REST API访问数据,以防Firebase Firestore不可行。
增加了安全性
通过将业务数据与前端可访问的文档分离,您可以更好地控制根据用户角色显示哪些数据。
一键文档
所有ViewModel都有自动生成的文档(由Flasgger提供)。这有助于AGILE团队将文档与实际代码保持同步。
完全可扩展
当您需要更好的性能或关系数据库支持时,您总是可以通过添加模块(如flask-sqlalchemy)来重构特定层。
比较
GraphQL
在GraphQL中,字段会在每次查询时进行评估,但flask-boiler仅在底层数据源发生变化时评估字段。这导致长时间未更改的数据读取速度更快。此外,数据源应保持一致性,因为字段评估是在读取firestore中一个事务中所有更改之后触发的。
然而,GraphQL允许前端自定义返回值。您必须在flask-boiler中定义您想要返回的确切结构。尽管如此,这也有其优势,因为大多数请求和响应的文档都可以像REST API一样进行。
REST API / Flask
REST API不会缓存或存储响应。当flask-boiler评估视图模型时,响应将永久存储在firestore中,直到更新或手动删除。
Flask-boiler使用与Firestore集成的安全规则控制基于角色的访问。REST API通常使用JWT令牌来控制这些访问。
Redux
Redux主要在客户端实现。Flask-boiler针对后端,更具有可扩展性,因为所有数据都是通过Firestore(一个无限可扩展的NoSQL数据存储)进行通信的。
Flask-boiler是声明式的,而Redux是命令式的。REDUX的设计模式要求你在领域模型中编写函数式编程,但flask-boiler倾向于不同的方法:ViewModel从领域模型中读取和计算数据,并将属性公开为属性获取器。(当写入DomainModel时,视图模型会更改领域模型,并将操作公开为属性设置器)。尽管如此,您仍然可以添加在领域模型更新后触发的函数回调,但这可能会引入并发问题,并且由于flask-boiler中的设计权衡,此功能可能不会得到完美支持。
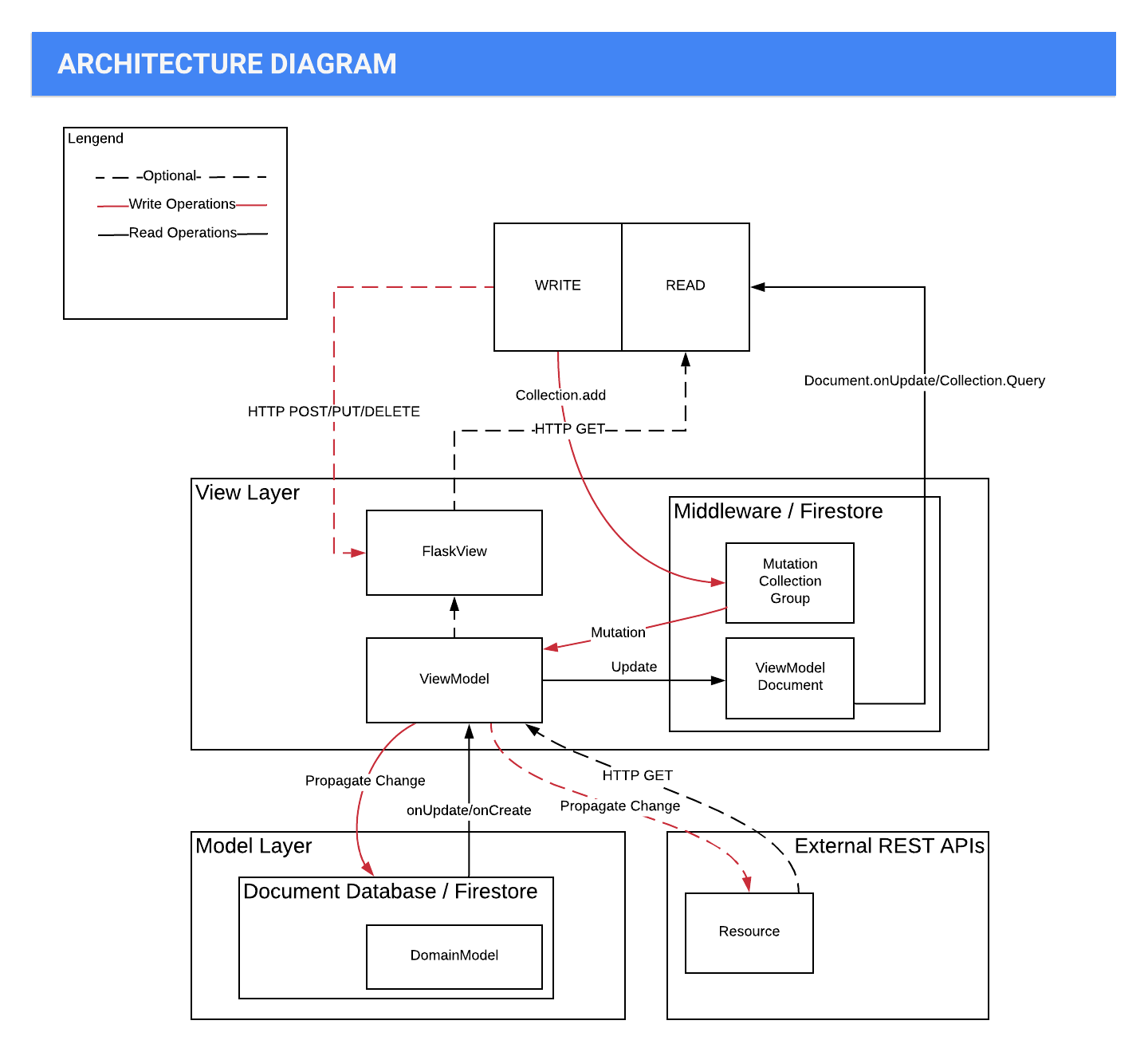
架构图
贡献
欢迎提交拉取请求。
请确保根据需要更新测试。

