Pytorch的ESRNN实现



项目描述





Pytorch的ES-RNN实现
Pytorch实现了Smyl提出的ES-RNN算法,是M4预测竞赛的获胜提交。该类封装了fit和predict方法,以方便与机器学习管道交互,以及评估和数据整理实用工具。由卡内基梅隆大学的Autonlab成员开发。
安装需求
- numpy>=1.16.1
- pandas>=0.25.2
- pytorch>=1.3.1
安装
此代码是一个正在进行中的工作,GitHub上的任何贡献或问题都欢迎:https://github.com/kdgutier/esrnn_torch
您可以使用以下命令从Python包索引安装已发布版本的ESRNN:
pip install ESRNN
用法
输入数据
fit方法接收训练pandas数据框X_df和y_df,格式为长格式。可选地,使用X_test_df和y_test_df来计算样本外性能。
X_df必须包含列['unique_id', 'ds', 'x']y_df必须包含以下列['unique_id', 'ds', 'y']X_test_df必须包含以下列['unique_id', 'ds', 'x']y_test_df必须包含以下列['unique_id', 'ds', 'y']以及一个用于比较的基准模型(默认'y_hat_naive2')。
对于以上所有内容
- 列
'unique_id'是时间序列标识符,列'ds'表示日期时间。 - 列
'x'是外生分类特征。 - 列
'y'是目标变量。 - 列
'y'不允许负值,且所有时间序列的第一个条目必须 大于 0。
数据框 X 和 y 必须包含相同的 'unique_id' 和 'ds' 列的值,并且必须是 平衡的,即日期之间没有 间隔。
X_df |
y_df |
X_test_df |
y_test_df |
|---|---|---|---|
 |
 |
 |
 |
M4 示例
from ESRNN.m4_data import prepare_m4_data
from ESRNN.utils_evaluation import evaluate_prediction_owa
from ESRNN import ESRNN
X_train_df, y_train_df, X_test_df, y_test_df = prepare_m4_data(dataset_name='Yearly',
directory = './data',
num_obs=1000)
# Instantiate model
model = ESRNN(max_epochs=25, freq_of_test=5, batch_size=4, learning_rate=1e-4,
per_series_lr_multip=0.8, lr_scheduler_step_size=10,
lr_decay=0.1, gradient_clipping_threshold=50,
rnn_weight_decay=0.0, level_variability_penalty=100,
testing_percentile=50, training_percentile=50,
ensemble=False, max_periods=25, seasonality=[],
input_size=4, output_size=6,
cell_type='LSTM', state_hsize=40,
dilations=[[1], [6]], add_nl_layer=False,
random_seed=1, device='cpu')
# Fit model
# If y_test_df is provided the model
# will evaluate predictions on
# this set every freq_test epochs
model.fit(X_train_df, y_train_df, X_test_df, y_test_df)
# Predict on test set
y_hat_df = model.predict(X_test_df)
# Evaluate predictions
final_owa, final_mase, final_smape = evaluate_prediction_owa(y_hat_df, y_train_df,
X_test_df, y_test_df,
naive2_seasonality=1)
总体加权平均
用于量化特定模型在各个时间序列上总体误差的指标是 M4 竞赛提出的总体加权平均(OWA)。该指标通过获取模型所有时间序列的对称平均绝对百分比误差(sMAPE)和平均绝对缩放误差(MASE)的平均值来计算,同时也会计算 Naive2 预测的平均值。sMAPE 和 MASE 都是规模无关的。这些测量值计算如下:
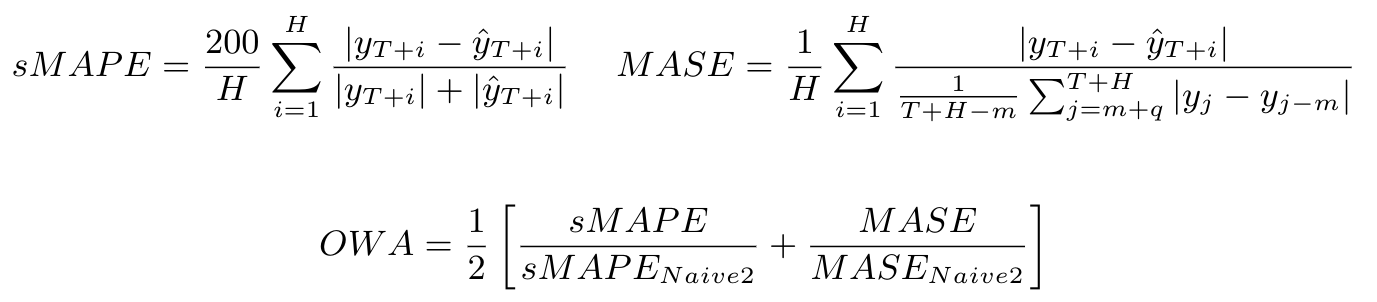
当前结果
在这里,我们直接使用模型与原始实现进行比较。值得注意的是,这些结果不包括在 ESRNN 论文 中提到的集成方法。
M4 竞赛结果.
| 数据集 | 我们的 OWA | M4 OWA (Smyl) |
|---|---|---|
| 年度 | 0.785 | 0.778 |
| 季度 | 0.879 | 0.847 |
| 月度 | 0.872 | 0.836 |
| 小时 | 0.615 | 0.920 |
| 周 | 0.952 | 0.920 |
| 日 | 0.968 | 0.920 |
复制 M4 结果
复制 M4 结果就像运行以下代码行(针对每个频率)一样简单(在通过 pip 安装包后执行)
python -m ESRNN.m4_run --dataset 'Yearly' --results_directory '/some/path' \
--gpu_id 0 --use_cpu 0
使用 --help 获取每个参数的描述
python -m ESRNN.m4_run --help
作者
这个存储库是由卡内基梅隆大学的 AutonLab 研究人员和 Orax 数据科学家共同开发的。
- Kin Gutierrez - kdgutier
- Cristian Challu - cristianchallu
- Federico Garza - FedericoGarza - 邮件
- Max Mergenthaler - mergenthaler
许可证
本项目采用 MIT 许可证 - 有关详细信息,请参阅 LICENSE 文件。
参考文献


下载文件
下载适用于您平台的文件。如果您不确定要选择哪个,请了解更多关于 安装包 的信息。
源代码分发
构建分发
ESRNN-0.1.3.tar.gz的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 7f7227bf43f61183a101d9a7c82645d6aee2c180d004eae73a86eb74c5e4e5e9 |
|
| MD5 | 631290a3fb650137fe5320d1520372d9 |
|
| BLAKE2b-256 | 8c36105c4bf3d4abf5128b7083b5b5805118daa3b46c7ca3ff5282121372bb0e |
ESRNN-0.1.3-py3-none-any.whl的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 7c8a7eeb242f33befbcc871f3eb0869c07f1a7bace0af406b16b45429946d6db |
|
| MD5 | 1dad8c8eff43a49defaa37bca27cdcac |
|
| BLAKE2b-256 | db94aba0b159eccf32f85c51ed04c885fbb13f8b89ac35b7b0efef1df900db9a |