基于transformer的语言模型的微调和评估框架

项目描述

(Framework for Adapting Representation Models)









这是什么?
FARM使BERT及其它模型的迁移学习变得简单、快速且适用于企业。它基于transformers,并为开发者提供额外的功能以简化其生活:并行预处理、高度模块化设计、多任务学习、实验跟踪、易于调试,并与AWS SageMaker紧密集成。
使用FARM,您可以构建用于文本分类、NER或问答等任务的快速原型,并将其轻松转移到生产中。
核心功能
轻松微调语言模型以适应您的任务和领域语言
速度:AMP优化器(约35%更快)和并行预处理(16 CPU核心=>约16倍更快)
模块化设计语言模型和预测头
在头之间切换或合并它们进行多任务学习
完全兼容HuggingFace Transformers的模型和模型库
平滑升级到更新的语言模型
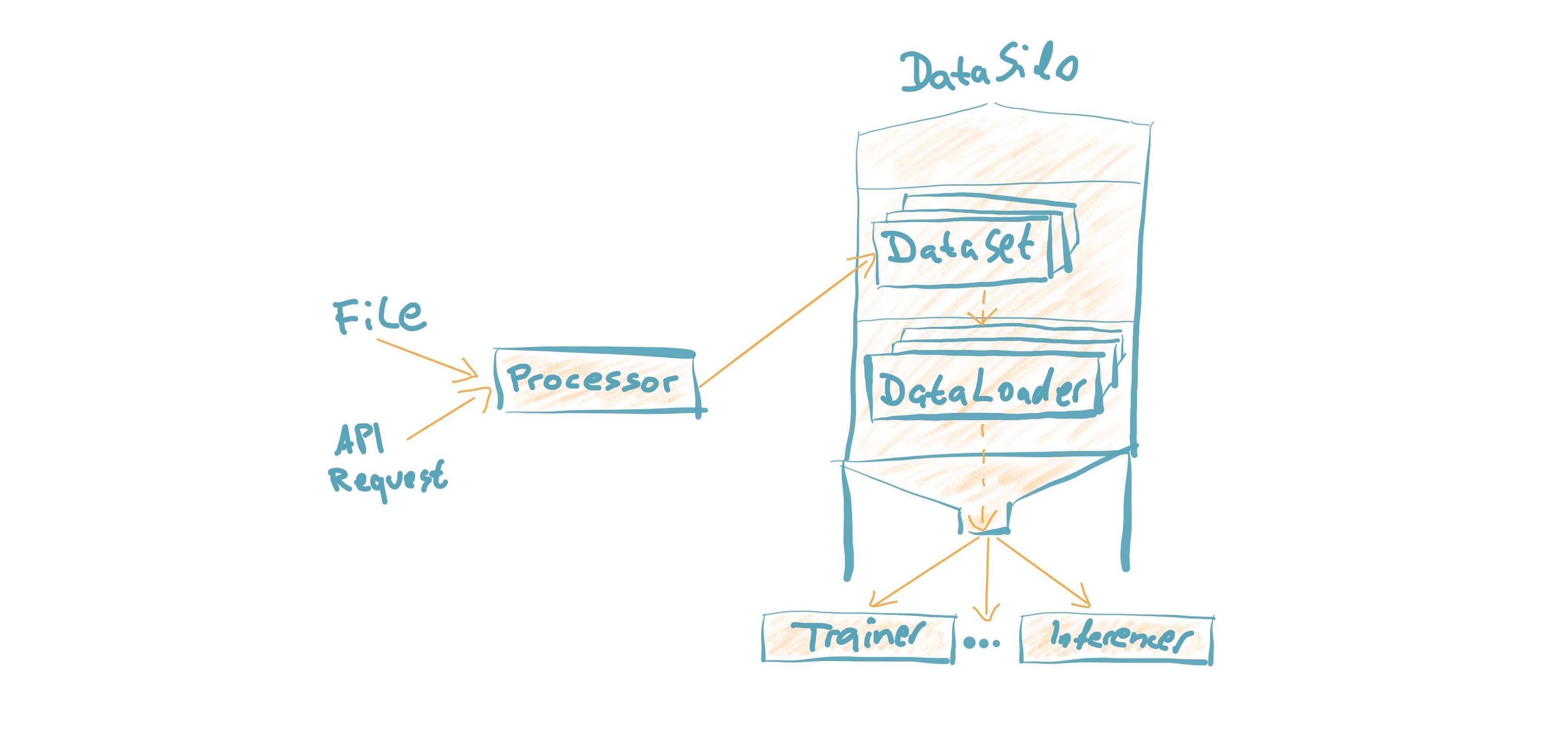
通过Processor类集成自定义数据集
强大的实验跟踪和执行
检查点与缓存:使用spot实例恢复训练并降低成本
简单 部署 和 可视化 以展示您的模型
任务 |
BERT |
RoBERTa* |
XLNet |
ALBERT |
DistilBERT |
XLMRoBERTa |
ELECTRA |
MiniLM |
|---|---|---|---|---|---|---|---|---|
文本分类 |
x |
x |
x |
x |
x |
x |
x |
x |
命名实体识别(NER) |
x |
x |
