为任何机器学习模型生成多样的反事实解释。


项目描述







Diverse Counterfactual Explanations (DiCE) for ML
如何解释机器学习模型,使得解释既忠实于模型又对人们可解释?
Ramaravind K. Mothilal, Amit Sharma, Chenhao Tan
FAT* ‘20论文 | 文档 | 示例笔记本 | 实时Jupyter笔记本

博客文章: 使用多种反事实解释机器学习
案例研究: Towards Data Science(酒店预订)| Analytics Vidhya(泰坦尼克号数据集)
解释对于机器学习至关重要,尤其是在机器学习系统被用于影响社会中关键领域的决策时,例如金融、医疗保健、教育和刑事司法。然而,大多数解释方法都依赖于对ML模型的一种近似来创建可解释的解释。例如,考虑一个人申请贷款但被金融公司的贷款分配算法拒绝的情况。通常,公司可能会解释为什么拒绝贷款,例如,由于“信用记录不佳”。然而,这种解释并不能帮助这个人决定下一步应该做什么来提高未来被批准的机会。关键的是,最重要的特征可能不足以翻转算法的决定,在实践中,甚至可能无法改变,如性别和种族。
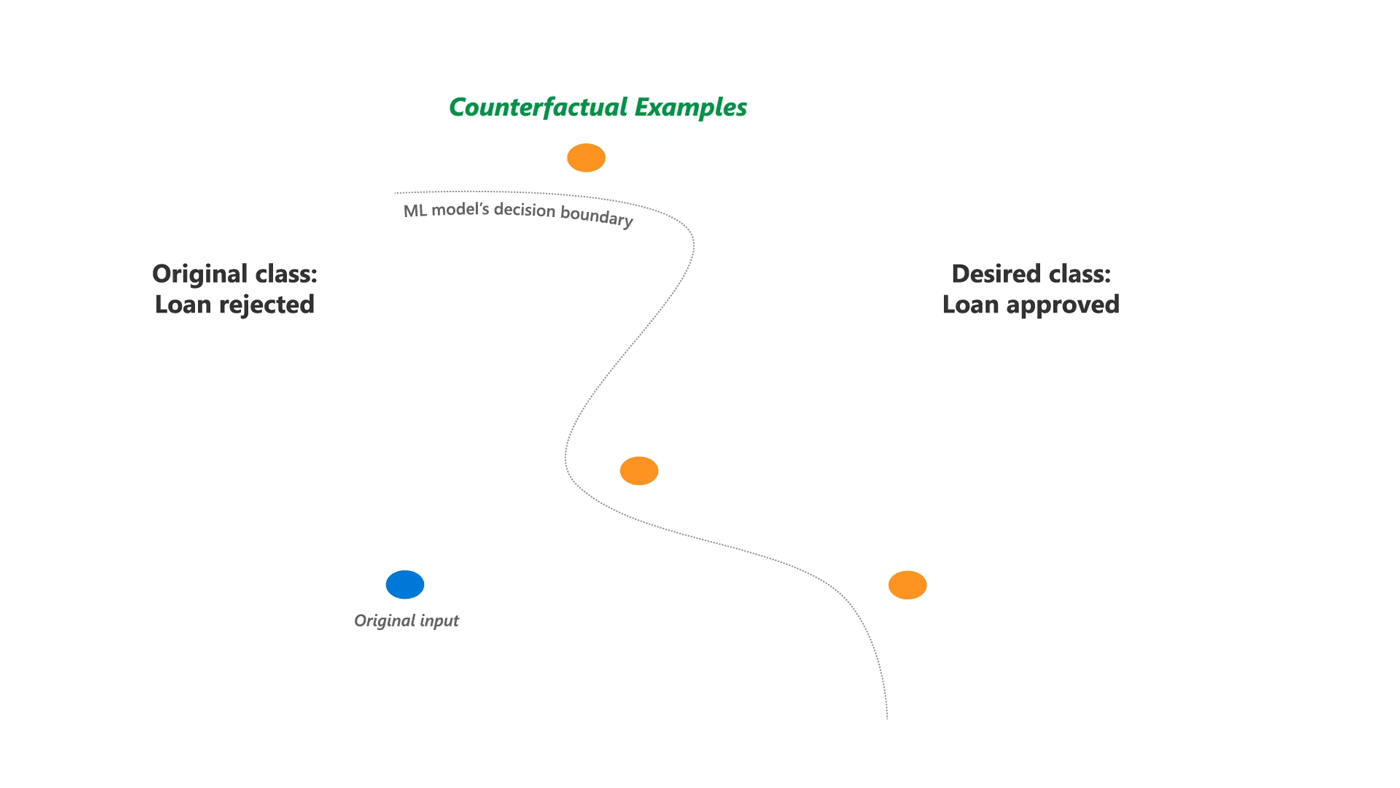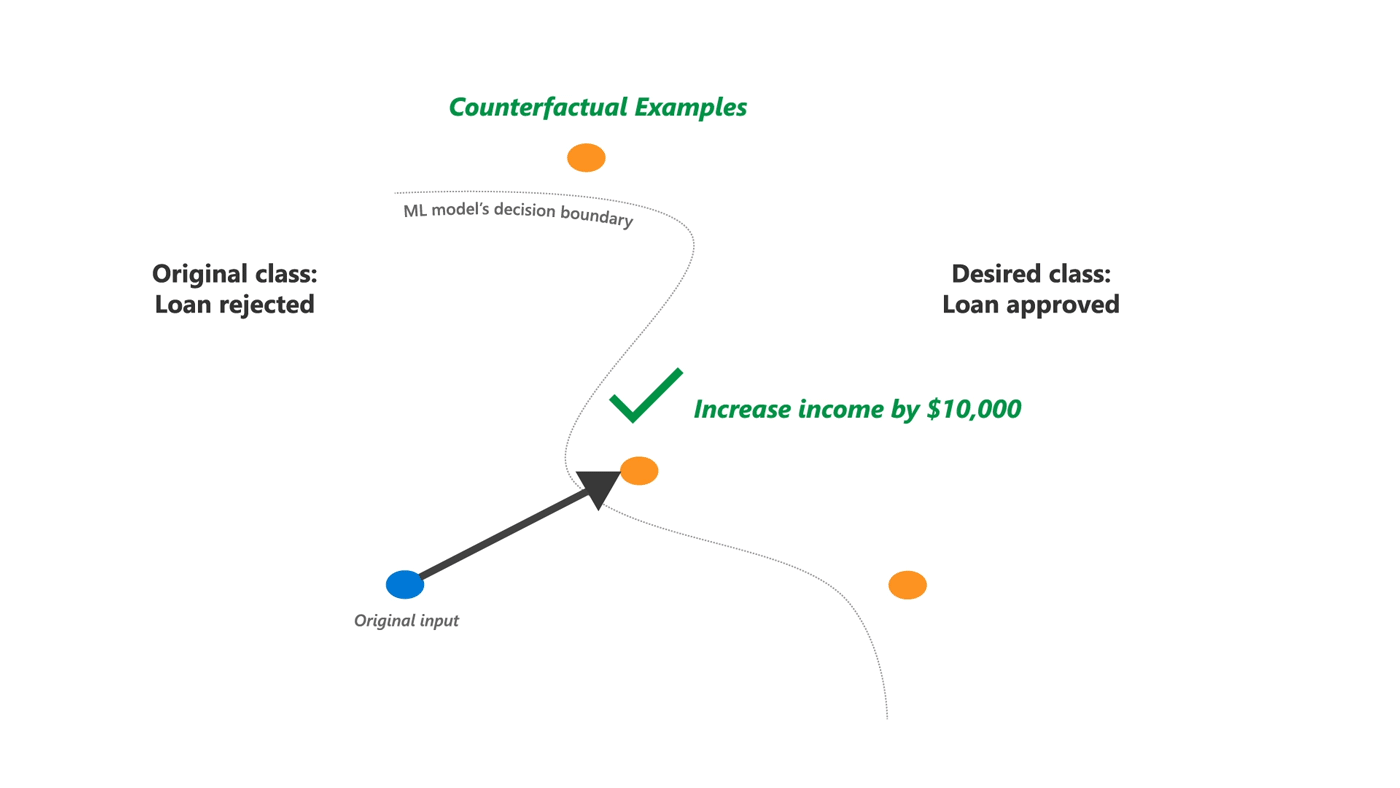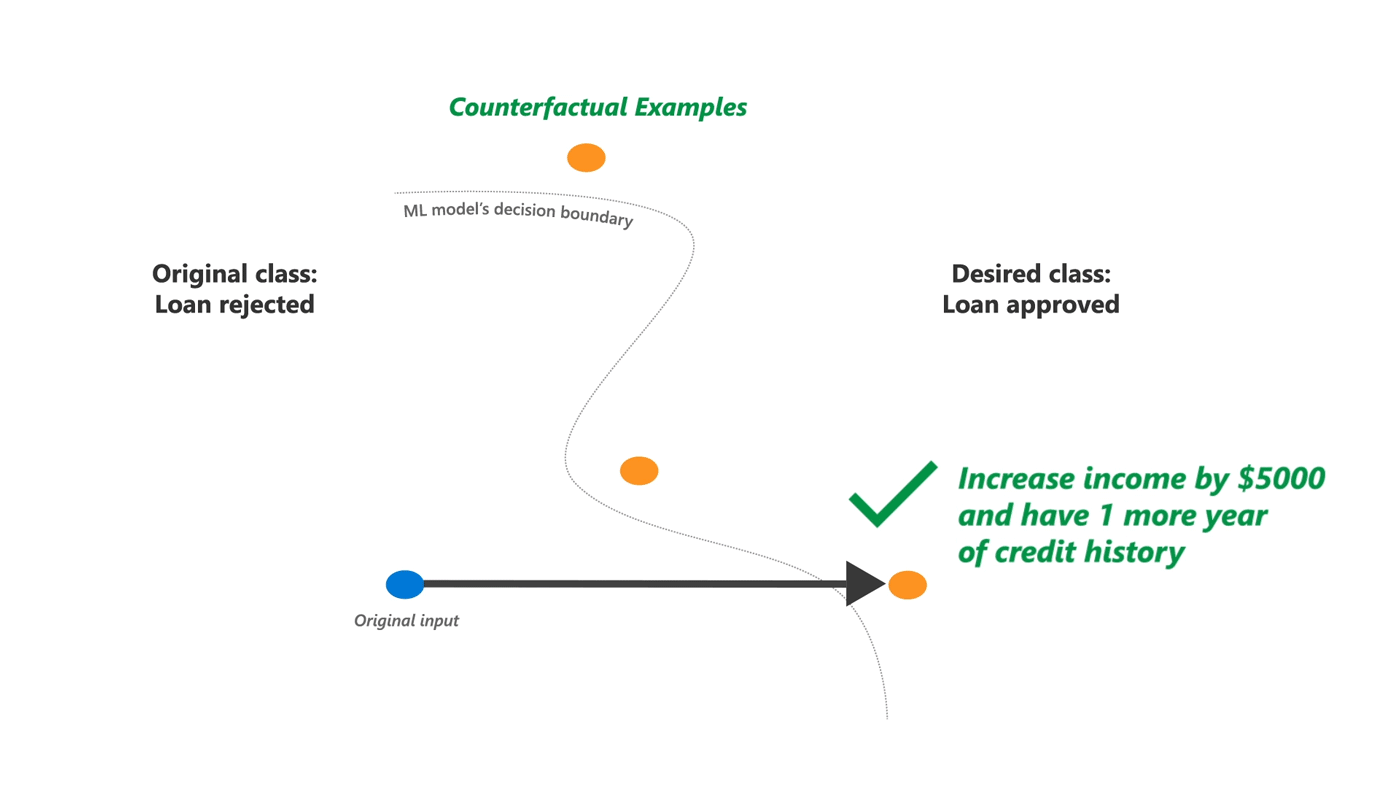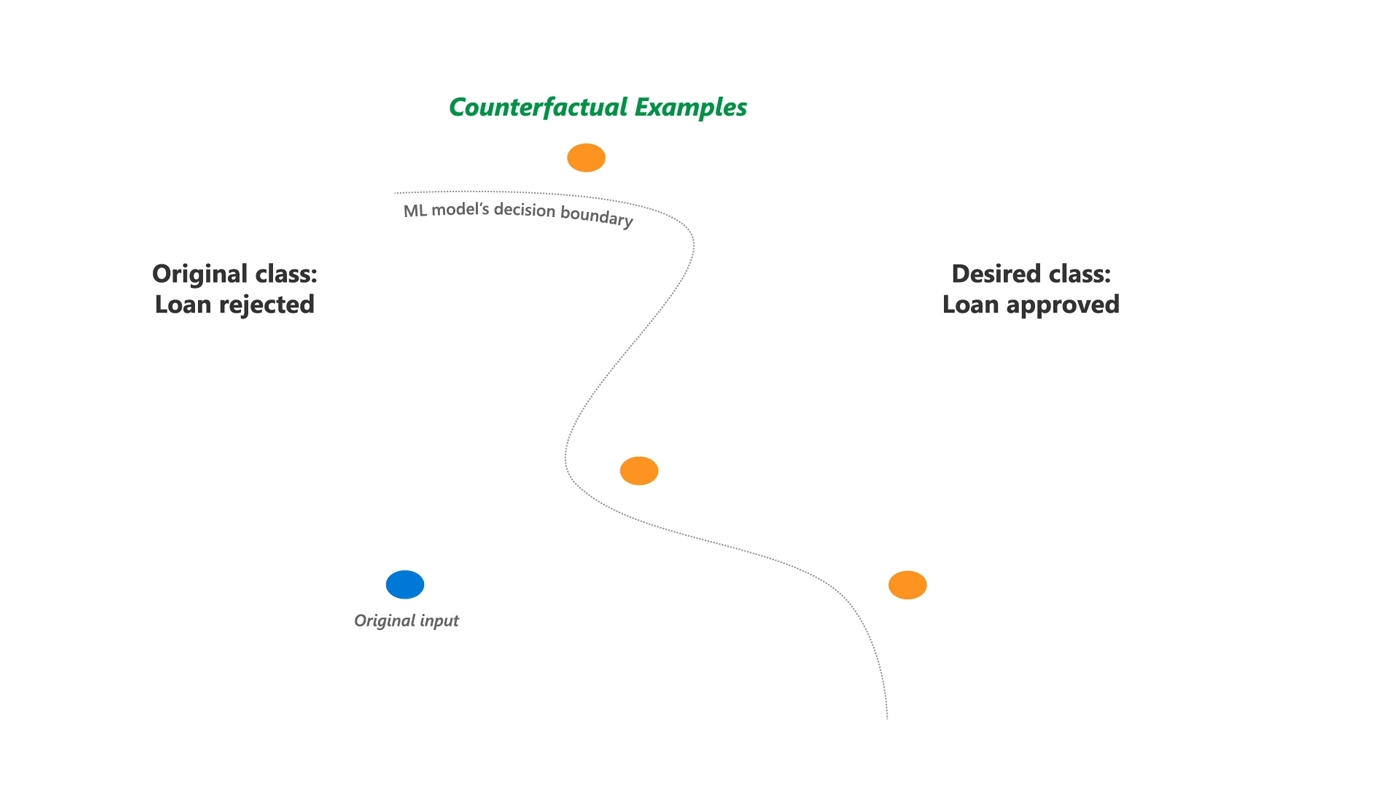
DiCE实现了反事实(CF)解释,通过展示具有特征扰动的同一个人版本来提供这种信息,例如,如果你的收入高出10,000美元,你就会得到贷款。换句话说,它提供了对模型输出的“如果……将会怎样”的解释,可以成为其他解释方法的有用补充,无论是对于最终用户还是模型开发者。
然而,除了简单的线性模型外,很难为任何机器学习模型生成有效的反事实示例。DiCE基于最近的研究,为任何ML模型生成反事实解释。核心思想是将寻找此类解释设定为一个优化问题,类似于寻找对抗性示例。关键的区别是,对于解释,我们需要改变机器学习模型输出的扰动,但又是多样化的并且可改变的。因此,DiCE支持生成一组反事实解释,并具有可调参数以实现解释的多样性和与原始输入的接近度。它还支持对特征的简单约束,以确保生成的反事实示例的可行性。
安装DICE
DiCE支持Python 3+。DiCE的稳定版本可在PyPI上获得。
pip install dice-mlDiCE也可在conda-forge上找到。
