功能强大且易于使用的通用dicoms匿名化工具,通过散列ID对人口统计数据csv电子表格进行匿名化

项目描述



这个dicoms匿名化/假名化工具是为了让作为数据分享的临床医生的生活更加简单而制作的。
第一个目标是删除患者的姓名,并在dicoms和人口统计数据csv文件中用假名替换,但它还负责通过可配置的黑名单删除其他可能包含可识别信息的结构,例如字段(例如,患者的电话号码)和文件(pdf,txt,csv等)。
它运行在Python 2.7下(它没有针对Python 3的兼容性进行测试或开发,尽管它可能通过一些轻微的修改而工作)。
这是一个强调的通用dicoms假名化工具
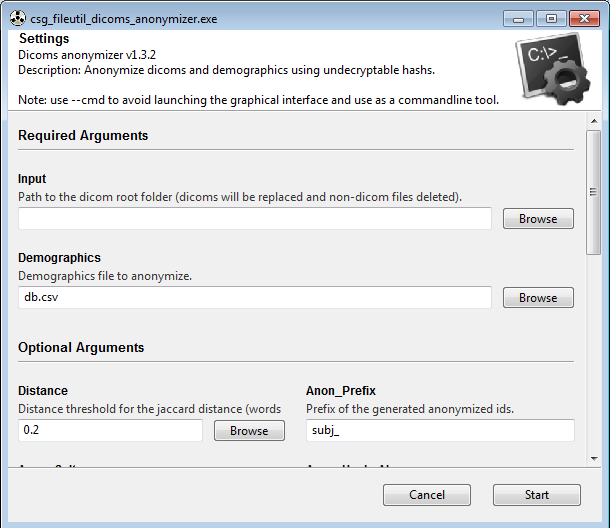
易用性:只需指向包含所有您的 dicom(文件夹或 zip 文件)的文件夹和人口统计文件(只需确保您有一个“姓名”列),然后点击“开始”!注意,您也可以在命令行中使用它,允许批量脚本。
易于匿名化人口统计信息:模糊匹配算法将处理小错误和名/姓的颠倒(即使有多个名或姓也能正常工作)。最后,将生成几个 csv 文件:仅包含 dicom 中的患者的匿名化人口统计信息(这样您就可以重用所有受试者的庞大人口统计电子表格,即使只是匿名化少数受试者,缩短的匿名化人口统计信息也仅包含相关受试者),dicom 中但不在人口统计信息中的缺失受试者列表(以便您的接收者可以直接知道哪些人口统计信息不可用),以及将匿名化 ID 转换为原始患者姓名的映射(如果您的研究合作者要求有关匿名化患者的额外信息,或只是检查是否存在问题,这将很有用)。
保留 dicom 中的潜在相关信息:此应用程序不是匿名化所有个人信息字段,而是仅匿名化姓名(并去除一些其他个人信息,如电话号码、患者地址等),但不是所有个人信息字段。因此,匿名化的 dicom 将保留年龄、性别、扫描日期、出生日期等,这些可以用作回归协变量或用于将患者聚类在一起。可以轻松添加其他要删除的字段作为参数。
可靠性:使用基于字符错误的标准化 levenshstein 距离和基于单词切换/缺失的修改后规范化 words jaccard 距离的模糊匹配,即使存在多个错误或缺失的首字母,也能正确匿名化并关联到正确的人口统计信息条目。在任何情况下,如果在人口统计信息中找不到类似的名字,它将被替换为假名并添加到映射中。
鲁棒性:所有其他 dicom 匿名化工具仅在 PatientName 字段中查找姓名。然而,还有其他隐藏字段可能包含患者姓名,并且这因每台机器、每个中心、每个扫描仪的参数设置而异。此应用程序将稳健地找到包含患者姓名的所有字段,并尝试删除它而不会影响字段的其他部分(可能包含关键技术数据),并在继续之前始终检查姓名是否从整个 dicom 中清除。如果由于任何原因患者姓名仍然存在,匿名化工具将停止并显示错误消息,以便您可以采取适当的措施。
确定性的单向加密:假名的生成方式可以防止任何回溯,同时给定相同的患者姓名始终生成相同的假名。这是通过使用具有可定制盐的加密散列函数实现的:只要您使用特定于您组织的盐字符串,没有此盐的人将无法在没有此应用程序生成的映射的情况下追踪数据,即使他们拥有患者姓名的登记簿。
使用方法
要使用此应用程序,您必须指向一个文件夹,其中每个子文件夹都是一个患者的 dicom 会话。如果是为了同一位患者,您可以在其中放置多个 dicom 会话。这是因为脚本假定每个文件夹只有一个患者(以查找姓名,否则查看所有 dicom 文件将过于昂贵)。