x |
x |
x |
x |
x |
x |
问答 |
x |
x |
x |
x |
x |
x |
x |
x |
语言模型微调 |
x |
|||||||
文本回归 |
x |
x |
x |
x |
x |
x |
x |
x |
多标签文本分类 |
x |
x |
x |
x |
x |
x |
x |
x |
提取嵌入 |
x |
x |
x |
x |
x |
x |
x |
x |
从头开始构建语言模型(LM) |
x |
|||||||
文本对分类 |
x |
x |
x |
x |
x |
x |
x |
x |
段落排序 |
x |
x |
x |
x |
x |
x |
x |
x |
文档检索(DPR) |
x |
x |
x |
x |
x |
x |
x |
* 包括CamemBERT和UmBERTo
**新功能** 想要在大规模上进行问答?查看 Haystack!
资源
文档
教程
教程1(构建块概述):Jupyter笔记本1 或 Colab 1
教程2(如何使用自定义数据集):Jupyter笔记本2 或 Colab 2
教程3(如何训练和展示您自己的问答模型):Colab 3
每个任务的示例脚本: FARM/examples/
演示
访问 https://demos.deepset.ai 来尝试一些模型
更多
安装
推荐(因为活跃开发)
git clone https://github.com/deepset-ai/FARM.git cd FARM pip install -r requirements.txt pip install --editable .