conda install -c conda-forge dice-ml要安装DiCE的最新(开发)版本及其依赖项,请克隆此存储库,然后从存储库的最高文件夹运行pip install
pip install -e .如果您遇到任何问题,请尝试手动安装依赖项。
pip install -r requirements.txt
# Additional dependendies for deep learning models
pip install -r requirements-deeplearning.txt
# For running unit tests
pip install -r requirements-test.txt开始使用DiCE
使用DiCE,生成解释是一个简单的三步过程:设置数据集,训练模型,然后调用DiCE生成任何输入的反事实示例。DiCE还可以与预训练模型一起使用,无论是否具有原始训练数据。
import dice_ml
from dice_ml.utils import helpers # helper functions
from sklearn.model_selection import train_test_split
dataset = helpers.load_adult_income_dataset()
target = dataset["income"] # outcome variable
train_dataset, test_dataset, _, _ = train_test_split(dataset,
target,
test_size=0.2,
random_state=0,
stratify=target)
# Dataset for training an ML model
d = dice_ml.Data(dataframe=train_dataset,
continuous_features=['age', 'hours_per_week'],
outcome_name='income')
# Pre-trained ML model
m = dice_ml.Model(model_path=dice_ml.utils.helpers.get_adult_income_modelpath(),
backend='TF2', func="ohe-min-max")
