CREPE音高跟踪器


项目描述
CREPE音高跟踪器





CREPE是一个基于深度卷积神经网络的单一音高跟踪器,它直接在时域波形输入上操作。CREPE(截至2018年)是业界领先的技术,优于pYIN和SWIPE等流行的音高跟踪器
以下论文提供了更多详细信息
CREPE:音高估计的卷积表示
Jong Wook Kim, Justin Salamon, Peter Li, Juan Pablo Bello.
2018年IEEE国际语音、语音和信号处理会议(ICASSP)论文集。
我们请求使用CREPE的学术出版物引用上述论文。
安装CREPE
CREPE托管在PyPI上。要安装,请在您的Python环境中运行以下命令
$ pip install --upgrade tensorflow # if you don't already have tensorflow >= 2.0.0
$ pip install crepe
要从源安装最新版本,克隆存储库,然后在顶层 crepe 文件夹中调用
$ python setup.py install
使用CREPE
使用命令行中的CREPE
此包包括一个命令行实用程序 crepe 和一个预训练的CREPE模型,便于使用。要估计 audio_file.wav 的音高,运行
$ crepe audio_file.wav
或
$ python -m crepe audio_file.wav
生成的audio_file.f0.csv包含3列:第一列是时间戳(默认使用10毫秒的跳变大小),第二列包含预测的基频(单位为Hz),第三列包含音色置信度,即对存在音高的置信度。
time,frequency,confidence
0.00,185.616,0.907112
0.01,186.764,0.844488
0.02,188.356,0.798015
0.03,190.610,0.746729
0.04,192.952,0.771268
0.05,195.191,0.859440
0.06,196.541,0.864447
0.07,197.809,0.827441
0.08,199.678,0.775208
...
时间戳
CREPE默认使用10毫秒的时间步长,可以通过--step-size选项进行调整,该选项接受毫秒为单位的时间步长大小。例如,--step-size 50将在每50毫秒计算一次音高。
遵循流行音频处理库(如Essentia和Librosa)的惯例,从v0.0.5版本开始,CREPE将对输入信号进行填充,使得第一个帧是零中心(帧的中心对应时间为0),并且通常所有帧都围绕其对应的时间戳进行中心化,即帧D[:, t]中心在audio[t * hop_length]。可以通过指定可选的--no-centering标志来改变这种行为,在这种情况下,第一个帧将开始于时间零,并且通常帧D[:, t]将开始于audio[t * hop_length]。强烈建议坚持默认行为(中心化帧)以避免与其他常见音频处理工具生成的特征和注释对齐。
模型容量
CREPE默认使用论文中报告的模型大小,但可以选择使用更小的模型以提高计算速度,这会略微降低准确性。可以通过命令行选项--model-capacity {tiny|small|medium|large|full}指定所需容量的模型。
时间平滑
默认情况下,CREPE不对音高曲线应用时间平滑,但通过可选的--viterbi命令行参数支持维特比平滑。
保存激活矩阵
脚本还可以可选地将模型的输出激活矩阵保存到npy文件中(使用--save-activation),矩阵维度为(n_frames,360),使用10毫秒的跳变大小(有360个音高bin,每个覆盖20分贝)。
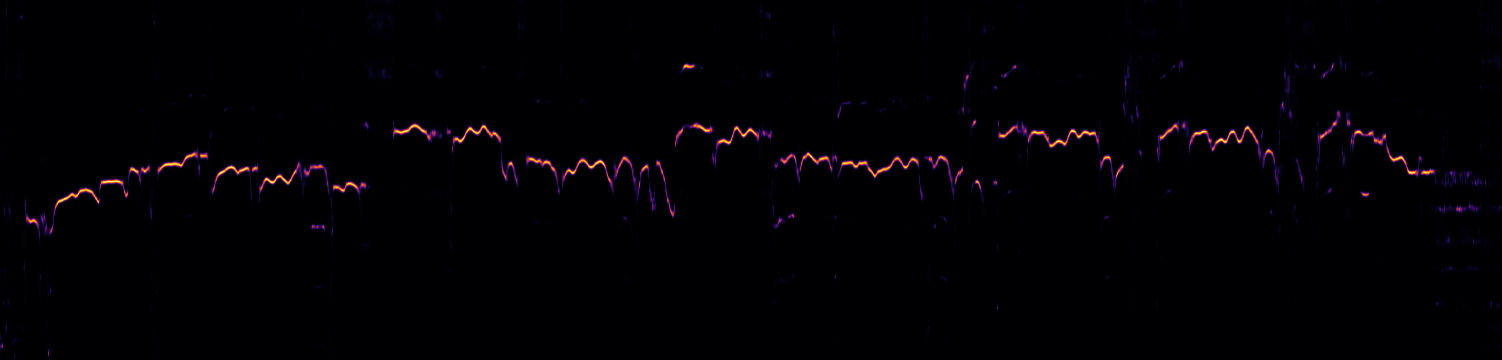