如果出现问题,请执行git pull。使用–editable标志将立即更新更改。
来自PyPi
pip install farm
注意:在Windows上,您可能需要 pip install farm -f https://download.pytorch.org/whl/torch_stable.html 以正确安装PyTorch
基本用法
1. 训练下游模型
FARM为模型训练提供两种模式
选项1:从配置运行实验

用例: 训练您的第一个模型,超参数优化,在多个下游任务上评估语言模型。
选项2:组装您自己的构建块
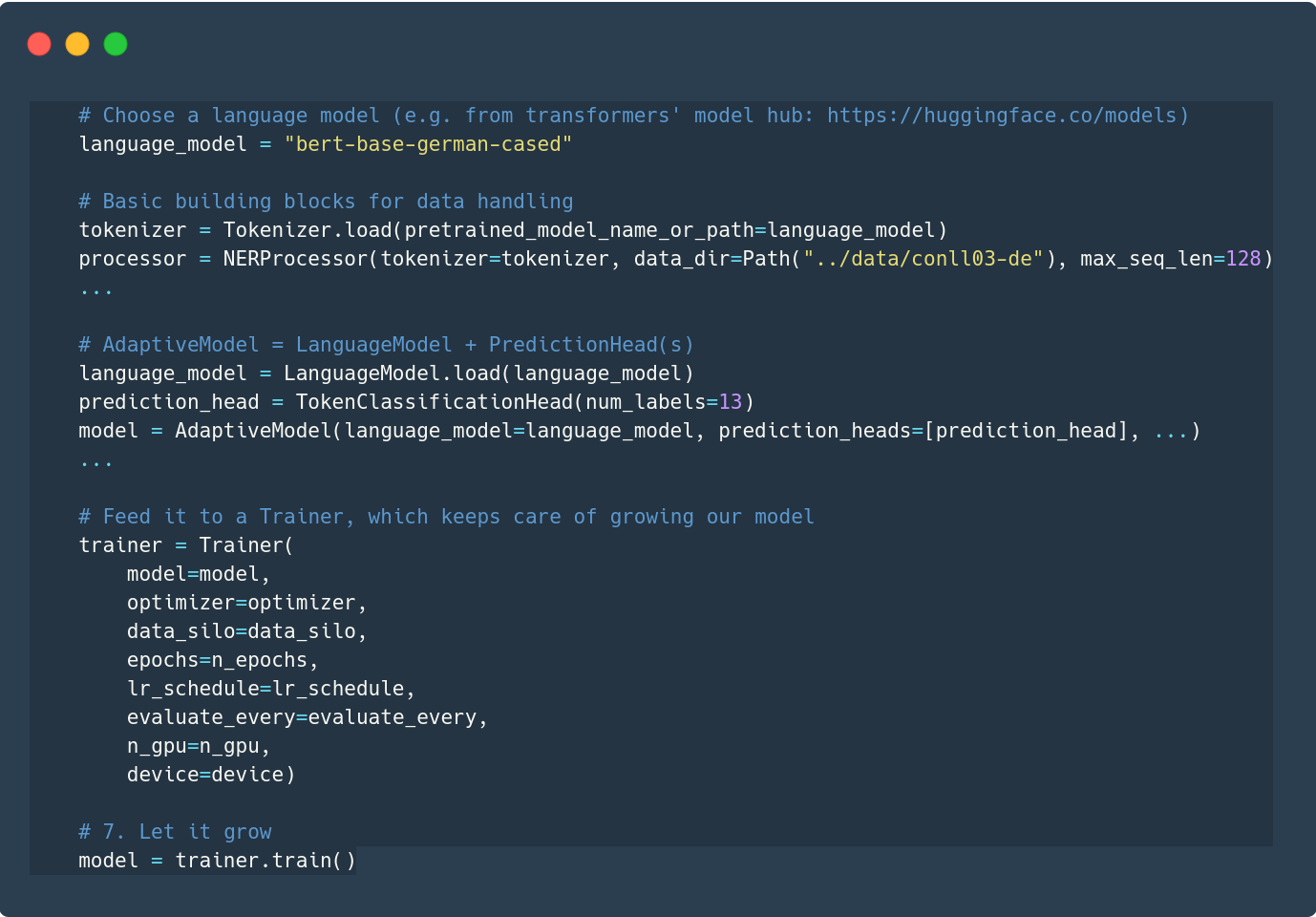
用例: 自定义数据集、语言模型、预测头...
您的模型训练的指标和参数将通过MLflow自动记录。我们提供公共MLflow服务器供测试和学习使用。查看它以查看您的实验结果!请记住:我们将定期开始删除所有实验,以确保每个人都能享受到良好的服务器性能!
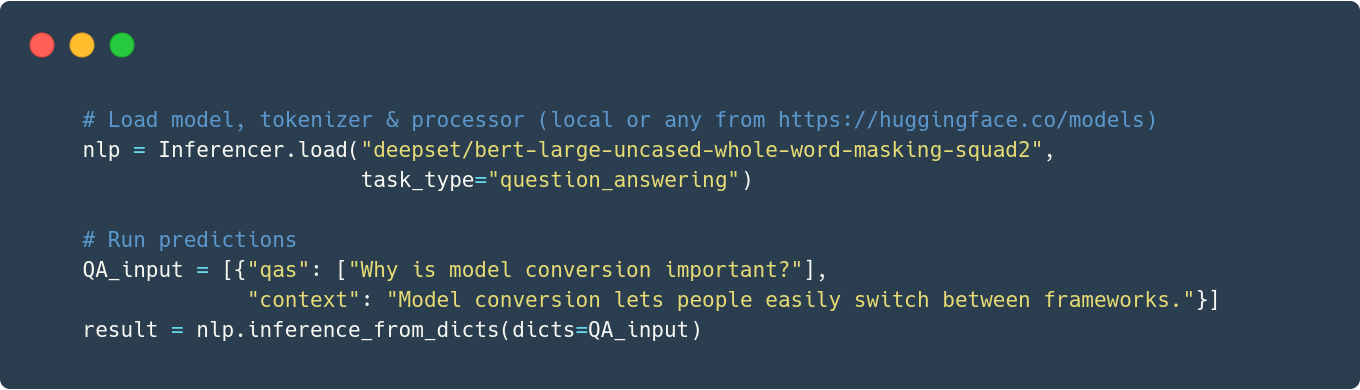
2. 运行推理
使用 公共模型 或您自己的模型获取预测
3. 展示您的模型(API + UI)
运行
docker-compose up在浏览器中打开 https://:3000
一个docker容器公开一个REST API(localhost:5000),另一个运行一个简单的演示UI(localhost:3000)。您可以使用它们中的任何一个,并挂载您自己的模型。有关详细信息,请参阅 文档。
高级用法
一旦您开始使用FARM,就有很多选项可以自定义您的管道并提高模型性能。让我们突出一些...