可选地,您可以提供 csv 格式的人口统计文件,以与 dicom 一起匿名化,并使用相同的假名。此 csv 文件必须至少包含一个“姓名”列,其中包含所有患者的姓名。由于将进行模糊匹配,因此错误和单词顺序无关紧要。然而,请注意,如果某些名字太相似,或者有太多错误或缺失的中间名,则模糊匹配可能无法正确工作。可以通过“dist_threshold”参数调整模糊匹配。
最后,有多个附加选项可以进一步优化匿名化的效率。例如,存在用于删除可能包含可识别信息的文件类型(如pdf、csv、txt等)的黑名单,这些信息可能是实验者的遗留信息,以及用于完全删除(如PatientPhoneNumber)的dicom字段黑名单。
此应用程序可以与GUI或命令行相互切换,将提供相同的功能和选项。
另一个有趣的功能是,您可以在匿名化数据集的基础上构建,您可以添加新的受试者。实际上,每个受试者都会根据名称(默认)或使用适当的选项按文件夹中的顺序获得一个唯一的ID,这使得在任何情况下都不可能从ID翻译回原始名称。
关于法规的注意事项:匿名化与脱敏
此工具的目标是对数据进行脱敏,而不是根据法规进行匿名化。这种差异很重要:将保留私人字段(除非您指定要删除的字段列表),但患者姓名将被匿名化,使通过姓名识别变得不可能(即使在获取受试者姓名的情况下,没有映射也无法追溯人口统计学和dicom文件)。这对于研究很重要,因为私人字段包含重要信息(扫描切片时间参数、患者年龄和性别等)。
如果您想进行完全匿名化(即删除/修改所有私人字段),请查看dicom-anon,这是一个Python dicoms匿名化工具,具有可配置的规范。还可以查看pydicom示例匿名化器和MATLAB的dicomanon命令。然而,请注意,这并不足以进行完全匿名化,因为您还需要进行去脸操作(请注意,这可能会使统计预处理和分析变得困难)。
待办事项
此应用程序以当前的形式提供,希望它对其他人有所帮助。在作为独立GUI应用程序运行和打包为最小二进制文件之前,没有对其进行过多的清理。
考虑到这一点,以下应做以使此应用程序成为一个合适的软件
使人口统计学文件可选。在代码中,人口统计学文件对于匿名化dicoms并不是真正必要的,一个只包含‘name’列的空csv文件就足够了。但如果它是可选的并且处理得当会更好。
使dicoms可选(输入一个空的dicoms文件夹),以便即使没有dicoms文件,人口统计学文件也可以进行匿名化。
允许重用匿名化表(查找类似名称并分配相同的哈希值)。
重构代码:将函数放在代码上方,删除来自Jupyter导出的无用注释(# []),将一些代码片段移动到函数中。
使用requirements而不是在csg_fileutil_libs中集成子模块。
使用随机生成的dicoms进行单元测试。
许可协议
CSG dicoms匿名器最初由Stephen Larroque <LRQ3000>为Coma Science Group - GIGA Consciousness - CHU de Liege,比利时创建。应用程序许可协议为MIT许可。


csg_dicoms_anonymizer-1.4.2.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | e2a7ab3e31fee35b2c1b120a8fb5929899c503415599d74bfffbaefaa020cd7d |
|
| MD5 | 591e27e942956d73d5a951b41027e03b |
|
| BLAKE2b-256 | e59777c4d438151113cf2b970e9252588740dc4da5d4eb706b83c2d3026a0626 |