AutoML通信的gRPC协议。




项目描述

D3M AutoML RPC
此存储库包含使用gRPC编写的AutoML API协议规范和实现。该API允许客户端请求AutoML系统启动管道搜索过程,使用可选的管道模板,并在找到候选管道后,客户端可以请求通过管道进行评分、拟合或生成数据。
gRPC 协议规范可以自动编译成多种编程语言的实现。有关更多信息,请参阅以下内容,以及 gRPC 的 快速入门 了解详细信息。
API 结构
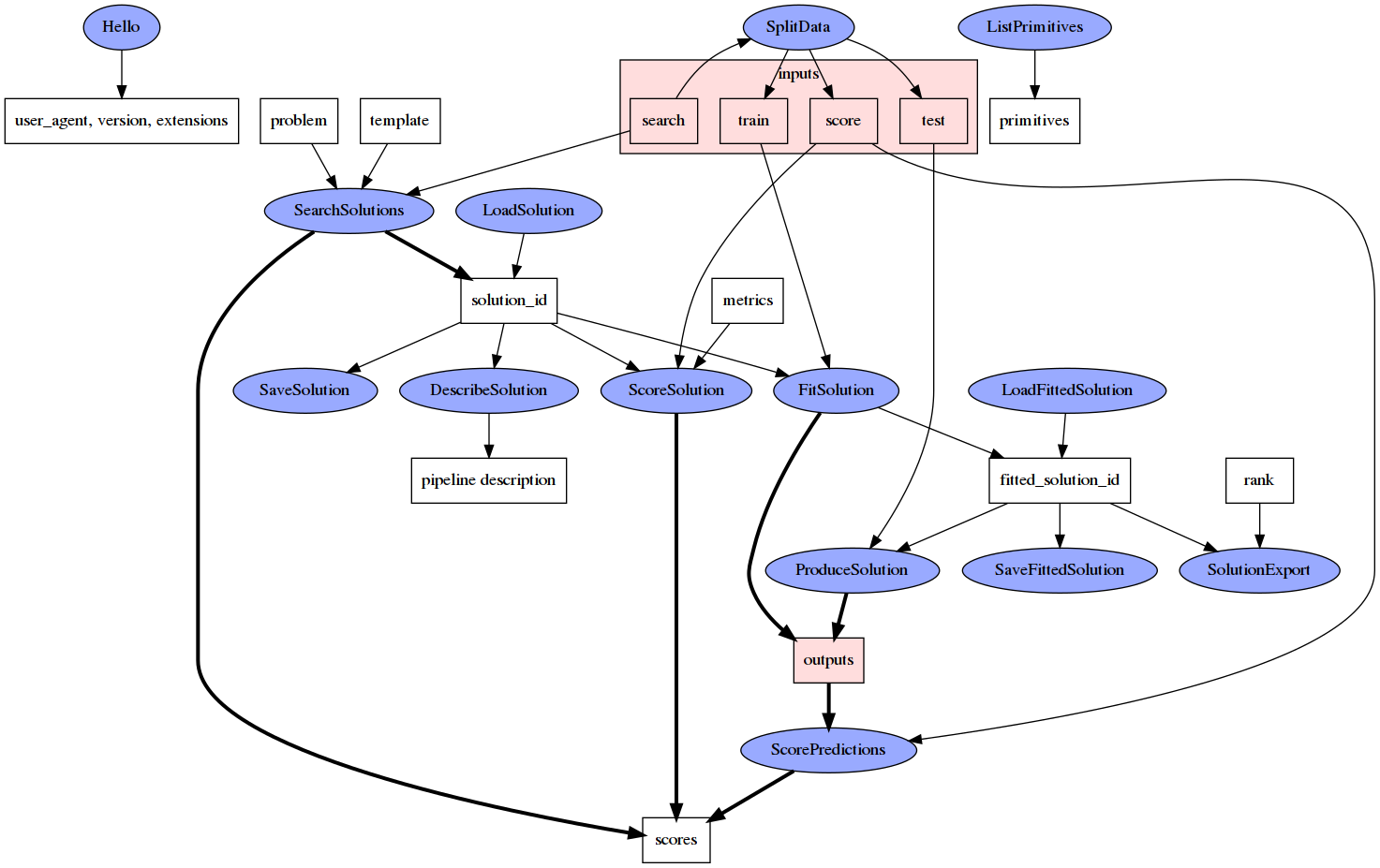
D3M AutoML RPC 调用定义在 核心 gRPC 服务中,可以在 core.proto 文件中找到,并且期望 AutoML 系统实现它并支持它。其他 .proto 文件提供了额外标准消息的定义。
在 Python 中使用 D3M AutoML API 的实用工具包含在包含的 d3m_automl_rpc 包中。
gRPC 编译
gRPC 提供了将协议规范编译成各种目标语言的工具。以下是一些示例。
Go 配置
要在 Go 中设置 gRPC 和 Protocol Buffers,请运行以下命令:
go get -u github.com/golang/protobuf/proto
go get -u github.com/golang/protobuf/protoc-gen-go
go get -u google.golang.org/grpc
接下来安装协议缓冲区编译器
Linux
curl -OL https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip
unzip protoc-3.3.0-linux-x86_64.zip -d protoc3
sudo cp protoc3/bin/protoc /usr/bin/protoc
sudo cp -r protoc3/include /usr/local
OSX
curl -OL https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-osx-x86_64.zip
unzip protoc-3.3.0-osx-x86_64.zip -d protoc3
sudo cp protoc3/bin/protoc /usr/bin/protoc
sudo cp -r protoc3/include /usr/local
编译 .proto 文件
protoc -I /usr/local/include -I . core.proto --go_out=plugins=grpc:.
