使用离散世界模型掌握Atari

项目描述
状态: 稳定发布

使用离散世界模型掌握Atari
DreamerV2是第一个在Atari基准测试中实现人类水平表现的代理世界模型。DreamerV2使用相同数量的经验和计算,也优于顶级无模型代理Rainbow和IQN的最终性能。此存储库中的实现交替训练世界模型、训练策略、收集经验和在单个GPU上运行。

如果您觉得这个代码有用,请在您的论文中进行引用
@article{hafner2020dreamerv2,
title={Mastering Atari with Discrete World Models},
author={Hafner, Danijar and Lillicrap, Timothy and Norouzi, Mohammad and Ba, Jimmy},
journal={arXiv preprint arXiv:2010.02193},
year={2020}
}
方法
DreamerV2是第一个在Atari基准测试中实现人类水平表现的代理世界模型。DreamerV2使用相同数量的经验和计算,也优于顶级无模型代理Rainbow和IQN的最终性能。此存储库中的实现交替训练世界模型、训练策略、收集经验和在单个GPU上运行。
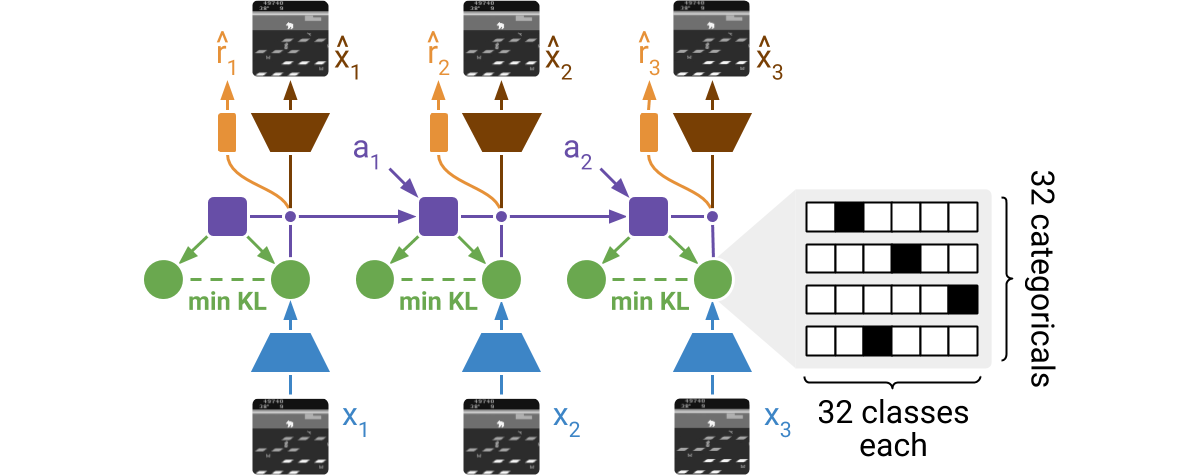
DreamerV2直接从高维输入图像中学习环境模型。为此,它使用紧凑的学得状态进行预测。状态由一个确定性部分和几个被采样的分类变量组成。这些分类变量的先验通过KL损失学习。世界模型通过端到端梯度学习,意味着密度的梯度被设置为样本的梯度。
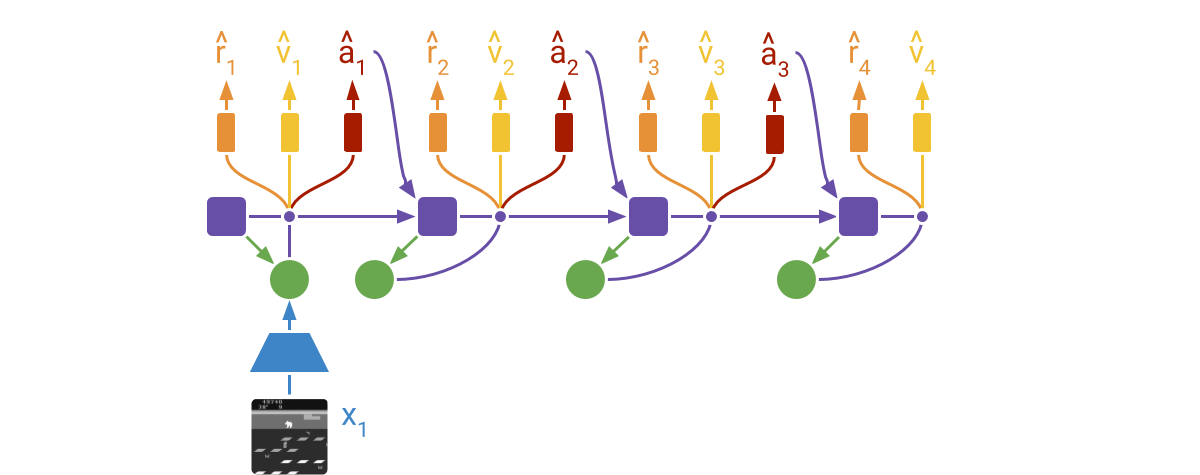
DreamerV2从潜在状态的想象轨迹中学习actor和critic网络。轨迹从先前遇到序列的编码状态开始。然后,世界模型使用所选动作和其学得的状态先验进行预测。评论家使用时间差学习训练,actor通过强化和端到端梯度训练以最大化值函数。
更多信息
使用包
在新的环境中运行DreamerV2的最简单方法是使用pip安装包 pip3 install dreamerv2。代码自动检测环境是否使用离散或连续动作。以下是一个在MiniGrid环境中训练DreamerV2的用法示例
import gym
import gym_minigrid
import dreamerv2.api as dv2
config = dv2.defaults.update({
'logdir': '~/logdir/minigrid',
'log_every': 1e3,
'train_every': 10,
'prefill': 1e5,
'actor_ent': 3e-3,
'loss_scales.kl': 1.0,
'discount': 0.99,
}).parse_flags()
env = gym.make('MiniGrid-DoorKey-6x6-v0')
env = gym_minigrid.wrappers.RGBImgPartialObsWrapper(env)
dv2.train(env, config)
手动说明
要修改DreamerV2代理,请克隆仓库并按照以下说明操作。如果您不希望在系统上安装依赖项,也可以使用可用的Dockerfile。
获取依赖项
pip3 install tensorflow==2.6.0 tensorflow_probability ruamel.yaml 'gym[atari]' dm_control
在Atari上进行训练