# DiCE explanation instance
exp = dice_ml.Dice(d,m)对于任何给定的输入,我们现在可以生成反事实解释。例如,以下输入导致类别0(低收入),我们想知道什么最小的变化会导致预测为1(高收入)。
# Generate counterfactual examples
query_instance = test_dataset.drop(columns="income")[0:1]
dice_exp = exp.generate_counterfactuals(query_instance, total_CFs=4, desired_class="opposite")
# Visualize counterfactual explanation
dice_exp.visualize_as_dataframe()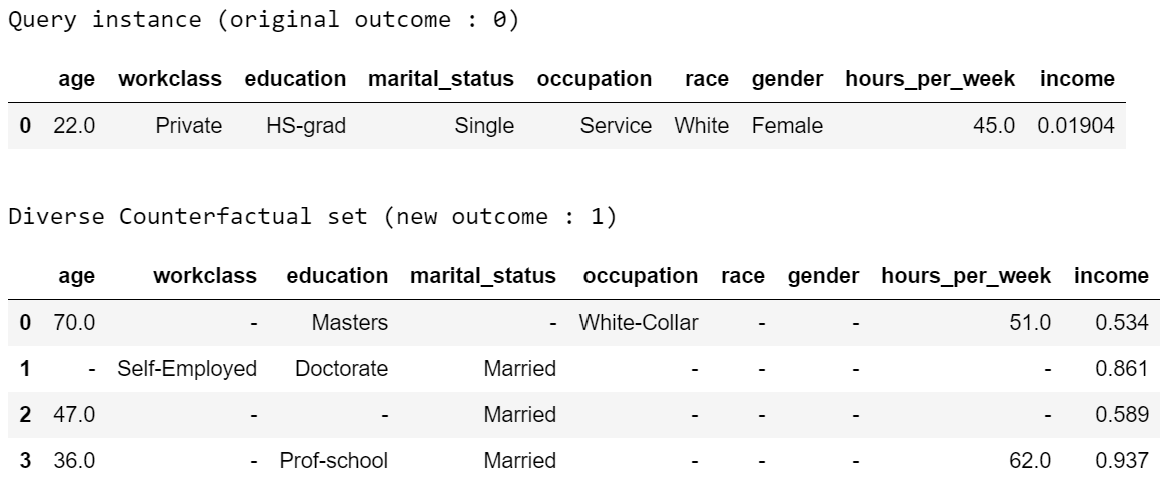
您可以使用以下方式保存生成的反事实示例。
# Save generated counterfactual examples to disk
dice_exp.cf_examples_list[0].final_cfs_df.to_csv(path_or_buf='counterfactuals.csv', index=False)有关更多详细信息,请查看docs/source/notebooks文件夹。以下是一些示例笔记本
入门:为sklearn、tensorflow或pytorch二分类器生成CF示例并计算特征重要性得分。
解释多类分类器和回归器:为多类分类器或回归器生成CF解释。
局部和全局特征重要性:使用生成的反事实估计局部和全局特征重要性得分。
对反事实生成提供约束:指定要变动的特征及其有效反事实示例的可允许范围。
生成反事实的支持方法
DiCE可以使用以下方法生成反事实示例。
模型无关方法
随机抽样
KD-Tree(用于训练数据内的反事实)
遗传算法
有关使用这些方法的代码示例,请参阅模型无关笔记本。
基于梯度的方法
在Mothilal等人(2020)中描述的基于显式损失的方法(深度学习模型的默认方法)。
在Mahajan等人(2019)中描述的基于变分自动编码器(VAE)的方法(请参阅BaseVAE 笔记本)。
后两种方法需要可微分的模型,如神经网络。如果您对特定方法感兴趣,请在此处提出问题。
支持的使用案例
数据
DiCE不需要访问完整数据集。它只需要每个特征的元数据属性(连续特征的min和max值以及分类特征的级别)。因此,对于敏感数据,数据集可以作为
d = data.Data(features={