脚本还可以输出激活矩阵的图形(使用--save-plot),保存到audio_file.activation.png,包括模型音色检测的可选视觉表示(使用--plot-voicing)。以下是一个激活矩阵的示例图(无音色叠加)
批量处理
对于文件的批量处理,您可以提供文件夹路径而不是文件路径
$ python crepe.py audio_folder
脚本将处理文件夹中找到的所有WAV文件。
其他使用信息
有关使用方法的更多信息,请参阅帮助信息
$ python crepe.py --help
在Python中使用CREPE
CREPE可以作为模块导入到Python中使用。以下是一个最小示例
import crepe
from scipy.io import wavfile
sr, audio = wavfile.read('/path/to/audiofile.wav')
time, frequency, confidence, activation = crepe.predict(audio, sr, viterbi=True)
Argmax局部加权平均
CREPE的此版本使用以下加权平均公式,该公式与论文略有不同。这仅关注最大激活周围的邻域,已被证明可以进一步提高音高准确性
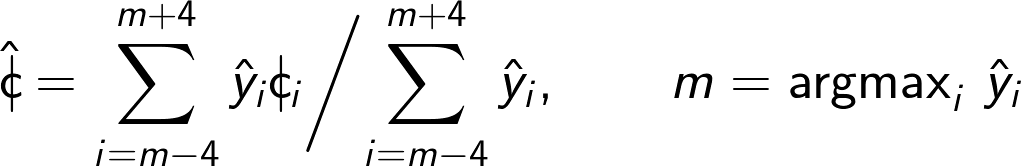
请注意
- 当前版本仅支持WAV文件作为输入。
- 模型在16 kHz音频上训练,因此如果输入音频的采样率不同,它将首先使用resampy重新采样到16 kHz。
- 由于框架之间的细微数值差异,建议将Keras配置为使用TensorFlow后端以获得最佳性能。该模型使用Keras 2.1.5和TensorFlow 1.6.0进行训练,并且TensorFlow的新版本似乎也可以正常工作。
- 如果Keras(以及相应的后端)配置为在GPU上运行,则预测速度将显著提高。
- 所提供的模型使用以下数据集进行训练,这些数据集包括声乐和乐器音频,因此预计在此类音频信号上表现最佳。
- MIR-1K [1]
- Bach10 [2]
- RWC-Synth [3]
- MedleyDB [4]
- MDB-STEM-Synth [5]
- NSynth [6]
参考文献
[1] C.-L. Hsu 等人. "使用 MIR-1K 数据集改进单声道录音的歌唱声音分离",《IEEE 信号处理、音频和语言处理汇刊》。2009。
[2] Z. Duan 等人. "通过建模频谱峰值和非峰值区域进行多个基频估计",《IEEE 信号处理、音频和语言处理汇刊》。2010。
[3] M. Mauch 等人. "pYIN:使用概率阈值分布的基本频率估计器",《IEEE 国际声学、语音和信号处理会议论文集 (ICASSP)》。2014。
[4] R. M. Bittner 等人. "MedleyDB:用于音乐信息检索 (MIR) 研究的注释密集型多轨数据集",《国际音乐信息检索协会 (ISMIR) 会议论文集》。2014。
[5] J. Salamon 等人. "用于多轨数据集自动 F0 注释的分析/合成框架",《国际音乐信息检索协会 (ISMIR) 会议论文集》。2017。
[6] J. Engel 等人. "使用 WaveNet 自动编码器进行音乐音符的神经音频合成",《arXiv 预印本:1704.01279》。2017。


crepe-0.0.16.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 521c80a062a6e5ca52c5e1077e1bf59d89e46811ee2298b5a8153e9736d29631 |
|
| MD5 | 249749889a0094804679e24486e70b4f |
|
| BLAKE2b-256 | b309e43fac5dd0e2805309f7ee32634d00a355cf58cdcc94b576e79ffd535ef3 |