1. 优化器与学习率调度
虽然FARM为两者都提供了合理的默认值,但您可以轻松配置许多其他优化器和学习率调度
PyTorch、Apex或Transformers中的任何优化器
PyTorch或Transformers中的任何学习率调度
您可以通过传递一个字典到 initialize_optimizer() 来配置它们(请参阅 示例)。
2. 提前停止
使用早期停止,一旦选定的指标不再进一步改进,运行将停止,并且您将选择此点之前的最优模型。这有助于防止在小型数据集上过度拟合,并且如果您的模型不再进一步改进,可以减少训练时间(请参见示例)。
3. 类别不平衡
如果您在类别不平衡的数据上进行分类,请考虑使用类别权重。它们将损失函数调整为降低频繁类别的权重。您可以在初始化预测头时设置它们。
prediction_head = TextClassificationHead( class_weights=data_silo.calculate_class_weights(task_name="text_classification"), num_labels=len(label_list))`
4. 交叉验证
在小型数据集上获取更可靠的评估指标(请参见示例)
5. 缓存 & 检查点
如果您运行类似的管道(例如,仅实验模型参数),则可以节省时间:存储您的预处理数据集,并在下次从缓存中加载它。
data_silo = DataSilo(processor=processor, batch_size=batch_size, caching=True)
通过保存训练器的检查点来启动和停止训练
trainer = Trainer.create_or_load_checkpoint(
...
checkpoint_on_sigterm=True,
checkpoint_every=200,
checkpoint_root_dir=Path(“/opt/ml/checkpoints/training”),
resume_from_checkpoint=“latest”)
检查点包括所有重要状态(模型、优化器、学习率计划…),以便继续训练。如果您在训练过程中崩溃(例如,因为您正在使用spot云实例),这尤其有用。您可以每X步保存一次检查点或当接收到SIGTERM信号时。
6. 在AWS SageMaker上训练(包括Spot实例)
我们目前正在努力简化大规模训练和部署。作为第一步,我们正在添加对AWS SageMaker的支持。有趣的部分在于可以使用托管Spot实例,并且与常规EC2实例相比,可以节省约70%的成本。这对于从头开始训练模型尤其相关,我们在本次版本中引入了基本版本,并将在此后几周内进行改进。请参见教程以开始使用SageMaker进行下游任务的训练。
核心概念
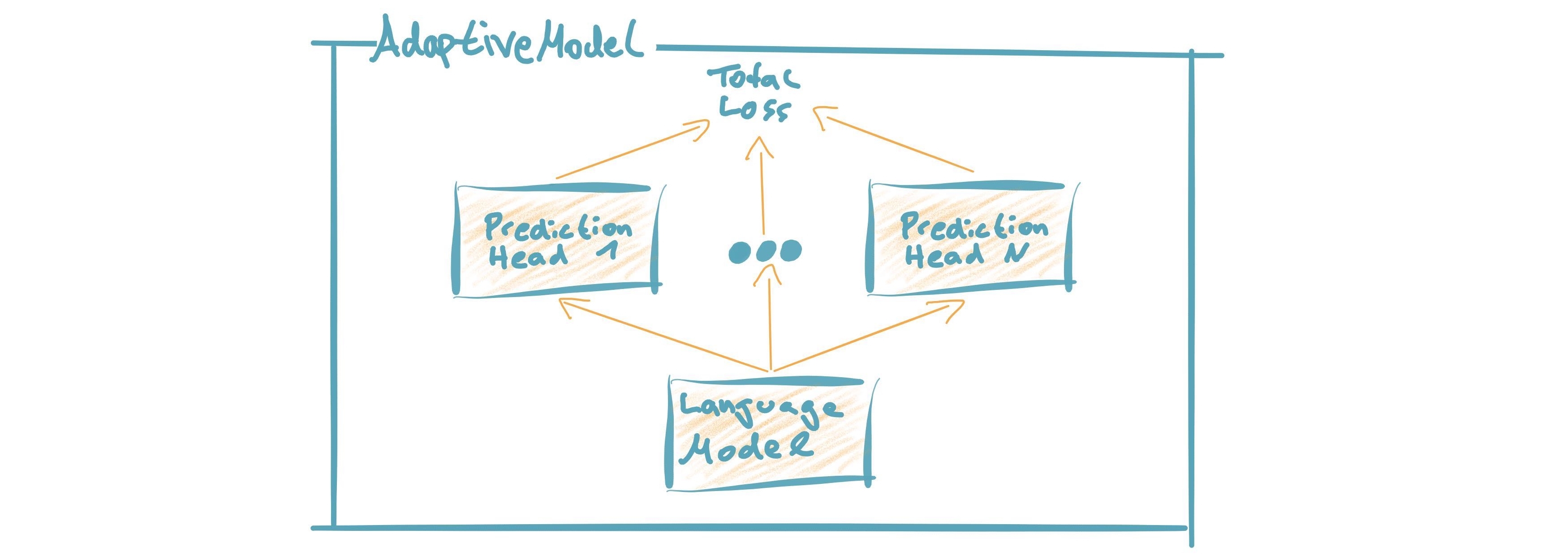
模型
AdaptiveModel = 语言模型 + 预测头(s)通过这种模块化方法,您可以轻松添加预测头(多任务学习)并重新用于不同类型的语言模型。(了解更多)
数据处理
可以通过自定义处理器加载自定义数据集。它将“原始数据”转换为PyTorch数据集。然后幕后处理大量工作,使其快速且易于调试。(了解更多)
推理时间基准
FARM有一个可配置的测试套件,用于使用推理引擎(PyTorch、ONNXRuntime)、批量大小、文档长度、最大序列长度和其他参数的组合来基准测试推理时间。 这里是当前FARM版本对问答推理的基准测试。
常见问题解答