'age':[17, 90],
'workclass': ['Government', 'Other/Unknown', 'Private', 'Self-Employed'],
'education': ['Assoc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Prof-school', 'School', 'Some-college'],
'marital_status': ['Divorced', 'Married', 'Separated', 'Single', 'Widowed'],
'occupation':['Blue-Collar', 'Other/Unknown', 'Professional', 'Sales', 'Service', 'White-Collar'],
'race': ['Other', 'White'],
'gender':['Female', 'Male'],
'hours_per_week': [1, 99]},
outcome_name='income')模型
我们支持预训练模型以及训练模型。以下是一个使用Tensorflow的简单示例。
sess = tf.InteractiveSession()
# Generating train and test data
train, _ = d.split_data(d.normalize_data(d.one_hot_encoded_data))
X_train = train.loc[:, train.columns != 'income']
y_train = train.loc[:, train.columns == 'income']
# Fitting a dense neural network model
ann_model = keras.Sequential()
ann_model.add(keras.layers.Dense(20, input_shape=(X_train.shape[1],), kernel_regularizer=keras.regularizers.l1(0.001), activation=tf.nn.relu))
ann_model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
ann_model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.01), metrics=['accuracy'])
ann_model.fit(X_train, y_train, validation_split=0.20, epochs=100, verbose=0, class_weight={0:1,1:2})
# Generate the DiCE model for explanation
m = model.Model(model=ann_model)有关使用DiCE与sklearn和PyTorch模型的相关代码示例,请参阅入门笔记本。
解释
我们通过突出显示特征的变化来可视化解释。我们计划也支持英文解释!
反事实解释的可行性
我们承认并非所有反事实解释都可能对用户可行。一般来说,与个人资料更接近的反事实将更可行。多样性也很重要,可以帮助个人在多个可能选项之间进行选择。
DiCE提供可调参数以生成不同类型的解释,包括多样性和接近度。
dice_exp = exp.generate_counterfactuals(query_instance,
total_CFs=4, desired_class="opposite",
proximity_weight=1.5, diversity_weight=1.0)此外,某些特征可能比其他特征更难更改(例如,教育水平可能比每周工作时间更难更改)。DiCE允许通过指定特征权重来输入更改特征相对难度。较高的特征权重表示该特征比其他特征更难更改。例如,一种方法是将中位数与平均绝对偏差作为更改连续特征的相对难度的度量。默认情况下,DiCE内部计算此值并将连续特征之间的距离除以特征值在训练集中的平均绝对偏差。我们也可以通过feature_weights参数分配不同的值。
# assigning new weights
feature_weights = {'age': 10, 'hours_per_week': 5}
# Now generating explanations using the new feature weights
dice_exp = exp.generate_counterfactuals(query_instance,
total_CFs=4, desired_class="opposite",
feature_weights=feature_weights)最后,一些特征是不可能更改的,例如年龄或种族。因此,DiCE也允许输入要变动的特征列表。
dice_exp = exp.generate_counterfactuals(query_instance,