生成的 core.pb.go 文件实现了消息协议、客户端和服务器。
注意:CI 流程将自动构建并发布对应于当前 master 版本的 dist-golang 分支上的相应 .go 文件,以及对应于当前 dev 版本的 dev-dist-golang 分支上的文件。这些生成的文件可以通过将 dist 分支关联的分支/提交哈希传递给 go get 命令或 go.mod 条目来包含到项目中。
Python 配置
使用 pip 安装库和工具
python -m pip install grpcio --ignore-installed
python -m pip install grpcio-tools
编译 .proto 文件
python -m grpc_tools.protoc -I . --python_out=. --grpc_python_out=. core.proto
创建的 core_pb2.py 文件实现了消息协议,而 core_pb2_grpc.py 实现了客户端和服务器。
或者,您可以安装 PyPI 上的最新版本:pip install d3m-automl-rpc
JavaScript/Node.js 配置
使用 npm 获取 gRPC 和 Protocol Buffer 包
npm install grpc
npm install google-protobuf
与 Go 安装类似,需要安装协议缓冲区编译器
Linux
curl -OL https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip
unzip protoc-3.3.0-linux-x86_64.zip -d protoc3
sudo mv protoc3/bin/protoc /usr/bin/protoc
sudo cp -r protoc3/include /usr/local
OSX
curl -OL https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-osx-x86_64.zip
unzip protoc-3.3.0-osx-x86_64.zip -d protoc3
sudo mv protoc3/bin/protoc /usr/bin/protoc
sudo cp -r protoc3/include /usr/local
编译 .proto 文件
protoc -I /usr/local/include -I . core.proto --js_out=import_style=commonjs,binary:.
