compressio


项目描述

Compressio
Compressio提供由visions类型系统支持的pandas DataFrames和Series的无损内存压缩。使用相同的数据,可节省高达10倍的内存!
入门非常简单:
from compressio import Compress
compress = Compress()
compressed_data = compress.it(data)
框架
Compressio是一个通用的自动化数据压缩和表示管理框架,不仅限于任何特定的压缩算法或实现。您拥有完全的控制权,可以定义自己的类型,编写自己的压缩算法,或者从visions提供的庞大类型库和Compressio默认包含的强大算法套件开始。
这些算法可以根据以下三个基本的优化策略进一步细分
- 尽可能选择信息无损的小数据类型
- 考虑(更高效的)数据表示
- 使用更高效的数据结构压缩数据
* 这是visions之外事情变得复杂的地方
1. 更小的数据类型
在内部,pandas 使用 NumPy 数组来存储数据。每个 NumPy 数组都有一个相关的 dtype,用于指定数据的物理、磁盘上的表示形式。例如,一个整数序列可能存储为 64 位整数(int64)、8 位无符号整数(uint8)或甚至 32 位浮点数(float32)。可以在 此处 找到 NumPy 类型系统的概述。
这些类型差异具有许多计算影响,例如,8 位整数可以表示 0 到 255 之间的数字,而 64 位整数的范围在 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 之间,但代价是内存占用增加 8 倍。不同大小也可能对计算性能产生影响。
import numpy as np
array_int_64 = np.ones((1000, 1000), dtype=np.int64)
print(array_int_64.nbytes)
8000000
array_int_8 = np.ones((1000, 1000), dtype=np.int8)
print(array_int_8.nbytes)
1000000
正如您所看到的,8 位整数数组将内存使用量减少了 87.5%。
2. 适当的机器表示
Compressio 使用 visions 来推断数据的语义类型,并将其强制转换为替代计算表示形式,以最小化内存影响同时保持其语义意义。
例如,虽然 pandas 可以使用通用的对象 dtype 存储布尔序列,但这会付出 4 倍内存占用的代价。Visions 可以自动处理这些情况以找到适合您数据的相关表示。
>>>> import pandas as pd
>>>> # dtype: object
>>>> series = pd.Series([True, False, None, None, None, None, True, False] * 1000)
>>>> print(series.nbytes)
64000
>>>> # dtype: boolean (pandas' nullable boolean)
>>>> new_series = series.astype("boolean")
>>>> print(new_series.nbytes)
16000
有关更多信息,请参阅 visions 文档、github 仓库 和 JOSS 出版物。