python3 dreamerv2/train.py --logdir ~/logdir/atari_pong/dreamerv2/1 \
--configs atari --task atari_pong
在DM控制上进行训练
python3 dreamerv2/train.py --logdir ~/logdir/dmc_walker_walk/dreamerv2/1 \
--configs dmc --task dmc_walker_walk
监控结果
tensorboard --logdir ~/logdir
生成图表
python3 common/plot.py --indir ~/logdir --outdir ~/plots \
--xaxis step --yaxis eval_return --bins 1e6
Docker说明
Dockerfile 允许您在系统中不安装依赖项的情况下运行DreamerV2。这要求您已经设置了具有GPU访问权限的Docker。
检查您的设置
docker run -it --rm --gpus all tensorflow/tensorflow:2.4.2-gpu nvidia-smi
在Atari上进行训练
docker build -t dreamerv2 .
docker run -it --rm --gpus all -v ~/logdir:/logdir dreamerv2 \
python3 dreamerv2/train.py --logdir /logdir/atari_pong/dreamerv2/1 \
--configs atari --task atari_pong
在DM控制上进行训练
docker build -t dreamerv2 . --build-arg MUJOCO_KEY="$(cat ~/.mujoco/mjkey.txt)"
docker run -it --rm --gpus all -v ~/logdir:/logdir dreamerv2 \
python3 dreamerv2/train.py --logdir /logdir/dmc_walker_walk/dreamerv2/1 \
--configs dmc --task dmc_walker_walk
提示
-
高效调试。您可以使用
debug配置,例如--configs atari debug。这会减少批量大小,增加评估频率,并禁用tf.function图编译,以便逐行调试。 -
无限梯度范数。这是正常的,请参阅 混合精度 指南中的损失缩放部分。您可以通过将
--precision 32传递给训练脚本来禁用混合精度。混合精度更快,但原则上可能导致数值不稳定。 -
访问记录的指标。指标以TensorBoard和JSON行格式存储。您可以直接使用
pandas.read_json()加载它们。绘图脚本还将多个运行的分箱和汇总指标存储到一个单独的JSON文件中,以便于手动绘图。


dreamerv2-2.2.0.tar.gz的哈希
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | e186f0ae460a11c7f934a1cf6d55766988a0287538e73f3648fb16c7d6a0adf7 |
|
| MD5 | 3a094b267d5657fd07261fed6f3c810e |
|
| BLAKE2b-256 | 54f904ced18ef912b55f267bacc069b9a6b04801f4e77df33ace6afc62351037 |







