易于使用的文本提取器,从PDF、DOC、DOCX等文档类型中提取文本,使用优秀的Textract,包括必要时使用OCR(通过Tesseract)。

项目描述



易于使用的文本提取器,从PDF、DOC、DOCX等文档中提取文本,包括必要时使用OCR(通过Tesseract)。
此库可以从Textract支持的任何类型中提取文本。
此库的存在归功于Textract团队和Tesseract的出色工作。
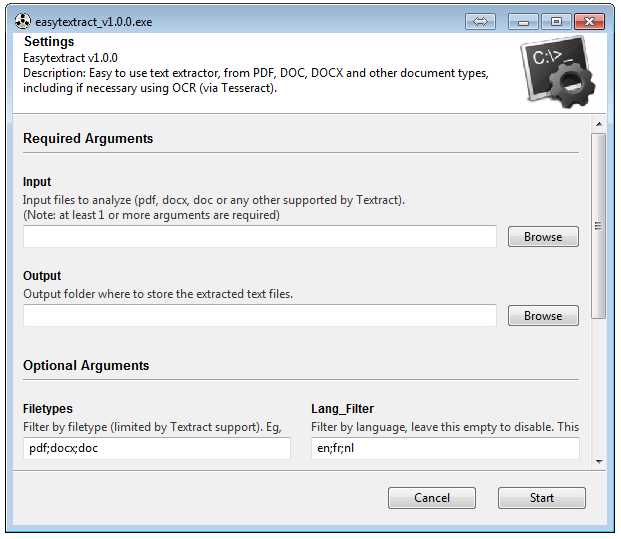
它运行在Python 2.7下(尽管可能需要进行一些修改,但它可能与Python 3兼容,但这未经测试或开发)。
安装
通常,请参阅Textract文档以安装从所需文件类型提取文本所需的所有软件。
本节其余部分将描述基本设置的详细信息。
Python(所有平台:Linux、MacOSX、Windows)
要从Python运行Easytextract,您需要Python > 2.7,并且使用pip安装textract。
然后安装以下库以支持您想要的文件类型
对于PDF,使用pip安装PDFMiner。为了获取更多功能和更好的PDF提取,您可以安装pdftotext,它是poppler或Xpdf的一部分。
对于OCR,您需要安装Tesseract >= 3.02(但不能是3.0或4!)和pdftoppm。
对于DOCX,使用pip安装python-docx2txt。
对于DOC,在Windows上的位置安装antiword:C:antiwordantiword.exe,对于Linux和Mac,您需要更改脚本中的路径。
要支持其他类型(如音频),请参阅https://textract.readthedocs.io/en/stable/#currently-supporting
WINDOWS
使用Windows二进制文件(仅适用于Windows 64位),直接支持PDF和DOCX。
要启用OCR,并在您的平台上预先安装tesseract >= v3.02(不能是v4!)和pdftoppm.exe。
对于DOC支持(DOCX已经是本地支持),您还需要在C:antiwordantiword.exe安装antiword。
许可证
easytextract最初由Stephen Larroque <LRQ3000>为比利时Coma Science Group - GIGA Consciousness - CHU de Liege制作。该应用程序的许可证为MIT许可证。


easytextract-1.1.5.tar.gz的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | d94f74ba1f1db653d05c70097be43dea016184ef747144522b9d4c5682c9c9f2 |
|
| MD5 | a6936691da3cb9b8d1b9b8607a69561e |
|
| BLAKE2b-256 | fb254417e03841cbc0fa4c716a2677ed64004dded0860df5487af2e1b36060be |