生成的 core_pb.js 文件实现了消息协议、客户端和服务器。
流水线
API 围绕流水线概念。流水线使用共享的 D3M 流水线语言 描述。流水线描述用于两个地方:
- 描述提供给 AutoML 系统的流水线模板。
- 将 AutoML 系统找到的流水线描述给客户端。
通常,流水线始终以 Dataset 容器值作为输入(目前只有一个)并将预测作为输出。这是 AutoML 系统期望搜索的唯一流水线。但是,客户端可以完全指定任何流水线供 AutoML 系统执行,而无需任何搜索(包括只有一个原语的流水线)。
如果流水线具有相关的问题描述,则应适用于流水线开始处的数据。这对于部分指定的流水线尤其相关;部分指定流水线的问题描述应描述流水线开始处的数据,而不是指定部分的末尾。
流水线模板
流水线模板基于流水线描述,但有少数差异:
- 模板可以接受 多个 Dataset 容器值作为输入。
- 有一个特殊的 占位符流水线步骤,表示在流水线模板中 AutoML 系统应插入它找到的标准流水线。
- 不是流水线描述中的所有字段都是合理的(它们将由 AutoML 系统填写)。这些差异通过
pipeline.proto中的注释进行解释。
在流水线搜索过程中,占位符流水线步骤被替换为子流水线,以形成最终的流水线。
管道模板限制
虽然管道模板语言不限制占位符步骤的使用,但为了最大程度地提高客户端与AutoML系统之间的兼容性,您可能需要考虑以下限制:
- 管道模板中只能有一个占位符步骤,位于管道的最顶层(不在子管道内部)。
- 占位符步骤必须只有一个输入,即数据集容器值,以及一个输出,预测作为一个Pandas数据框。这样它类似于标准管道。
- 占位符步骤只能是管道中的最后一个步骤。
- 所有基本步骤都应该具有所有超参数固定(有关此要求,请参阅
use_default_values_for_free_hyperparams标志)。
这些限制实际上意味着管道模板只能指定一个有向无环图,该图由预处理基本步骤组成,将一个或多个输入数据集容器值转换为一个单一转换后的数据集容器值,这是占位符步骤(以及其位置的子管道)的输入。管道模板内可以使用的单个基本步骤类型没有额外限制,但在使用任何基本步骤之前,应评估其对下游AutoML系统处理的影响。
各个系统可以放宽这些限制。例如,它们可能允许在占位符步骤之后有后处理基本步骤。在这种情况下,后处理基本步骤只能将占位符步骤的预测转换成转换后的预测。或者,各个系统可能允许基本步骤具有AutoML系统应调优的自由超参数(请参阅use_default_values_for_free_hyperparams标志,可能用于控制此行为)。我们预计一些AutoML系统将能够与这些放宽的要求一起工作,如果可用,客户端可以使用这些要求,但并不期望每个AutoML系统都能这样做。
完全指定的管道
客户端还可以在SearchSolutions中提供完全指定的管道。这是一个没有占位符步骤并且所有超参数都固定的管道描述。
对于具有固定超参数的完全指定管道,AutoML系统将仅检查给定的管道是否有效,并将其返回以直接执行(评分、拟合、产生数据)。这允许在数据上执行固定计算,例如,管道可以仅由一个具有固定超参数的基本步骤组成以执行该基本步骤。此外,具有固定超参数的此类完全指定管道可以有任何输入和任何输出。(标准管道是从数据集容器值到Pandas数据框的预测。)当提供非数据集输入时,AutoML系统应尝试将输入值转换为最接近的容器类型值,例如,gRPC RAW列表值应转换为带有生成元数据的d3m.container.List,读取的CSV文件应转换为带有生成元数据的d3m.container.DataFrame。
各个系统也可以支持具有所有基本步骤指定的管道,但具有自由(可供调优)的超参数。在这种情况下,AutoML系统将仅调优超参数,并且结果管道将与给定管道具有相同的结构,但超参数配置将不同。如果不想有这种潜在的系统行为,可以将use_default_values_for_free_hyperparams标志设置为true。
值
一些消息包含可以在客户端和AutoML系统之间传递的数据值。可以通过多种方式传递这些值,并在value.proto文件中列出。
- 将简单的原始值直接放入消息中。
- 如果值是数据集容器值,则通过数据集URI进行读取或写入。
- 值还可以Python序列化并存储在URI中或在消息中直接给出。
- 如果值是一个表格容器值,它也可以存储为CSV文件。
- 值可以存储到一个共享的Plasma存储中,在这种情况下,值由其Plasma ObjectID表示。
由于不是所有系统都可以或愿意支持所有传递值的方式,并且我们可以在将来扩展它们,API通过Hello调用支持信号,哪些值类型是允许/支持的。
示例调用流程
基本管道搜索
以下是一个示例调用流程,其中客户端发起一个管道搜索请求,没有任何预处理或后处理,AutoML系统通过一系列流式响应返回两个管道。每个管道的响应都使用一个gRPC流传输,可以交错。然后客户端请求其中一个的分数。
sequenceDiagram
participant Client
participant ScoreSolution
participant SearchSolutions
Client->>SearchSolutions: SearchSolutionsRequest
SearchSolutions-->>Client: SearchSolutionsResponse { search_id = 057cf5... }