1. 我应该使用哪种语言模型进行非英语NLP?如果您使用德语、法语、中文、日语或芬兰语,您可能想尝试使用您语言中预训练的BERT模型。您可以在这里查看由我们的朋友在HuggingFace上托管的可用模型列表,可以直接通过FARM访问。如果您使用的语言不在这些语言中(即使它确实在),我们鼓励您尝试XLM-Roberta(https://arxiv.org/pdf/1911.02116.pdf),它支持100种不同的语言,并且与单语言模型相比表现出惊人的强大性能。
2. 为什么需要独立的预测头? 需要预测头是为了将语言模型的一般语言理解能力适应到特定任务中。例如,命名实体识别和文档分类需要非常不同的输出格式。拥有独立的预测头类意味着它a)非常容易在不同的语言模型上重用预测头,b)简化了多任务学习。后者允许你添加代理任务,以促进你“真正目标”的学习。例如:你想将文档分类到类别中,并知道某些文档标签(例如作者)已经提供了对这个任务有帮助的信息。添加对分类这些元标签的附加任务可能会有所帮助。
3. 何时适应语言模型到领域语料库是有用的? 主要是在你的领域语言与原始模型训练的语言差异很大时。例如:你的语料库来自航空航天行业,包含大量工程术语。在词汇和语义上,这与维基百科文本非常不同。我们发现,这可以提高性能,尤其是如果你的下游任务使用的是相当小的领域数据集。相比之下,如果你有巨大的下游数据集,模型通常可以在下游训练过程中“即时”适应领域。
4. 我如何将语言模型适应到领域语料库? 主要有两种方法:你可以通过Tokenizer.add_tokens(["term_a", "term_b"...])扩展词汇,或者在你自己的领域文本语料库上微调你的模型(见示例)。
5. 如何将模型从/转换到HuggingFace的模型? 我们支持双向转换(见示例)。你也可以通过指定名称来加载HuggingFace模型库中的任何语言模型,例如LanguageModel.load("deepset/bert-base-cased-squad2")。
6. 如何将问答扩展到更大的文档集合? 目前最常见的是在问答模型前面放置一个快速的“检索器”。查看haystack以获取此类实现和更多你需要在生产环境中运行的问答功能。
7. 如何将问答定制到自己的领域? 我们通过首先在公共数据集(例如SQuAD、Natural Questions等)上训练模型,然后在该领域的几个自定义问答标签上进行微调,实现了高性能。查看haystack以获取更多详细信息和一个问答标注工具。
8. 我的GPU内存不足。如何以合理的批量大小进行训练? 使用梯度累积!它结合多个批次后再应用反向传播。在FARM中,只需将grad_acc_steps参数在initialize_optimizer()和Trainer()中设置为要组合的批次数(例如,grad_acc_steps=2和batch_size=16将导致32个有效批量的大小)。
致谢
FARM基于HuggingFace的伟大Transformers存储库的部分。它利用了他们模型的实现和分词器。
FARM是一个社区的努力!它的许多关键部分都是由我们的FARMers实现的。感谢所有贡献者!
原始BERT模型和论文由Jacob Devlin、Ming-Wei Chang、Kenton Lee和Kristina Toutanova发表。
引用
目前没有关于FARM的已发表论文。如果您想使用或引用我们的框架,请包含到这个仓库的链接。如果您正在使用德国BERT模型,您可以链接我们的博客文章,其中描述了其训练细节和性能。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。