total_CFs=4, desired_class="opposite",
features_to_vary=['age','workclass','education','occupation','hours_per_week'])它还支持反映实际约束的特征的简单约束(例如,使用permitted_range参数,每周工作时间应在10到50之间)。
有关更多详细信息,请参阅此笔记本。
反事实解释的承诺
对模型的真实性,反事实解释对于机器学习模型所做的决策的所有利益相关者都有用。
决策主题:基于机器学习模型收到的决策,反事实解释可用于探索个人的可行补救措施。DiCE通过可行的替代配置文件显示决策结果,帮助人们了解他们可以做什么来改变模型的结果。
机器学习模型开发者:反事实解释对模型开发者调试模型中可能存在的问题也很有用。DiCE可以用于显示一组输入的CF解释,以揭示是否存在某些特征上的问题(依赖关系)(例如,对于95%的输入,改变特征X和Y会改变结果,但对于其他5%则不会)。我们旨在支持聚合度量,以帮助开发者调试机器学习模型。
决策者:反事实解释可能对决策者(如医生或法官)很有用,他们可能使用机器学习模型做出决策。对于特定的个人,DiCE允许调查机器学习模型,以查看可能导致不同机器学习结果的可能变化,从而使决策者能够评估他们对预测的信任。
决策评估者:最后,反事实解释对决策评估者也可能很有用,他们可能对机器学习模型的公平性或其他理想特性感兴趣。我们计划在未来添加对此的支持。
路线图
理想情况下,反事实解释应在广泛的建议更改(多样性)与采用这些更改的相对容易程度(与原始输入的接近度)之间取得平衡,并且还遵循世界的因果法则,例如,很难降低他们的教育程度或改变他们的种族。
我们正在努力为DiCE添加以下功能
支持使用DiCE调试机器学习模型
构造的英语短语(例如,如果改变特征,则期望的结果)以及其他输出反事实示例的方式
使用反事实评估特征归因方法(如LIME和SHAP)的必要性和充分性度量(见这篇论文)
支持贝叶斯优化和其他生成反事实解释的算法
改进反事实生成的可行性约束
引用
如果您认为DiCE对您的研究工作有帮助,请按照以下方式引用。
Ramaravind K. Mothilal,Amit Sharma和Chenhao Tan(2020)。通过多样化的反事实解释解释机器学习分类器。《2020年公平、问责和透明度会议论文集》。
Bibtex
@inproceedings{mothilal2020dice,