Client->>+SearchSolutions: GetSearchSolutionsResults(GetSearchSolutionsResultsRequest)
SearchSolutions-->>Client: GetSearchSolutionsResultsResponse { solution_id = a5d78d... }
SearchSolutions-->>Client: GetSearchSolutionsResultsResponse { solution_id = b6d5e2... }
Client->>ScoreSolution: ScoreSolutionRequest { a5d78d... }
ScoreSolution-->>Client: ScoreSolutionResponse { request_id = 1d9193... }
Client->>+ScoreSolution: GetScoreSolutionResults(GetScoreSolutionResultsRequest)
ScoreSolution-->>Client: ScoreSolutionResultsResponse { progress = PENDING }
ScoreSolution-->>Client: ScoreSolutionResultsResponse { progress = RUNNING }
ScoreSolution-->>Client: ScoreSolutionResultsResponse { progress = COMPLETED, scores }
ScoreSolution-->>-Client: (ScoreSolution stream ends)
Client->>SearchSolutions: EndSearchSolutions(EndSearchSolutionsRequest)
SearchSolutions-->>Client: EndSearchSolutionsResponse
SearchSolutions-->>-Client: (GetFoundSolutions stream ends)
1. Client: SearchSolutions(SearchSolutionsRequest) // problem = {...}, template = {...}, inputs = [dataset_uri]
2. Server: SearchSolutionsResponse // search_id = 057cf581-5d5e-48b2-8867-db72e7d1381d
3. Client: GetSearchSolutionsResults(GetSearchSolutionsResultsRequest) // search_id = 057cf581-5d5e-48b2-8867-db72e7d1381d
[SEARCH SOLUTIONS STREAM BEGINS]
4. Server: GetSearchSolutionsResultsResponse // progress = PENDING
5. Server: GetSearchSolutionsResultsResponse // progress = RUNNING, solution_id = 5b08f87a-8393-4fa4-95be-91a3e587fe54, internal_score = 0.6, done_ticks = 0.5, all_ticks = 1.0
6. Server: GetSearchSolutionsResultsResponse // progress = RUNNING, solution_id = 95de692f-ea81-4e7a-bef3-c01f18281bc0, internal_score = 0.8, done_ticks = 1.0, all_ticks = 1.0
7. Server: GetSearchSolutionsResultsResponse // progress = COMPLETED
[SEARCH SOLUTIONS STREAM ENDS]
8. Client: ScoreSolution(ScoreSolutionRequest) // solution_id = 95de692f-ea81-4e7a-bef3-c01f18281bc0, inputs = [dataset_uri], performance_metrics = [ACCURACY]
9. Server: ScoreSolutionResponse // request_id = 5d919354-4bd3-4155-9295-406d8c02b915
10. Client: GetScoreSolutionResults(GetScoreSolutionResultsRequest) // request_id = 5d919354-4bd3-4155-9295-406d8c02b915
[SCORE SOLUTION STREAM BEGINS]
11. Server: GetScoreSolutionResultsResponse // progress = PENDING
12. Server: GetScoreSolutionResultsResponse // progress = RUNNING