3. 高效的数据结构
如果没有额外的指令,pandas 将您的数据表示为 密集型 数组。这是一个全面的良好选择。
当您的数据不是随机分布时,它可以被压缩(理论)。
低基数数据通常可以使用 pandas 默认提供的 稀疏数据结构 存储得更加高效,这些结构通过只存储主要值一次并保留所有其他值的索引来提供效率。
这个笔记本 展示了如何使用 compressio 与稀疏数据结构一起使用。
数据结构优化不仅限于稀疏数组,还包括许多特定领域的机遇,例如可以应用于压缩顺序数据的 运行长度编码(RLE)。我们注意到,目前正在进行 pandas 特定的第三方实现:RLEArray。
使用方法
安装
您可以使用 pip 轻松安装 compressio
pip install compressio
或者,从源代码安装。
git clone https://github.com/dylan-profiler/compressio.git
示例
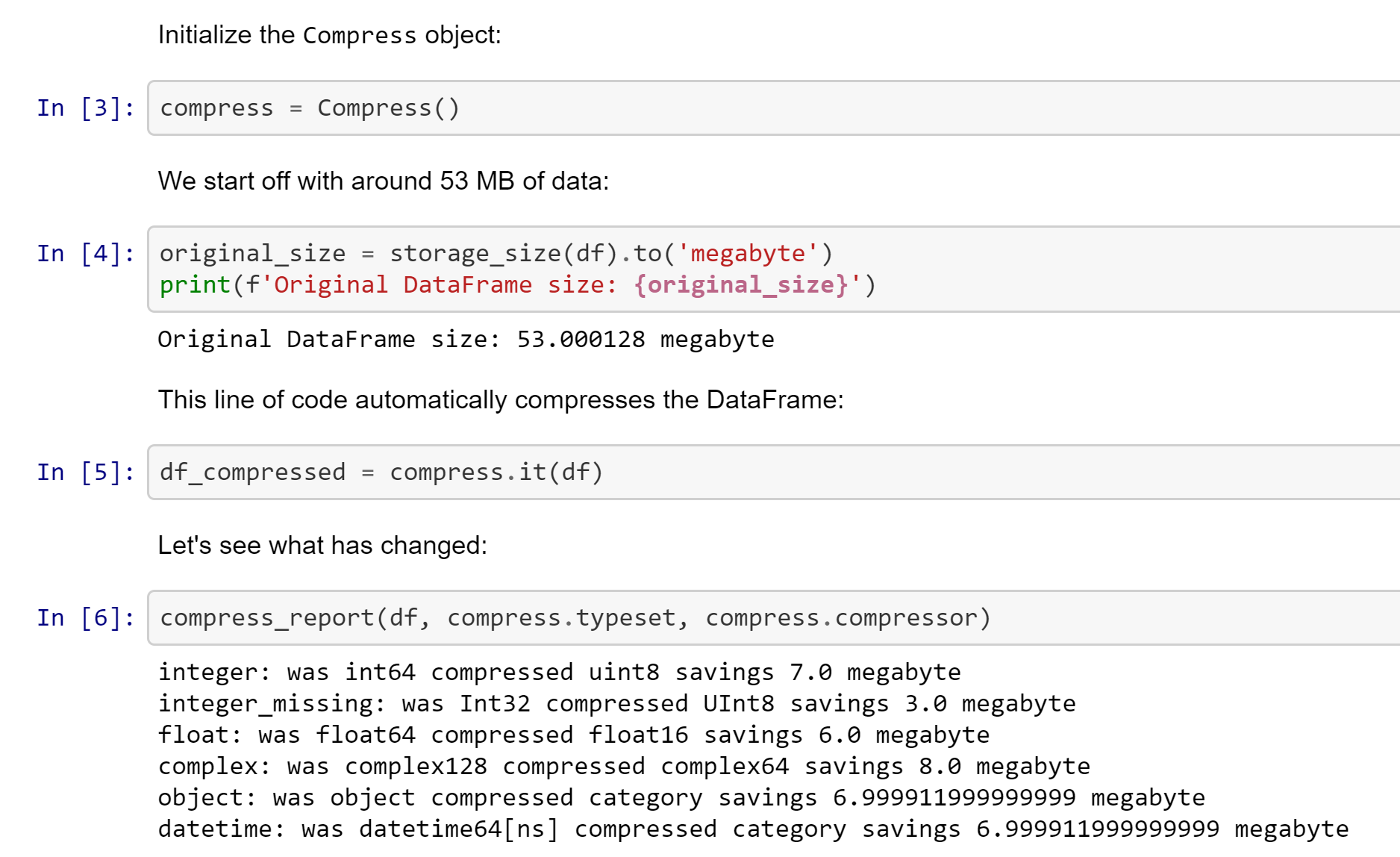
在 示例目录 中有一系列示例笔记本可以用来玩耍,以及一个快速入门笔记本可供 在此 使用。
优化 pandas 中的字符串
Pandas 允许以多种方式存储字符串:作为字符串对象或作为 pandas.Category。pandas 的最新版本有一个 pandas.String 类型。
您在 pandas 中如何存储字符串可以显著影响所需的 RAM。
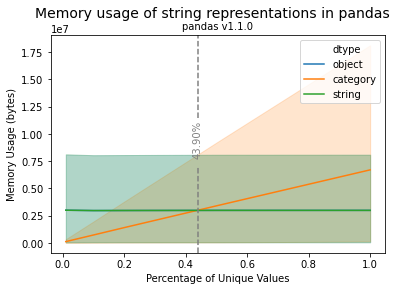
此分析的关键见解是
- 当值重复时,Category 比 String 表示形式更节省内存;String 表示形式的百分比是不同值的数量。
- Series 的大小对于字符串表示形式的选择 不是 决定性的。
您可以在 此处 找到完整分析。
注意事项
压缩 DataFrame 在许多情况下可能很有帮助,但并非所有情况都适用。请注意以下情况下的应用方式


下载文件
下载您平台上的文件。如果您不确定选择哪个,请了解有关 安装包 的更多信息。
源分布
构建分布
compressio-0.1.4.tar.gz 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | 1f174e2b40ccf7c5681de37532d9535e04d296f3ce8a9f836d02d0957490421e |
|
| MD5 | 72415763e3ba5fb398bedec5f44f3444 |
|
| BLAKE2b-256 | 412be6991b1bb9be16d077459ae73d457701ac1c234542b7cfabadba022f2d43 |
compressio-0.1.4-py3-none-any.whl 的哈希值
| 算法 | 哈希摘要 | |
|---|---|---|
| SHA256 | c8b5a0b548c21f257e21f5e9a23b04247b7873e15a8dce83177ae157fc79b862 |
|
| MD5 | fe73f290f75bf3a3071d77d546539b71 |
|
| BLAKE2b-256 | b70f55ee14a82d2e37c6cebaae1ac1d480949791264b4e9fb9609eb899197b29 |