title={Explaining machine learning classifiers through diverse counterfactual explanations},
author={Mothilal, Ramaravind K and Sharma, Amit and Tan, Chenhao},
booktitle={Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency},
pages={607--617},
year={2020}
}
贡献
本项目欢迎贡献和建议。大多数贡献需要您同意贡献者许可协议(CLA),声明您有权并实际授予我们使用您的贡献的权利。有关详细信息,请访问https://cla.microsoft.com。
当您提交拉取请求时,CLA-bot将自动确定您是否需要提供CLA,并相应地装饰PR(例如,标签、注释)。只需遵循机器人提供的说明。您只需在整个使用我们的CLA的存储库中进行一次。
本项目已采用微软开源行为准则。有关更多信息,请参阅行为准则常见问题解答或通过opencode@microsoft.com提出任何额外的问题或评论。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。
源代码分发
构建分发
dice_ml-0.11.tar.gz 的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 29e6bea9e4c877caa68ecdd5d981f91cc8de3b73cdad453fd7c7e000a336576d |
|
| MD5 | 26d6b2cd38dea22cf1a1f342d21a3710 |
|
| BLAKE2b-256 | f4fc2129adcdcd6ffb771ef369b9413ca8461d76b24c203b09d306bef56fb6cf |
dice_ml-0.11-py3-none-any.whl 的散列值
| 算法 | 散列摘要 | |
|---|---|---|
| SHA256 | 9a1c199f4a0f9a865319a17f00a76c07e21c9d090e1aa10f23ea13e25e8d8455 |
|
| MD5 | bf876d652e75cdb3dade38f5f2416db1 |
|
| BLAKE2b-256 | 691cec136743072d7b4917d72d975e094c8dc9bce86920519aff97854a7dc3ce |