13. Server: GetScoreSolutionResultsResponse // progress = COMPLETED, scores = [0.9]
[SCORE SOLUTION STREAM END]
14. Client: EndSearchSolutions(EndSearchSolutionsRequest) // search_id = 057cf581-5d5e-48b2-8867-db72e7d1381d
15. Server: EndSearchSolutionsResponse
原语透传执行
对于客户端在一个数据集上调用一个原语并将转换后的数据集存储到Plasma存储中,以便使用内存共享高效地访问它并显示给用户的示例调用流程。即使原语只是一个转换并且不需要拟合,客户端也必须拟合一个解决方案才能调用produce。
这个示例的输入数据集和输出数据集是相同的。这与常规管道不同,常规管道以数据集为输入并产生预测作为输出。原因在于管道是由客户端完全指定的,因此输入和输出可以是任何东西。
1. Client: SearchSolutions(SearchSolutionsRequest) // problem = {...}, template = {...}, inputs = [dataset_uri]
2. Server: SearchSolutionsResponse // search_id = ae4de7f4-4435-4d86-834b-c183ef85f2d0
3. Client: GetSearchSolutionsResults(GetSearchSolutionsResultsRequest) // search_id = ae4de7f4-4435-4d86-834b-c183ef85f2d0
[SEARCH SOLUTIONS STREAM BEGINS]
4. Server: GetSearchSolutionsResultsResponse // progress = PENDING
5. Server: GetSearchSolutionsResultsResponse // progress = RUNNING, solution_id = 619e09ee-ccf5-4bd2-935d-41094169b0c5, internal_score = NaN, done_ticks = 1.0, all_ticks = 1.0
6. Server: GetSearchSolutionsResultsResponse // progress = COMPLETED
[SEARCH SOLUTIONS STREAM ENDS]
7. Client: FitSolution(FitSolutionRequest) // solution_id = 619e09ee-ccf5-4bd2-935d-41094169b0c5, inputs = [dataset_uri]
8. Server: FitSolutionResponse // request_id = e7fe4ef7-8b3a-4365-9fc4-c1a8228c509c
9. Client: GetFitSolutionResults(GetFitSolutionResultsRequest) // request_id = e7fe4ef7-8b3a-4365-9fc4-c1a8228c509c
[FIT SOLUTION STREAM BEGINS]
10. Server: GetFitSolutionResultsResponse // progress = PENDING
11. Server: GetFitSolutionResultsResponse // progress = RUNNING
12. Server: GetFitSolutionResultsResponse // progress = COMPLETED, fitted_solution_id = 88d627a4-e4ca-4b1a-9f2e-af9c54dfa860
[FIT SOLUTION STREAM END]
13. Client: ProduceSolution(ProduceSolutionRequest) // fitted_solution_id = 88d627a4-e4ca-4b1a-9f2e-af9c54dfa860, inputs = [dataset_uri], expose_outputs = ["outputs.0"], expose_value_types = [PLASMA_ID]
14. Server: ProduceSolutionResponse // request_id = 954b19cc-13d4-4c2a-a98f-8c15498014ac
15. Client: GetProduceSolutionResults(GetProduceSolutionResultsRequest) // request_id = 954b19cc-13d4-4c2a-a98f-8c15498014ac
[PRODUCE SOLUTION STREAM BEGINS]
16. Server: GetProduceSolutionResultsResponse // progress = PENDING
17. Server: GetProduceSolutionResultsResponse // progress = RUNNING, steps = [progress = PENDING]
18. Server: GetProduceSolutionResultsResponse // progress = RUNNING, steps = [progress = RUNNING]
19. Server: GetProduceSolutionResultsResponse // progress = RUNNING, steps = [progress = COMPLETED]
20. Server: GetProduceSolutionResultsResponse // progress = COMPLETED, steps = [progress = COMPLETED], exposed_outputs = {"outputs.0": ObjectID(6811fc1154520d677d58b01a51b47036d5a408a8)}
[PRODUCE SOLUTION STREAM END]
21. Client: EndSearchSolutions(EndSearchSolutionsRequest) // search_id = ae4de7f4-4435-4d86-834b-c183ef85f2d0
22. Server: EndSearchSolutionsResponse
上面使用的template可能看起来像(消息以JSON显示)
{
"inputs": [
{
"name": "dataset"
}
],
"outputs": [
{
"name": "dataset",
"data": "step.0.produce"
}
],
"steps": [
{
"primitive": {
"id": "f5c2f905-b694-4cf9-b8c3-7cd7cf8d6acf"
},
"arguments": {
"inputs": {
"data": "inputs.0"
}
},
"outputs": [
{
"id": "produce"
}
]
}
]
}
标准端口
D3M AutoML API的标准端口是45042,AutoML系统应该在该端口上监听连接。
如果存在,TA2系统将读取D3MPORT环境变量并监听该端口。
协议版本
为了支持更容易的调试,SearchSolutionsRequest和SearchSolutionsResponse消息包含每个方使用的协议版本。这可以通过检测版本不匹配来更容易地理解潜在问题。
为了使其生效,version字段必须从协议规范本身存储的值中填充。我们为此使用自定义选项。要从中检索版本,您可以在Python中执行以下操作
import core_pb2
version = core_pb2.DESCRIPTOR.GetOptions().Extensions[core_pb2.protocol_version]
在Go中,访问版本稍微复杂一些,相关描述在此。
消息的扩展
gRPC和Protocol Buffers支持一种简单的扩展消息的方法:只需在您的本地协议版本中定义具有自定义标签的额外字段。使用此协议的用户可以这样做以尝试协议的不同变体(如果更改有效,他们可以提交一个合并请求,将这些更改包括到本规范中)。为了确保消息中此类非官方字段之间不会发生冲突,请使用来自分配的标签范围的值,或者通过合并请求添加您的组织。
变更日志
有关API更改的总结,请参阅HISTORY.md。
仓库结构
master分支包含D3M AutoML RPC API规范的最新稳定版本。devel分支是下一个版本的测试分支。
发布被标记。
在向master和devel分支提交的每个提交中,我们编译.proto文件并将编译后的文件推送到为多种语言创建的dist-*和dev-dist-*分支。您可以直接使用这些分支中的任何一个,在项目中使用git submodule或其他类似机制。
贡献
有关如何为API开发做出贡献的更多信息,请参阅贡献指南。
关于数据驱动发现计划
DARPA 数据驱动发现(D3M)项目正在研究使机器能够自动构建机器学习管道的方法。该项目分为三层:TA1(基本操作),TA2(将基本操作自动组合成管道并执行的系统),以及TA3(终端用户界面)。


下载文件
下载适合您平台的文件。如果您不确定选择哪个,请了解有关安装包的更多信息。
源分布
构建分布
d3m-automl-rpc-1.2.4.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 3720822b6cd73a84ad4667349e8cb103d6ef84cf435f4dd1c529908b2f38f5f7 |
|
| MD5 | 341b718c68711b583b6a89fc50aad099 |
|
| BLAKE2b-256 | ff2aee3002388720a1cf0c2027506d0675554a5a0ba3a870d2edca95a56dfb16 |
d3m_automl_rpc-1.2.4-py3-none-any.whl 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 1ad38727509a96ace32c688cd3506b0eb3509744447530381598adbdbe838b22 |
|
| MD5 | 35f5635a799bcebad3fcf094dae37465 |
|
| BLAKE2b-256 | 62cf7db317ddb1d10dbc4ee201a1c66d309948de34c1268070a9b58e947375d5 |